 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePET-DINO: Unifying Visual Cues into Grounding DINO with Prompt-Enriched Training
Apr 01, 2026Open-Set Object Detection (OSOD) enables recognition of novel categories beyond fixed classes but faces challenges in aligning text representations with complex visual concepts and the scarcity of image-text pairs for rare categories. This results in suboptimal performance in specialized domains or with complex objects. Recent visual-prompted methods partially address these issues but often involve complex multi-modal designs and multi-stage optimizations, prolonging the development cycle. Additionally, effective training strategies for data-driven OSOD models remain largely unexplored. To address these challenges, we propose PET-DINO, a universal detector supporting both text and visual prompts. Our Alignment-Friendly Visual Prompt Generation (AFVPG) module builds upon an advanced text-prompted detector, addressing the limitations of text representation guidance and reducing the development cycle. We introduce two prompt-enriched training strategies: Intra-Batch Parallel Prompting (IBP) at the iteration level and Dynamic Memory-Driven Prompting (DMD) at the overall training level. These strategies enable simultaneous modeling of multiple prompt routes, facilitating parallel alignment with diverse real-world usage scenarios. Comprehensive experiments demonstrate that PET-DINO exhibits competitive zero-shot object detection capabilities across various prompt-based detection protocols. These strengths can be attributed to inheritance-based philosophy and prompt-enriched training strategies, which play a critical role in building an effective generic object detector. Project page: https://fuweifuvtoo.github.io/pet-dino.
Decision Boundary-aware Knowledge Consolidation Generates Better Instance-Incremental Learner
Jun 05, 2024Instance-incremental learning (IIL) focuses on learning continually with data of the same classes. Compared to class-incremental learning (CIL), the IIL is seldom explored because IIL suffers less from catastrophic forgetting (CF). However, besides retaining knowledge, in real-world deployment scenarios where the class space is always predefined, continual and cost-effective model promotion with the potential unavailability of previous data is a more essential demand. Therefore, we first define a new and more practical IIL setting as promoting the model's performance besides resisting CF with only new observations. Two issues have to be tackled in the new IIL setting: 1) the notorious catastrophic forgetting because of no access to old data, and 2) broadening the existing decision boundary to new observations because of concept drift. To tackle these problems, our key insight is to moderately broaden the decision boundary to fail cases while retain old boundary. Hence, we propose a novel decision boundary-aware distillation method with consolidating knowledge to teacher to ease the student learning new knowledge. We also establish the benchmarks on existing datasets Cifar-100 and ImageNet. Notably, extensive experiments demonstrate that the teacher model can be a better incremental learner than the student model, which overturns previous knowledge distillation-based methods treating student as the main role.
Tuning-Free Image Customization with Image and Text Guidance
Mar 19, 2024



Despite significant advancements in image customization with diffusion models, current methods still have several limitations: 1) unintended changes in non-target areas when regenerating the entire image; 2) guidance solely by a reference image or text descriptions; and 3) time-consuming fine-tuning, which limits their practical application. In response, we introduce a tuning-free framework for simultaneous text-image-guided image customization, enabling precise editing of specific image regions within seconds. Our approach preserves the semantic features of the reference image subject while allowing modification of detailed attributes based on text descriptions. To achieve this, we propose an innovative attention blending strategy that blends self-attention features in the UNet decoder during the denoising process. To our knowledge, this is the first tuning-free method that concurrently utilizes text and image guidance for image customization in specific regions. Our approach outperforms previous methods in both human and quantitative evaluations, providing an efficient solution for various practical applications, such as image synthesis, design, and creative photography.
LORS: Low-rank Residual Structure for Parameter-Efficient Network Stacking
Mar 07, 2024



Deep learning models, particularly those based on transformers, often employ numerous stacked structures, which possess identical architectures and perform similar functions. While effective, this stacking paradigm leads to a substantial increase in the number of parameters, posing challenges for practical applications. In today's landscape of increasingly large models, stacking depth can even reach dozens, further exacerbating this issue. To mitigate this problem, we introduce LORS (LOw-rank Residual Structure). LORS allows stacked modules to share the majority of parameters, requiring a much smaller number of unique ones per module to match or even surpass the performance of using entirely distinct ones, thereby significantly reducing parameter usage. We validate our method by applying it to the stacked decoders of a query-based object detector, and conduct extensive experiments on the widely used MS COCO dataset. Experimental results demonstrate the effectiveness of our method, as even with a 70\% reduction in the parameters of the decoder, our method still enables the model to achieve comparable or
Can the Query-based Object Detector Be Designed with Fewer Stages?
