 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Pathway Geometry-Aware MLLM for Spatial Intelligence
May 25, 2026Spatial understanding of the physical world from 2D visual inputs hinges on two complementary forms of geometric knowledge: holistic 3D structural perception and fine-grained metric scale estimation. Existing multimodal large language models (MLLMs) typically address only one facet, ingesting either depth maps or point clouds as additional model inputs, which incurs substantial computational overhead and inherits the generalization limitations of upstream prediction models. We propose GAMSI, a dual-pathway Geometry-Aware MLLM for Spatial Intelligence that takes only RGB images as input while internalizing both forms of geometric prior within a unified autoregressive backbone. Specifically, we introduce Metric-Structure Decoupled Queries (MSDQ) which employ two groups of learnable queries to respectively extract dense metric signals and sparse structural cues from the shared visual context, with a task-decoupled attention mask further preventing the two pathways from contaminating each other. Building on this, an Expert-Guided Visual Grounding (EVG) module projects the aggregated cues back to frame-level visual features and aligns them with vision foundation models, which serve purely as training-time supervision, rather than as model inputs. We further build a multi-task spatial instruction-tuning dataset (MTS) comprising 152{,}776 samples spanning 13 task types and three visual modalities, consolidated from six public datasets. Trained with a two-stage curriculum, GAMSI achieves state-of-the-art performance on seven spatial intelligence benchmarks.
StreamingClaw Technical Report
Mar 23, 2026Applications such as embodied intelligence rely on a real-time perception-decision-action closed loop, posing stringent challenges for streaming video understanding. However, current agents suffer from fragmented capabilities, such as supporting only offline video understanding, lacking long-term multimodal memory mechanisms, or struggling to achieve real-time reasoning and proactive interaction under streaming inputs. These shortcomings have become a key bottleneck for preventing them from sustaining perception, making real-time decisions, and executing actions in real-world environments. To alleviate these issues, we propose StreamingClaw, a unified agent framework for streaming video understanding and embodied intelligence. It is also an OpenClaw-compatible framework that supports real-time, multimodal streaming interaction. StreamingClaw integrates five core capabilities: (1) It supports real-time streaming reasoning. (2) It supports reasoning about future events and proactive interaction under the online evolution of interaction objectives. (3) It supports multimodal long-term storage, hierarchical evolution, and efficient retrieval of shared memory across multiple agents. (4) It supports a closed-loop of perception-decision-action. In addition to conventional tools and skills, it also provides streaming tools and action-centric skills tailored for real-world physical environments. (5) It is compatible with the OpenClaw framework, allowing it to fully leverage the resources and support of the open-source community. With these designs, StreamingClaw integrates online real-time reasoning, multimodal long-term memory, and proactive interaction within a unified framework. Moreover, by translating decisions into executable actions, it enables direct control of the physical world, supporting practical deployment of embodied interaction.
MindWatcher: Toward Smarter Multimodal Tool-Integrated Reasoning
Dec 29, 2025Traditional workflow-based agents exhibit limited intelligence when addressing real-world problems requiring tool invocation. Tool-integrated reasoning (TIR) agents capable of autonomous reasoning and tool invocation are rapidly emerging as a powerful approach for complex decision-making tasks involving multi-step interactions with external environments. In this work, we introduce MindWatcher, a TIR agent integrating interleaved thinking and multimodal chain-of-thought (CoT) reasoning. MindWatcher can autonomously decide whether and how to invoke diverse tools and coordinate their use, without relying on human prompts or workflows. The interleaved thinking paradigm enables the model to switch between thinking and tool calling at any intermediate stage, while its multimodal CoT capability allows manipulation of images during reasoning to yield more precise search results. We implement automated data auditing and evaluation pipelines, complemented by manually curated high-quality datasets for training, and we construct a benchmark, called MindWatcher-Evaluate Bench (MWE-Bench), to evaluate its performance. MindWatcher is equipped with a comprehensive suite of auxiliary reasoning tools, enabling it to address broad-domain multimodal problems. A large-scale, high-quality local image retrieval database, covering eight categories including cars, animals, and plants, endows model with robust object recognition despite its small size. Finally, we design a more efficient training infrastructure for MindWatcher, enhancing training speed and hardware utilization. Experiments not only demonstrate that MindWatcher matches or exceeds the performance of larger or more recent models through superior tool invocation, but also uncover critical insights for agent training, such as the genetic inheritance phenomenon in agentic RL.
LDGen: Enhancing Text-to-Image Synthesis via Large Language Model-Driven Language Representation
Feb 25, 2025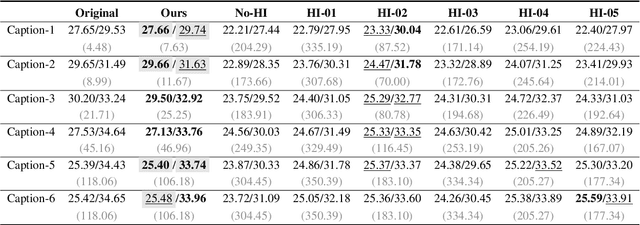
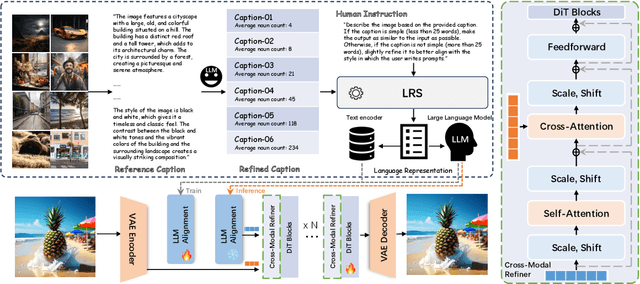
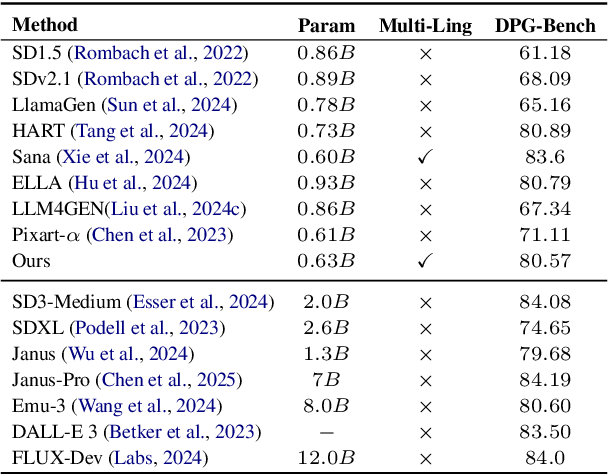

