 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Pathway Geometry-Aware MLLM for Spatial Intelligence
May 25, 2026Spatial understanding of the physical world from 2D visual inputs hinges on two complementary forms of geometric knowledge: holistic 3D structural perception and fine-grained metric scale estimation. Existing multimodal large language models (MLLMs) typically address only one facet, ingesting either depth maps or point clouds as additional model inputs, which incurs substantial computational overhead and inherits the generalization limitations of upstream prediction models. We propose GAMSI, a dual-pathway Geometry-Aware MLLM for Spatial Intelligence that takes only RGB images as input while internalizing both forms of geometric prior within a unified autoregressive backbone. Specifically, we introduce Metric-Structure Decoupled Queries (MSDQ) which employ two groups of learnable queries to respectively extract dense metric signals and sparse structural cues from the shared visual context, with a task-decoupled attention mask further preventing the two pathways from contaminating each other. Building on this, an Expert-Guided Visual Grounding (EVG) module projects the aggregated cues back to frame-level visual features and aligns them with vision foundation models, which serve purely as training-time supervision, rather than as model inputs. We further build a multi-task spatial instruction-tuning dataset (MTS) comprising 152{,}776 samples spanning 13 task types and three visual modalities, consolidated from six public datasets. Trained with a two-stage curriculum, GAMSI achieves state-of-the-art performance on seven spatial intelligence benchmarks.
Self-Consistent Latent Reasoning: Long Latent Sequence Reasoning for Vision-Language Model
May 13, 2026In language reasoning, longer chains of thought consistently yield better performance, which naturally suggests that visual latent reasoning may likewise benefit from longer latent sequences. However, we discover a counterintuitive phenomenon: the performance of existing latent visual reasoning methods systematically degrades as the latent sequence grows longer. We reveal the root cause: Information Gain Collapse -- autoregressive generation makes each step highly dependent on prior outputs, so subsequent tokens can barely introduce new information. We further identify that heavily pooled ($\geq 128\times$) image embeddings used as supervision targets provide no more signal than meaningless placeholders. Motivated by these insights, we propose SCOLAR (Self-COnsistent LAtent Reasoning), which introduces a lightweight detransformer that leverages the LLM's full-sequence hidden states to generate auxiliary visual tokens in a single shot, with each token independently anchored to the original visual space. Combined with three-stage SFT and ALPO reinforcement learning, SCOLAR extends acceptable latent CoT length by over $30\times$, achieves state-of-the-art among open-source models on real-world reasoning benchmarks (+14.12% over backbone), and demonstrates strong out-of-distribution generalization.
When to Think, When to Speak: Learning Disclosure Policies for LLM Reasoning
May 05, 2026In single-stream autoregressive interfaces, the same tokens both update the model state and constitute an irreversible public commitment. This coupling creates a \emph{silence tax}: additional deliberation postpones the first \emph{task-relevant} content, while naive early streaming risks premature commitments that bias subsequent generations. We introduce \textbf{\emph{Side-by-Side (SxS)}} Interleaved Reasoning, which makes \emph{disclosure timing} a controllable decision within standard autoregressive generation. SxS interleaves partial disclosures with continued private reasoning in the same context, but releases content only when it is \emph{supported} by the reasoning so far. To learn such pacing without incentivizing filler, we construct entailment-aligned interleaved trajectories by matching answer prefixes to supporting reasoning prefixes, then train with SFT to acquire the dual-action semantics and RL to recover reasoning performance under the new format. Across two Qwen3 architectures/scales (MoE \textbf{Qwen3-30B-A3B}, dense \textbf{Qwen3-4B}) and both in-domain (AIME25) and out-of-domain (GPQA-Diamond) benchmarks, SxS improves accuracy--\emph{content-latency} Pareto trade-offs under token-level proxies (e.g., inter-update waiting).
StreamingClaw Technical Report
Mar 23, 2026Applications such as embodied intelligence rely on a real-time perception-decision-action closed loop, posing stringent challenges for streaming video understanding. However, current agents suffer from fragmented capabilities, such as supporting only offline video understanding, lacking long-term multimodal memory mechanisms, or struggling to achieve real-time reasoning and proactive interaction under streaming inputs. These shortcomings have become a key bottleneck for preventing them from sustaining perception, making real-time decisions, and executing actions in real-world environments. To alleviate these issues, we propose StreamingClaw, a unified agent framework for streaming video understanding and embodied intelligence. It is also an OpenClaw-compatible framework that supports real-time, multimodal streaming interaction. StreamingClaw integrates five core capabilities: (1) It supports real-time streaming reasoning. (2) It supports reasoning about future events and proactive interaction under the online evolution of interaction objectives. (3) It supports multimodal long-term storage, hierarchical evolution, and efficient retrieval of shared memory across multiple agents. (4) It supports a closed-loop of perception-decision-action. In addition to conventional tools and skills, it also provides streaming tools and action-centric skills tailored for real-world physical environments. (5) It is compatible with the OpenClaw framework, allowing it to fully leverage the resources and support of the open-source community. With these designs, StreamingClaw integrates online real-time reasoning, multimodal long-term memory, and proactive interaction within a unified framework. Moreover, by translating decisions into executable actions, it enables direct control of the physical world, supporting practical deployment of embodied interaction.
