 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLORS: Low-rank Residual Structure for Parameter-Efficient Network Stacking
Mar 07, 2024



Deep learning models, particularly those based on transformers, often employ numerous stacked structures, which possess identical architectures and perform similar functions. While effective, this stacking paradigm leads to a substantial increase in the number of parameters, posing challenges for practical applications. In today's landscape of increasingly large models, stacking depth can even reach dozens, further exacerbating this issue. To mitigate this problem, we introduce LORS (LOw-rank Residual Structure). LORS allows stacked modules to share the majority of parameters, requiring a much smaller number of unique ones per module to match or even surpass the performance of using entirely distinct ones, thereby significantly reducing parameter usage. We validate our method by applying it to the stacked decoders of a query-based object detector, and conduct extensive experiments on the widely used MS COCO dataset. Experimental results demonstrate the effectiveness of our method, as even with a 70\% reduction in the parameters of the decoder, our method still enables the model to achieve comparable or
Restoring Vision in Hazy Weather with Hierarchical Contrastive Learning
Dec 22, 2022



Image restoration under hazy weather condition, which is called single image dehazing, has been of significant interest for various computer vision applications. In recent years, deep learning-based methods have achieved success. However, existing image dehazing methods typically neglect the hierarchy of features in the neural network and fail to exploit their relationships fully. To this end, we propose an effective image dehazing method named Hierarchical Contrastive Dehazing (HCD), which is based on feature fusion and contrastive learning strategies. HCD consists of a hierarchical dehazing network (HDN) and a novel hierarchical contrastive loss (HCL). Specifically, the core design in the HDN is a Hierarchical Interaction Module, which utilizes multi-scale activation to revise the feature responses hierarchically. To cooperate with the training of HDN, we propose HCL which performs contrastive learning on hierarchically paired exemplars, facilitating haze removal. Extensive experiments on public datasets, RESIDE, HazeRD, and DENSE-HAZE, demonstrate that HCD quantitatively outperforms the state-of-the-art methods in terms of PSNR, SSIM and achieves better visual quality.
Spectrum-to-Kernel Translation for Accurate Blind Image Super-Resolution
Oct 23, 2021


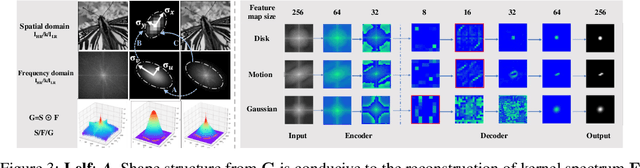
Deep-learning based Super-Resolution (SR) methods have exhibited promising performance under non-blind setting where blur kernel is known. However, blur kernels of Low-Resolution (LR) images in different practical applications are usually unknown. It may lead to significant performance drop when degradation process of training images deviates from that of real images. In this paper, we propose a novel blind SR framework to super-resolve LR images degraded by arbitrary blur kernel with accurate kernel estimation in frequency domain. To our best knowledge, this is the first deep learning method which conducts blur kernel estimation in frequency domain. Specifically, we first demonstrate that feature representation in frequency domain is more conducive for blur kernel reconstruction than in spatial domain. Next, we present a Spectrum-to-Kernel (S$2$K) network to estimate general blur kernels in diverse forms. We use a Conditional GAN (CGAN) combined with SR-oriented optimization target to learn the end-to-end translation from degraded images' spectra to unknown kernels. Extensive experiments on both synthetic and real-world images demonstrate that our proposed method sufficiently reduces blur kernel estimation error, thus enables the off-the-shelf non-blind SR methods to work under blind setting effectively, and achieves superior performance over state-of-the-art blind SR methods, averagely by 1.39dB, 0.48dB on commom blind SR setting (with Gaussian kernels) for scales $2\times$ and $4\times$, respectively.
Frequency Consistent Adaptation for Real World Super Resolution
Dec 18, 2020



Recent deep-learning based Super-Resolution (SR) methods have achieved remarkable performance on images with known degradation. However, these methods always fail in real-world scene, since the Low-Resolution (LR) images after the ideal degradation (e.g., bicubic down-sampling) deviate from real source domain. The domain gap between the LR images and the real-world images can be observed clearly on frequency density, which inspires us to explictly narrow the undesired gap caused by incorrect degradation. From this point of view, we design a novel Frequency Consistent Adaptation (FCA) that ensures the frequency domain consistency when applying existing SR methods to the real scene. We estimate degradation kernels from unsupervised images and generate the corresponding LR images. To provide useful gradient information for kernel estimation, we propose Frequency Density Comparator (FDC) by distinguishing the frequency density of images on different scales. Based on the domain-consistent LR-HR pairs, we train easy-implemented Convolutional Neural Network (CNN) SR models. Extensive experiments show that the proposed FCA improves the performance of the SR model under real-world setting achieving state-of-the-art results with high fidelity and plausible perception, thus providing a novel effective framework for real-world SR application.