 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLDGen: Enhancing Text-to-Image Synthesis via Large Language Model-Driven Language Representation
Feb 25, 2025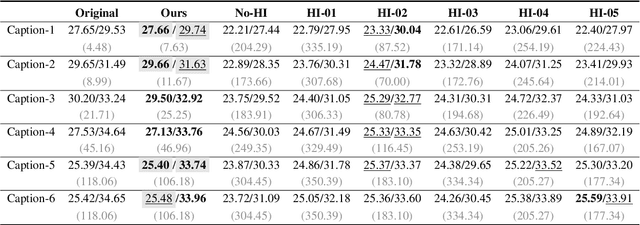
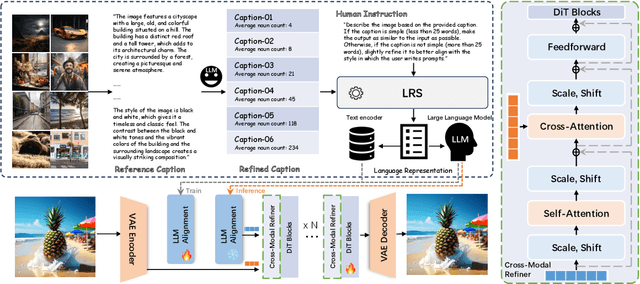
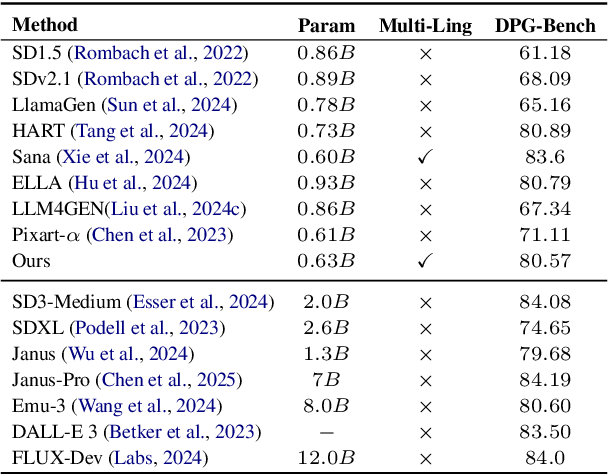

In this paper, we introduce LDGen, a novel method for integrating large language models (LLMs) into existing text-to-image diffusion models while minimizing computational demands. Traditional text encoders, such as CLIP and T5, exhibit limitations in multilingual processing, hindering image generation across diverse languages. We address these challenges by leveraging the advanced capabilities of LLMs. Our approach employs a language representation strategy that applies hierarchical caption optimization and human instruction techniques to derive precise semantic information,. Subsequently, we incorporate a lightweight adapter and a cross-modal refiner to facilitate efficient feature alignment and interaction between LLMs and image features. LDGen reduces training time and enables zero-shot multilingual image generation. Experimental results indicate that our method surpasses baseline models in both prompt adherence and image aesthetic quality, while seamlessly supporting multiple languages. Project page: https://zrealli.github.io/LDGen.
ART3D: 3D Gaussian Splatting for Text-Guided Artistic Scenes Generation
May 17, 2024



In this paper, we explore the existing challenges in 3D artistic scene generation by introducing ART3D, a novel framework that combines diffusion models and 3D Gaussian splatting techniques. Our method effectively bridges the gap between artistic and realistic images through an innovative image semantic transfer algorithm. By leveraging depth information and an initial artistic image, we generate a point cloud map, addressing domain differences. Additionally, we propose a depth consistency module to enhance 3D scene consistency. Finally, the 3D scene serves as initial points for optimizing Gaussian splats. Experimental results demonstrate ART3D's superior performance in both content and structural consistency metrics when compared to existing methods. ART3D significantly advances the field of AI in art creation by providing an innovative solution for generating high-quality 3D artistic scenes.
Generating Daylight-driven Architectural Design via Diffusion Models
Apr 20, 2024



