 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJAVEDIT: Joint Audio-Visual Instruction-Guided Video Editing with Agentic Data Curation
Jun 02, 2026While instruction-based video editing has seen significant progress, joint audio-visual editing remains constrained by the absence of dedicated datasets and benchmarks. To bridge this gap, we present JAVEdit-100k, the first large-scale, high-quality dataset tailored for instruction-guided joint audio-visual editing. Focusing on human-centric videos, JAVEdit-100k comprises approximately 100K editing triplets spanning five distinct categories, including subject editing and speech editing. This dataset is rigorously constructed via four meticulously designed generation pipelines, seamlessly paired with an agent-in-the-loop quality control mechanism. Furthermore, to address the lack of standardized evaluation within the field, we introduce JAVEditBench, a comprehensive benchmark featuring curated source videos and human-aligned instructions across all editing categories. Finally, we propose JAVEdit, a pioneering baseline model for instruction-guided joint audio-visual editing. Experiments show that \model\ outperforms all baselines on five of six evaluation metrics.
Soul: Breathe Life into Digital Human for High-fidelity Long-term Multimodal Animation
Dec 15, 2025We propose a multimodal-driven framework for high-fidelity long-term digital human animation termed $\textbf{Soul}$, which generates semantically coherent videos from a single-frame portrait image, text prompts, and audio, achieving precise lip synchronization, vivid facial expressions, and robust identity preservation. We construct Soul-1M, containing 1 million finely annotated samples with a precise automated annotation pipeline (covering portrait, upper-body, full-body, and multi-person scenes) to mitigate data scarcity, and we carefully curate Soul-Bench for comprehensive and fair evaluation of audio-/text-guided animation methods. The model is built on the Wan2.2-5B backbone, integrating audio-injection layers and multiple training strategies together with threshold-aware codebook replacement to ensure long-term generation consistency. Meanwhile, step/CFG distillation and a lightweight VAE are used to optimize inference efficiency, achieving an 11.4$\times$ speedup with negligible quality loss. Extensive experiments show that Soul significantly outperforms current leading open-source and commercial models on video quality, video-text alignment, identity preservation, and lip-synchronization accuracy, demonstrating broad applicability in real-world scenarios such as virtual anchors and film production. Project page at https://zhangzjn.github.io/projects/Soul/
Disentangle Identity, Cooperate Emotion: Correlation-Aware Emotional Talking Portrait Generation
Apr 25, 2025Recent advances in Talking Head Generation (THG) have achieved impressive lip synchronization and visual quality through diffusion models; yet existing methods struggle to generate emotionally expressive portraits while preserving speaker identity. We identify three critical limitations in current emotional talking head generation: insufficient utilization of audio's inherent emotional cues, identity leakage in emotion representations, and isolated learning of emotion correlations. To address these challenges, we propose a novel framework dubbed as DICE-Talk, following the idea of disentangling identity with emotion, and then cooperating emotions with similar characteristics. First, we develop a disentangled emotion embedder that jointly models audio-visual emotional cues through cross-modal attention, representing emotions as identity-agnostic Gaussian distributions. Second, we introduce a correlation-enhanced emotion conditioning module with learnable Emotion Banks that explicitly capture inter-emotion relationships through vector quantization and attention-based feature aggregation. Third, we design an emotion discrimination objective that enforces affective consistency during the diffusion process through latent-space classification. Extensive experiments on MEAD and HDTF datasets demonstrate our method's superiority, outperforming state-of-the-art approaches in emotion accuracy while maintaining competitive lip-sync performance. Qualitative results and user studies further confirm our method's ability to generate identity-preserving portraits with rich, correlated emotional expressions that naturally adapt to unseen identities.
Sonic: Shifting Focus to Global Audio Perception in Portrait Animation
Nov 25, 2024



The study of talking face generation mainly explores the intricacies of synchronizing facial movements and crafting visually appealing, temporally-coherent animations. However, due to the limited exploration of global audio perception, current approaches predominantly employ auxiliary visual and spatial knowledge to stabilize the movements, which often results in the deterioration of the naturalness and temporal inconsistencies.Considering the essence of audio-driven animation, the audio signal serves as the ideal and unique priors to adjust facial expressions and lip movements, without resorting to interference of any visual signals. Based on this motivation, we propose a novel paradigm, dubbed as Sonic, to {s}hift f{o}cus on the exploration of global audio per{c}ept{i}o{n}.To effectively leverage global audio knowledge, we disentangle it into intra- and inter-clip audio perception and collaborate with both aspects to enhance overall perception.For the intra-clip audio perception, 1). \textbf{Context-enhanced audio learning}, in which long-range intra-clip temporal audio knowledge is extracted to provide facial expression and lip motion priors implicitly expressed as the tone and speed of speech. 2). \textbf{Motion-decoupled controller}, in which the motion of the head and expression movement are disentangled and independently controlled by intra-audio clips. Most importantly, for inter-clip audio perception, as a bridge to connect the intra-clips to achieve the global perception, \textbf{Time-aware position shift fusion}, in which the global inter-clip audio information is considered and fused for long-audio inference via through consecutively time-aware shifted windows. Extensive experiments demonstrate that the novel audio-driven paradigm outperform existing SOTA methodologies in terms of video quality, temporally consistency, lip synchronization precision, and motion diversity.
