 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Lane Detection from Front or Surround-View using Joint-Modeling & Matching
Jan 16, 20243D lanes offer a more comprehensive understanding of the road surface geometry than 2D lanes, thereby providing crucial references for driving decisions and trajectory planning. While many efforts aim to improve prediction accuracy, we recognize that an efficient network can bring results closer to lane modeling. However, if the modeling data is imprecise, the results might not accurately capture the real-world scenario. Therefore, accurate lane modeling is essential to align prediction results closely with the environment. This study centers on efficient and accurate lane modeling, proposing a joint modeling approach that combines Bezier curves and interpolation methods. Furthermore, based on this lane modeling approach, we developed a Global2Local Lane Matching method with Bezier Control-Point and Key-Point, which serve as a comprehensive solution that leverages hierarchical features with two mathematical models to ensure a precise match. We also introduce a novel 3D Spatial Constructor, representing an exploration of 3D surround-view lane detection research. The framework is suitable for front-view or surround-view 3D lane detection. By directly outputting the key points of lanes in 3D space, it overcomes the limitations of anchor-based methods, enabling accurate prediction of closed-loop or U-shaped lanes and effective adaptation to complex road conditions. This innovative method establishes a new benchmark in front-view 3D lane detection on the Openlane dataset and achieves competitive performance in surround-view 2D lane detection on the Argoverse2 dataset.
RGAT: A Deeper Look into Syntactic Dependency Information for Coreference Resolution
Sep 10, 2023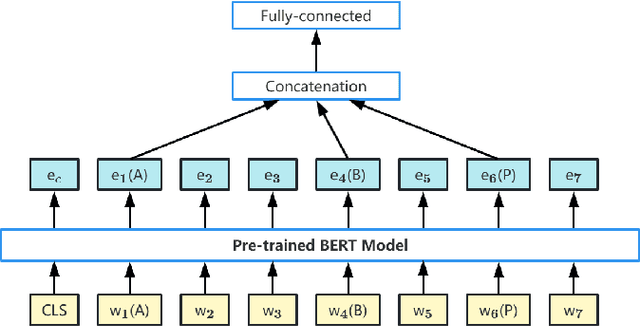
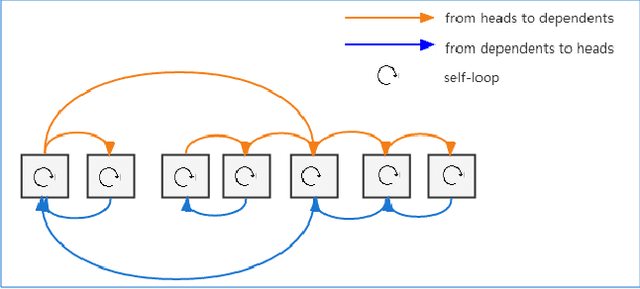
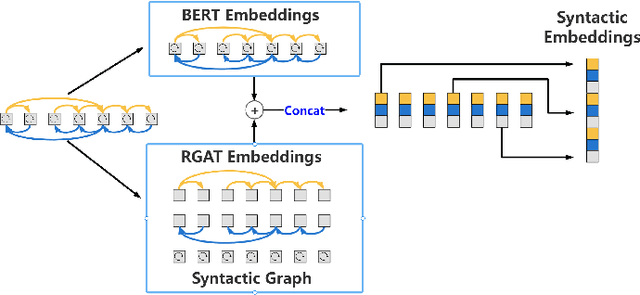
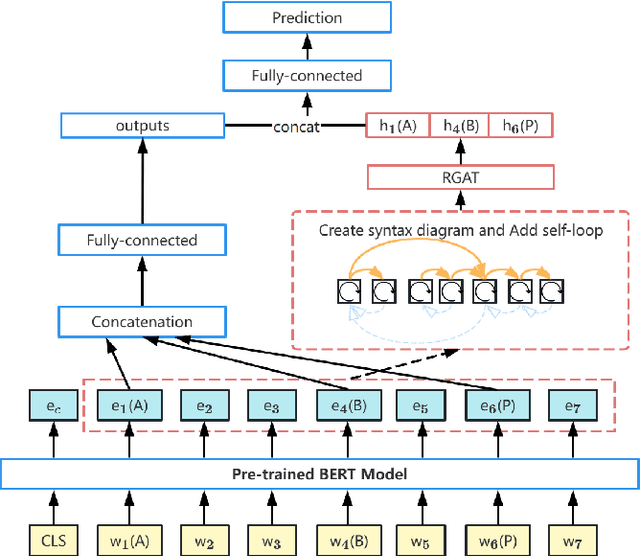
Although syntactic information is beneficial for many NLP tasks, combining it with contextual information between words to solve the coreference resolution problem needs to be further explored. In this paper, we propose an end-to-end parser that combines pre-trained BERT with a Syntactic Relation Graph Attention Network (RGAT) to take a deeper look into the role of syntactic dependency information for the coreference resolution task. In particular, the RGAT model