 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMindWatcher: Toward Smarter Multimodal Tool-Integrated Reasoning
Dec 29, 2025Traditional workflow-based agents exhibit limited intelligence when addressing real-world problems requiring tool invocation. Tool-integrated reasoning (TIR) agents capable of autonomous reasoning and tool invocation are rapidly emerging as a powerful approach for complex decision-making tasks involving multi-step interactions with external environments. In this work, we introduce MindWatcher, a TIR agent integrating interleaved thinking and multimodal chain-of-thought (CoT) reasoning. MindWatcher can autonomously decide whether and how to invoke diverse tools and coordinate their use, without relying on human prompts or workflows. The interleaved thinking paradigm enables the model to switch between thinking and tool calling at any intermediate stage, while its multimodal CoT capability allows manipulation of images during reasoning to yield more precise search results. We implement automated data auditing and evaluation pipelines, complemented by manually curated high-quality datasets for training, and we construct a benchmark, called MindWatcher-Evaluate Bench (MWE-Bench), to evaluate its performance. MindWatcher is equipped with a comprehensive suite of auxiliary reasoning tools, enabling it to address broad-domain multimodal problems. A large-scale, high-quality local image retrieval database, covering eight categories including cars, animals, and plants, endows model with robust object recognition despite its small size. Finally, we design a more efficient training infrastructure for MindWatcher, enhancing training speed and hardware utilization. Experiments not only demonstrate that MindWatcher matches or exceeds the performance of larger or more recent models through superior tool invocation, but also uncover critical insights for agent training, such as the genetic inheritance phenomenon in agentic RL.
LDGen: Enhancing Text-to-Image Synthesis via Large Language Model-Driven Language Representation
Feb 25, 2025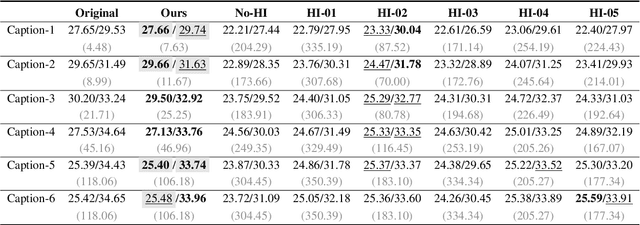
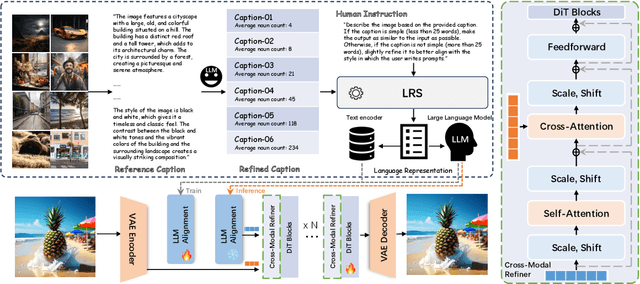
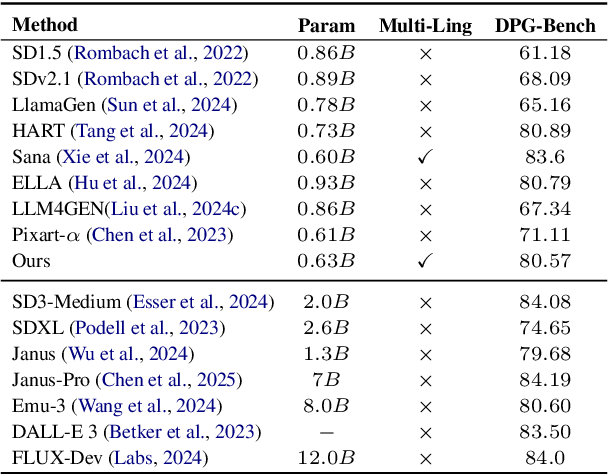

In this paper, we introduce LDGen, a novel method for integrating large language models (LLMs) into existing text-to-image diffusion models while minimizing computational demands. Traditional text encoders, such as CLIP and T5, exhibit limitations in multilingual processing, hindering image generation across diverse languages. We address these challenges by leveraging the advanced capabilities of LLMs. Our approach employs a language representation strategy that applies hierarchical caption optimization and human instruction techniques to derive precise semantic information,. Subsequently, we incorporate a lightweight adapter and a cross-modal refiner to facilitate efficient feature alignment and interaction between LLMs and image features. LDGen reduces training time and enables zero-shot multilingual image generation. Experimental results indicate that our method surpasses baseline models in both prompt adherence and image aesthetic quality, while seamlessly supporting multiple languages. Project page: https://zrealli.github.io/LDGen.