EXPLORE-Bench: Egocentric Scene Prediction with Long-Horizon Reasoning
Mar 12, 2026Multimodal large language models (MLLMs) are increasingly considered as a foundation for embodied agents, yet it remains unclear whether they can reliably reason about the long-term physical consequences of actions from an egocentric viewpoint. We study this gap through a new task, Egocentric Scene Prediction with LOng-horizon REasoning: given an initial-scene image and a sequence of atomic action descriptions, a model is asked to predict the final scene after all actions are executed. To enable systematic evaluation, we introduce EXPLORE-Bench, a benchmark curated from real first-person videos spanning diverse scenarios. Each instance pairs long action sequences with structured final-scene annotations, including object categories, visual attributes, and inter-object relations, which supports fine-grained, quantitative assessment. Experiments on a range of proprietary and open-source MLLMs reveal a significant performance gap to humans, indicating that long-horizon egocentric reasoning remains a major challenge. We further analyze test-time scaling via stepwise reasoning and show that decomposing long action sequences can improve performance to some extent, while incurring non-trivial computational overhead. Overall, EXPLORE-Bench provides a principled testbed for measuring and advancing long-horizon reasoning for egocentric embodied perception.
OSExpert: Computer-Use Agents Learning Professional Skills via Exploration
Mar 09, 2026General-purpose computer-use agents have shown impressive performance across diverse digital environments. However, our new benchmark, OSExpert-Eval, indicates they remain far less helpful than human experts. Although inference-time scaling enables adaptation, these agents complete complex tasks inefficiently with degraded performance, transfer poorly to unseen UIs, and struggle with fine-grained action sequences. To solve the problem, we introduce a GUI-based depth-first search (GUI-DFS) exploration algorithm to comprehensively explore and verify an environment's unit functions. The agent then exploits compositionality between unit skills to self-construct a curriculum for composite tasks. To support fine-grained actions, we curate a database of action primitives for agents to discover during exploration; these are saved as a skill set once the exploration is complete. We use the learned skills to improve the agent's performance and efficiency by (1) enriching agents with ready-to-use procedural knowledge, allowing them to plan only once for long trajectories and generate accurate actions, and (2) enabling them to end inference-time scaling earlier by realizing their boundary of capabilities. Extensive experiments show that our environment-learned agent takes a meaningful step toward expert-level computer use, achieving a around 20 percent performance gain on OSExpert-Eval and closing the efficiency gap to humans by around 80 percent
MindWatcher: Toward Smarter Multimodal Tool-Integrated Reasoning
Dec 29, 2025Traditional workflow-based agents exhibit limited intelligence when addressing real-world problems requiring tool invocation. Tool-integrated reasoning (TIR) agents capable of autonomous reasoning and tool invocation are rapidly emerging as a powerful approach for complex decision-making tasks involving multi-step interactions with external environments. In this work, we introduce MindWatcher, a TIR agent integrating interleaved thinking and multimodal chain-of-thought (CoT) reasoning. MindWatcher can autonomously decide whether and how to invoke diverse tools and coordinate their use, without relying on human prompts or workflows. The interleaved thinking paradigm enables the model to switch between thinking and tool calling at any intermediate stage, while its multimodal CoT capability allows manipulation of images during reasoning to yield more precise search results. We implement automated data auditing and evaluation pipelines, complemented by manually curated high-quality datasets for training, and we construct a benchmark, called MindWatcher-Evaluate Bench (MWE-Bench), to evaluate its performance. MindWatcher is equipped with a comprehensive suite of auxiliary reasoning tools, enabling it to address broad-domain multimodal problems. A large-scale, high-quality local image retrieval database, covering eight categories including cars, animals, and plants, endows model with robust object recognition despite its small size. Finally, we design a more efficient training infrastructure for MindWatcher, enhancing training speed and hardware utilization. Experiments not only demonstrate that MindWatcher matches or exceeds the performance of larger or more recent models through superior tool invocation, but also uncover critical insights for agent training, such as the genetic inheritance phenomenon in agentic RL.