is first proposed, then used to understand the syntactic dependency graph and learn better task-specific syntactic embeddings. An integrated architecture incorporating BERT embeddings and syntactic embeddings is constructed to generate blending representations for the downstream task. Our experiments on a public Gendered Ambiguous Pronouns (GAP) dataset show that with the supervision learning of the syntactic dependency graph and without fine-tuning the entire BERT, we increased the F1-score of the previous best model (RGCN-with-BERT) from 80.3% to 82.5%, compared to the F1-score by single BERT embeddings from 78.5% to 82.5%. Experimental results on another public dataset - OntoNotes 5.0 demonstrate that the performance of the model is also improved by incorporating syntactic dependency information learned from RGAT.
* 8 pages, 5 figures
Single-stage Rotate Object Detector via Two Points with Solar Corona Heatmap
Feb 14, 2022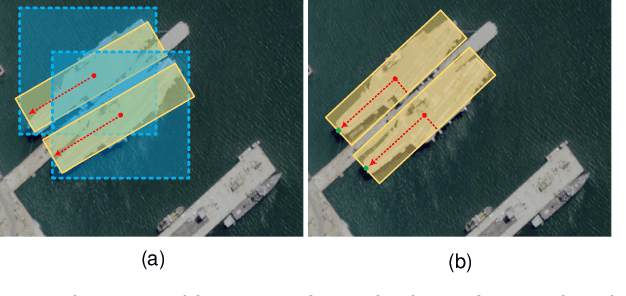

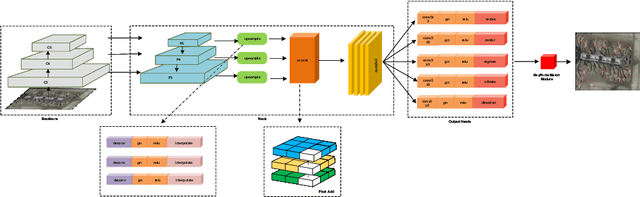
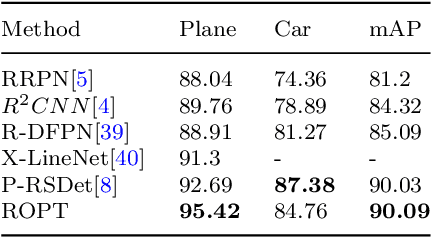
Oriented object detection is a crucial task in computer vision. Current top-down oriented detection methods usually directly detect entire objects, and not only neglecting the authentic direction of targets, but also do not fully utilise the key semantic information, which causes a decrease in detection accuracy. In this study, we developed a single-stage rotating object detector via two points with a solar corona heatmap (ROTP) to detect oriented objects. The ROTP predicts parts of the object and then aggregates them to form a whole image. Herein, we meticulously represent an object in a random direction using the vertex, centre point with width, and height. Specifically, we regress two heatmaps that characterise the relative location of each object, which enhances the accuracy of locating objects and avoids deviations caused by angle predictions. To rectify the central misjudgement of the Gaussian heatmap on high-aspect ratio targets, we designed a solar corona heatmap generation method to improve the perception difference between the central and non-central samples. Additionally, we predicted the vertex relative to the direction of the centre point to connect two key points that belong to the same goal. Experiments on the HRSC 2016, UCASAOD, and DOTA datasets show that our ROTP achieves the most advanced performance with a simpler modelling and less manual intervention.