In recent years, the rapid development of large-scale models has made new possibilities for interdisciplinary fields such as architecture. In this paper, we present a novel daylight-driven AI-aided architectural design method. Firstly, we formulate a method for generating massing models, producing architectural massing models using random parameters quickly. Subsequently, we integrate a daylight-driven facade design strategy, accurately determining window layouts and applying them to the massing models. Finally, we seamlessly combine a large-scale language model with a text-to-image model, enhancing the efficiency of generating visual architectural design renderings. Experimental results demonstrate that our approach supports architects' creative inspirations and pioneers novel avenues for architectural design development. Project page: https://zrealli.github.io/DDADesign/.
* Project page: https://zrealli.github.io/DDADesign/
The Devil is in the Edges: Monocular Depth Estimation with Edge-aware Consistency Fusion
Mar 30, 2024This paper presents a novel monocular depth estimation method, named ECFNet, for estimating high-quality monocular depth with clear edges and valid overall structure from a single RGB image. We make a thorough inquiry about the key factor that affects the edge depth estimation of the MDE networks, and come to a ratiocination that the edge information itself plays a critical role in predicting depth details. Driven by this analysis, we propose to explicitly employ the image edges as input for ECFNet and fuse the initial depths from different sources to produce the final depth. Specifically, ECFNet first uses a hybrid edge detection strategy to get the edge map and edge-highlighted image from the input image, and then leverages a pre-trained MDE network to infer the initial depths of the aforementioned three images. After that, ECFNet utilizes a layered fusion module (LFM) to fuse the initial depth, which will be further updated by a depth consistency module (DCM) to form the final estimation. Extensive experimental results on public datasets and ablation studies indicate that our method achieves state-of-the-art performance. Project page: https://zrealli.github.io/edgedepth.
Sketch-to-Architecture: Generative AI-aided Architectural Design
Mar 29, 2024



Recently, the development of large-scale models has paved the way for various interdisciplinary research, including architecture. By using generative AI, we present a novel workflow that utilizes AI models to generate conceptual floorplans and 3D models from simple sketches, enabling rapid ideation and controlled generation of architectural renderings based on textual descriptions. Our work demonstrates the potential of generative AI in the architectural design process, pointing towards a new direction of computer-aided architectural design. Our project website is available at: https://zrealli.github.io/sketch2arc
Tuning-Free Image Customization with Image and Text Guidance
Mar 19, 2024



Despite significant advancements in image customization with diffusion models, current methods still have several limitations: 1) unintended changes in non-target areas when regenerating the entire image; 2) guidance solely by a reference image or text descriptions; and 3) time-consuming fine-tuning, which limits their practical application. In response, we introduce a tuning-free framework for simultaneous text-image-guided image customization, enabling precise editing of specific image regions within seconds. Our approach preserves the semantic features of the reference image subject while allowing modification of detailed attributes based on text descriptions. To achieve this, we propose an innovative attention blending strategy that blends self-attention features in the UNet decoder during the denoising process. To our knowledge, this is the first tuning-free method that concurrently utilizes text and image guidance for image customization in specific regions. Our approach outperforms previous methods in both human and quantitative evaluations, providing an efficient solution for various practical applications, such as image synthesis, design, and creative photography.
LayerDiffusion: Layered Controlled Image Editing with Diffusion Models
May 30, 2023Text-guided image editing has recently experienced rapid development. However, simultaneously performing multiple editing actions on a single image, such as background replacement and specific subject attribute changes, while maintaining consistency between the subject and the background remains challenging. In this paper, we propose LayerDiffusion, a semantic-based layered controlled image editing method. Our method enables non-rigid editing and attribute modification of specific subjects while preserving their unique characteristics and seamlessly integrating them into new backgrounds. We leverage a large-scale text-to-image model and employ a layered controlled optimization strategy combined with layered diffusion training. During the diffusion process, an iterative guidance strategy is used to generate a final image that aligns with the textual description. Experimental results demonstrate the effectiveness of our method in generating highly coherent images that closely align with the given textual description. The edited images maintain a high similarity to the features of the input image and surpass the performance of current leading image editing methods. LayerDiffusion opens up new possibilities for controllable image editing.