In this paper, we introduce LDGen, a novel method for integrating large language models (LLMs) into existing text-to-image diffusion models while minimizing computational demands. Traditional text encoders, such as CLIP and T5, exhibit limitations in multilingual processing, hindering image generation across diverse languages. We address these challenges by leveraging the advanced capabilities of LLMs. Our approach employs a language representation strategy that applies hierarchical caption optimization and human instruction techniques to derive precise semantic information,. Subsequently, we incorporate a lightweight adapter and a cross-modal refiner to facilitate efficient feature alignment and interaction between LLMs and image features. LDGen reduces training time and enables zero-shot multilingual image generation. Experimental results indicate that our method surpasses baseline models in both prompt adherence and image aesthetic quality, while seamlessly supporting multiple languages. Project page: https://zrealli.github.io/LDGen.
FreeCustom: Tuning-Free Customized Image Generation for Multi-Concept Composition
May 22, 2024



Benefiting from large-scale pre-trained text-to-image (T2I) generative models, impressive progress has been achieved in customized image generation, which aims to generate user-specified concepts. Existing approaches have extensively focused on single-concept customization and still encounter challenges when it comes to complex scenarios that involve combining multiple concepts. These approaches often require retraining/fine-tuning using a few images, leading to time-consuming training processes and impeding their swift implementation. Furthermore, the reliance on multiple images to represent a singular concept increases the difficulty of customization. To this end, we propose FreeCustom, a novel tuning-free method to generate customized images of multi-concept composition based on reference concepts, using only one image per concept as input. Specifically, we introduce a new multi-reference self-attention (MRSA) mechanism and a weighted mask strategy that enables the generated image to access and focus more on the reference concepts. In addition, MRSA leverages our key finding that input concepts are better preserved when providing images with context interactions. Experiments show that our method's produced images are consistent with the given concepts and better aligned with the input text. Our method outperforms or performs on par with other training-based methods in terms of multi-concept composition and single-concept customization, but is simpler. Codes can be found at https://github.com/aim-uofa/FreeCustom.
Zero-Shot Video Editing Using Off-The-Shelf Image Diffusion Models
Apr 13, 2023



Large-scale text-to-image diffusion models achieve unprecedented success in image generation and editing. However, how to extend such success to video editing is unclear. Recent initial attempts at video editing require significant text-to-video data and computation resources for training, which is often not accessible. In this work, we propose vid2vid-zero, a simple yet effective method for zero-shot video editing. Our vid2vid-zero leverages off-the-shelf image diffusion models, and doesn't require training on any video. At the core of our method is a null-text inversion module for text-to-video alignment, a cross-frame modeling module for temporal consistency, and a spatial regularization module for fidelity to the original video. Without any training, we leverage the dynamic nature of the attention mechanism to enable bi-directional temporal modeling at test time. Experiments and analyses show promising results in editing attributes, subjects, places, etc., in real-world videos. Code is made available at \url{https://github.com/baaivision/vid2vid-zero}.