Sep 28, 2023Query-based object detectors have made significant advancements since the publication of DETR. However, most existing methods still rely on multi-stage encoders and decoders, or a combination of both. Despite achieving high accuracy, the multi-stage paradigm (typically consisting of 6 stages) suffers from issues such as heavy computational burden, prompting us to reconsider its necessity. In this paper, we explore multiple techniques to enhance query-based detectors and, based on these findings, propose a novel model called GOLO (Global Once and Local Once), which follows a two-stage decoding paradigm. Compared to other mainstream query-based models with multi-stage decoders, our model employs fewer decoder stages while still achieving considerable performance. Experimental results on the COCO dataset demonstrate the effectiveness of our approach.
Semi-supervised Domain Adaptation with Inter and Intra-domain Mixing for Semantic Segmentation
Aug 30, 2023Despite recent advances in semantic segmentation, an inevitable challenge is the performance degradation caused by the domain shift in real application. Current dominant approach to solve this problem is unsupervised domain adaptation (UDA). However, the absence of labeled target data in UDA is overly restrictive and limits performance. To overcome this limitation, a more practical scenario called semi-supervised domain adaptation (SSDA) has been proposed. Existing SSDA methods are derived from the UDA paradigm and primarily focus on leveraging the unlabeled target data and source data. In this paper, we highlight the significance of exploiting the intra-domain information between the limited labeled target data and unlabeled target data, as it greatly benefits domain adaptation. Instead of solely using the scarce labeled data for supervision, we propose a novel SSDA framework that incorporates both inter-domain mixing and intra-domain mixing, where inter-domain mixing mitigates the source-target domain gap and intra-domain mixing enriches the available target domain information. By simultaneously learning from inter-domain mixing and intra-domain mixing, the network can capture more domain-invariant features and promote its performance on the target domain. We also explore different domain mixing operations to better exploit the target domain information. Comprehensive experiments conducted on the GTA5toCityscapes and SYNTHIA2Cityscapes benchmarks demonstrate the effectiveness of our method, surpassing previous methods by a large margin.
ECM-OPCC: Efficient Context Model for Octree-based Point Cloud Compression
Nov 22, 2022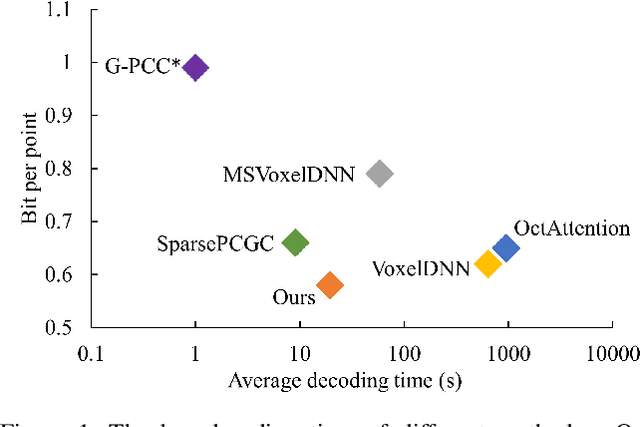
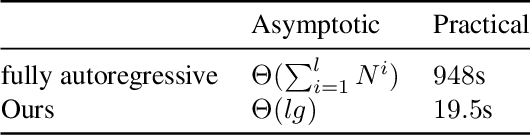
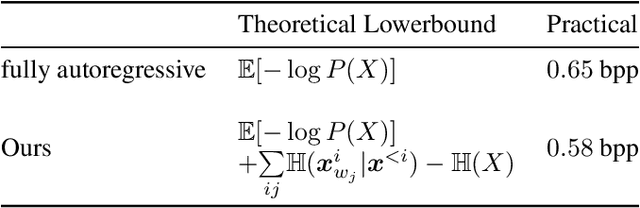
Recently, deep learning methods have shown promising results in point cloud compression. For octree-based point cloud compression, previous works show that the information of ancestor nodes and sibling nodes are equally important for predicting current node. However, those works either adopt insufficient context or bring intolerable decoding complexity (e.g. >600s). To address this problem, we propose a sufficient yet efficient context model and design an efficient deep learning codec for point clouds. Specifically, we first propose a window-constrained multi-group coding strategy to exploit the autoregressive context while maintaining decoding efficiency. Then, we propose a dual transformer architecture to utilize the dependency of current node on its ancestors and siblings. We also propose a random-masking pre-train method to enhance our model. Experimental results show that our approach achieves state-of-the-art performance for both lossy and lossless point cloud compression. Moreover, our multi-group coding strategy saves 98% decoding time compared with previous octree-based compression method.