RGAT: A Deeper Look into Syntactic Dependency Information for Coreference Resolution
Sep 10, 2023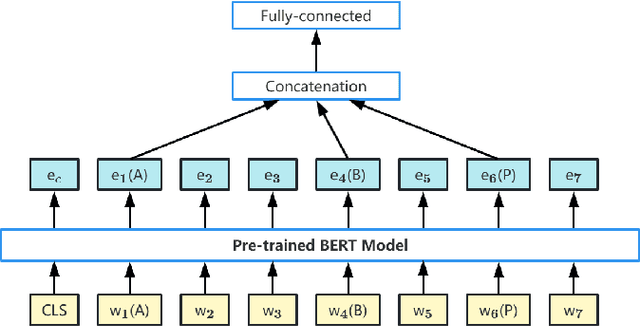
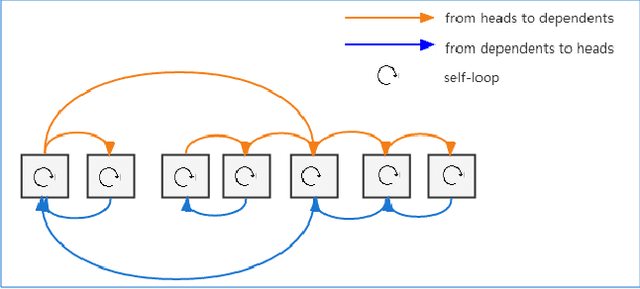
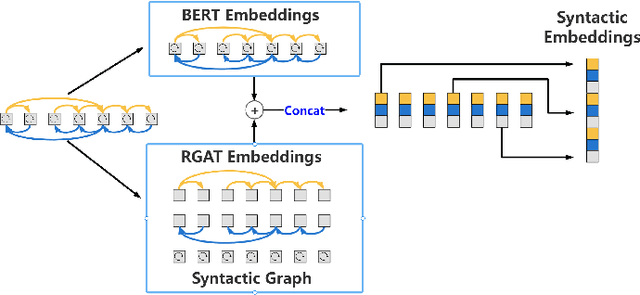
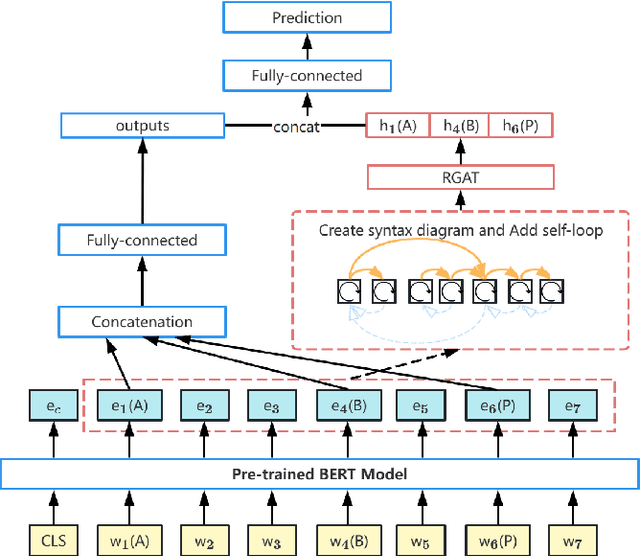
Although syntactic information is beneficial for many NLP tasks, combining it with contextual information between words to solve the coreference resolution problem needs to be further explored. In this paper, we propose an end-to-end parser that combines pre-trained BERT with a Syntactic Relation Graph Attention Network (RGAT) to take a deeper look into the role of syntactic dependency information for the coreference resolution task. In particular, the RGAT model is first proposed, then used to understand the syntactic dependency graph and learn better task-specific syntactic embeddings. An integrated architecture incorporating BERT embeddings and syntactic embeddings is constructed to generate blending representations for the downstream task. Our experiments on a public Gendered Ambiguous Pronouns (GAP) dataset show that with the supervision learning of the syntactic dependency graph and without fine-tuning the entire BERT, we increased the F1-score of the previous best model (RGCN-with-BERT) from 80.3% to 82.5%, compared to the F1-score by single BERT embeddings from 78.5% to 82.5%. Experimental results on another public dataset - OntoNotes 5.0 demonstrate that the performance of the model is also improved by incorporating syntactic dependency information learned from RGAT.
* 8 pages, 5 figures