Do Language Models Have Bayesian Brains? Distinguishing Stochastic and Deterministic Decision Patterns within Large Language Models
Jun 12, 2025Language models are essentially probability distributions over token sequences. Auto-regressive models generate sentences by iteratively computing and sampling from the distribution of the next token. This iterative sampling introduces stochasticity, leading to the assumption that language models make probabilistic decisions, similar to sampling from unknown distributions. Building on this assumption, prior research has used simulated Gibbs sampling, inspired by experiments designed to elicit human priors, to infer the priors of language models. In this paper, we revisit a critical question: Do language models possess Bayesian brains? Our findings show that under certain conditions, language models can exhibit near-deterministic decision-making, such as producing maximum likelihood estimations, even with a non-zero sampling temperature. This challenges the sampling assumption and undermines previous methods for eliciting human-like priors. Furthermore, we demonstrate that without proper scrutiny, a system with deterministic behavior undergoing simulated Gibbs sampling can converge to a "false prior." To address this, we propose a straightforward approach to distinguish between stochastic and deterministic decision patterns in Gibbs sampling, helping to prevent the inference of misleading language model priors. We experiment on a variety of large language models to identify their decision patterns under various circumstances. Our results provide key insights in understanding decision making of large language models.
Ordered-subsets Multi-diffusion Model for Sparse-view CT Reconstruction
May 15, 2025Score-based diffusion models have shown significant promise in the field of sparse-view CT reconstruction. However, the projection dataset is large and riddled with redundancy. Consequently, applying the diffusion model to unprocessed data results in lower learning effectiveness and higher learning difficulty, frequently leading to reconstructed images that lack fine details. To address these issues, we propose the ordered-subsets multi-diffusion model (OSMM) for sparse-view CT reconstruction. The OSMM innovatively divides the CT projection data into equal subsets and employs multi-subsets diffusion model (MSDM) to learn from each subset independently. This targeted learning approach reduces complexity and enhances the reconstruction of fine details. Furthermore, the integration of one-whole diffusion model (OWDM) with complete sinogram data acts as a global information constraint, which can reduce the possibility of generating erroneous or inconsistent sinogram information. Moreover, the OSMM's unsupervised learning framework provides strong robustness and generalizability, adapting seamlessly to varying sparsity levels of CT sinograms. This ensures consistent and reliable performance across different clinical scenarios. Experimental results demonstrate that OSMM outperforms traditional diffusion models in terms of image quality and noise resilience, offering a powerful and versatile solution for advanced CT imaging in sparse-view scenarios.
LDGen: Enhancing Text-to-Image Synthesis via Large Language Model-Driven Language Representation
Feb 25, 2025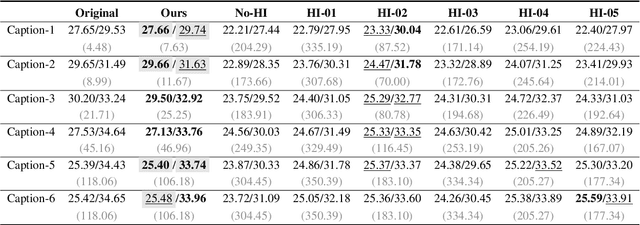
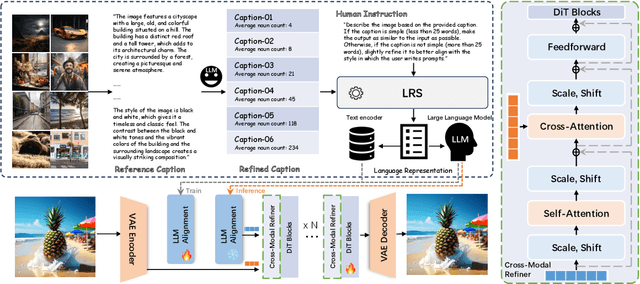
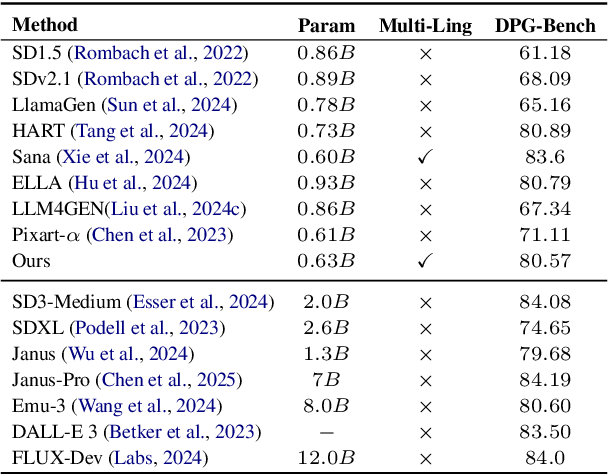

In this paper, we introduce LDGen, a novel method for integrating large language models (LLMs) into existing text-to-image diffusion models while minimizing computational demands. Traditional text encoders, such as CLIP and T5, exhibit limitations in multilingual processing, hindering image generation across diverse languages. We address these challenges by leveraging the advanced capabilities of LLMs. Our approach employs a language representation strategy that applies hierarchical caption optimization and human instruction techniques to derive precise semantic information,. Subsequently, we incorporate a lightweight adapter and a cross-modal refiner to facilitate efficient feature alignment and interaction between LLMs and image features. LDGen reduces training time and enables zero-shot multilingual image generation. Experimental results indicate that our method surpasses baseline models in both prompt adherence and image aesthetic quality, while seamlessly supporting multiple languages. Project page: https://zrealli.github.io/LDGen.