Unsupervised Vision-Language Parsing: Seamlessly Bridging Visual Scene Graphs with Language Structures via Dependency Relationships
Mar 27, 2022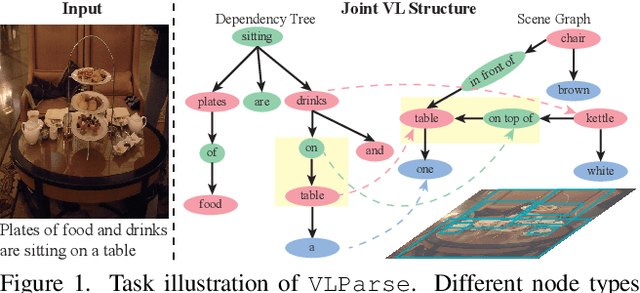
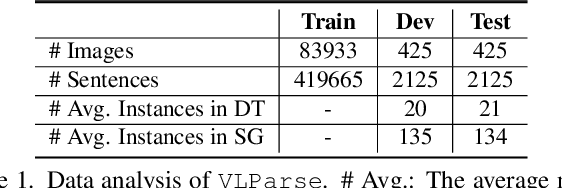
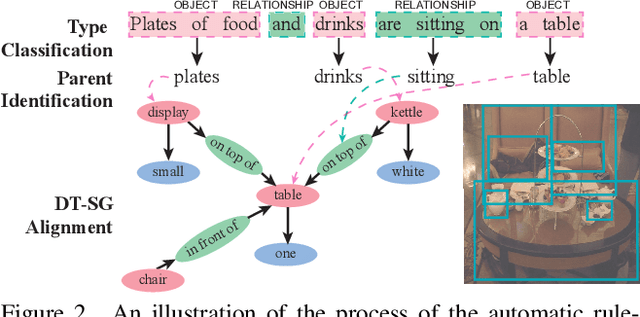
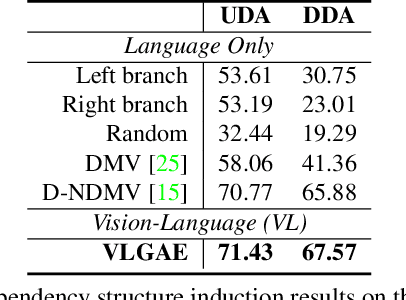
Understanding realistic visual scene images together with language descriptions is a fundamental task towards generic visual understanding. Previous works have shown compelling comprehensive results by building hierarchical structures for visual scenes (e.g., scene graphs) and natural languages (e.g., dependency trees), individually. However, how to construct a joint vision-language (VL) structure has barely been investigated. More challenging but worthwhile, we introduce a new task that targets on inducing such a joint VL structure in an unsupervised manner. Our goal is to bridge the visual scene graphs and linguistic dependency trees seamlessly. Due to the lack of VL structural data, we start by building a new dataset VLParse. Rather than using labor-intensive labeling from scratch, we propose an automatic alignment procedure to produce coarse structures followed by human refinement to produce high-quality ones. Moreover, we benchmark our dataset by proposing a contrastive learning (CL)-based framework VLGAE, short for Vision-Language Graph Autoencoder. Our model obtains superior performance on two derived tasks, i.e., language grammar induction and VL phrase grounding. Ablations show the effectiveness of both visual cues and dependency relationships on fine-grained VL structure construction.