SVP: Style-Enhanced Vivid Portrait Talking Head Diffusion Model
Sep 05, 2024Talking Head Generation (THG), typically driven by audio, is an important and challenging task with broad application prospects in various fields such as digital humans, film production, and virtual reality. While diffusion model-based THG methods present high quality and stable content generation, they often overlook the intrinsic style which encompasses personalized features such as speaking habits and facial expressions of a video. As consequence, the generated video content lacks diversity and vividness, thus being limited in real life scenarios. To address these issues, we propose a novel framework named Style-Enhanced Vivid Portrait (SVP) which fully leverages style-related information in THG. Specifically, we first introduce the novel probabilistic style prior learning to model the intrinsic style as a Gaussian distribution using facial expressions and audio embedding. The distribution is learned through the 'bespoked' contrastive objective, effectively capturing the dynamic style information in each video. Then we finetune a pretrained Stable Diffusion (SD) model to inject the learned intrinsic style as a controlling signal via cross attention. Experiments show that our model generates diverse, vivid, and high-quality videos with flexible control over intrinsic styles, outperforming existing state-of-the-art methods.
RealTalk: Real-time and Realistic Audio-driven Face Generation with 3D Facial Prior-guided Identity Alignment Network
Jun 26, 2024Person-generic audio-driven face generation is a challenging task in computer vision. Previous methods have achieved remarkable progress in audio-visual synchronization, but there is still a significant gap between current results and practical applications. The challenges are two-fold: 1) Preserving unique individual traits for achieving high-precision lip synchronization. 2) Generating high-quality facial renderings in real-time performance. In this paper, we propose a novel generalized audio-driven framework RealTalk, which consists of an audio-to-expression transformer and a high-fidelity expression-to-face renderer. In the first component, we consider both identity and intra-personal variation features related to speaking lip movements. By incorporating cross-modal attention on the enriched facial priors, we can effectively align lip movements with audio, thus attaining greater precision in expression prediction. In the second component, we design a lightweight facial identity alignment (FIA) module which includes a lip-shape control structure and a face texture reference structure. This novel design allows us to generate fine details in real-time, without depending on sophisticated and inefficient feature alignment modules. Our experimental results, both quantitative and qualitative, on public datasets demonstrate the clear advantages of our method in terms of lip-speech synchronization and generation quality. Furthermore, our method is efficient and requires fewer computational resources, making it well-suited to meet the needs of practical applications.
High-Resolution GAN Inversion for Degraded Images in Large Diverse Datasets
Feb 07, 2023The last decades are marked by massive and diverse image data, which shows increasingly high resolution and quality. However, some images we obtained may be corrupted, affecting the perception and the application of downstream tasks. A generic method for generating a high-quality image from the degraded one is in demand. In this paper, we present a novel GAN inversion framework that utilizes the powerful generative ability of StyleGAN-XL for this problem. To ease the inversion challenge with StyleGAN-XL, Clustering \& Regularize Inversion (CRI) is proposed. Specifically, the latent space is firstly divided into finer-grained sub-spaces by clustering. Instead of initializing the inversion with the average latent vector, we approximate a centroid latent vector from the clusters, which generates an image close to the input image. Then, an offset with a regularization term is introduced to keep the inverted latent vector within a certain range. We validate our CRI scheme on multiple restoration tasks (i.e., inpainting, colorization, and super-resolution) of complex natural images, and show preferable quantitative and qualitative results. We further demonstrate our technique is robust in terms of data and different GAN models. To our best knowledge, we are the first to adopt StyleGAN-XL for generating high-quality natural images from diverse degraded inputs. Code is available at https://github.com/Booooooooooo/CRI.
Joint Learning Content and Degradation Aware Feature for Blind Super-Resolution
Aug 29, 2022
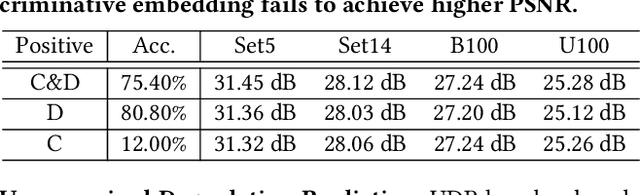
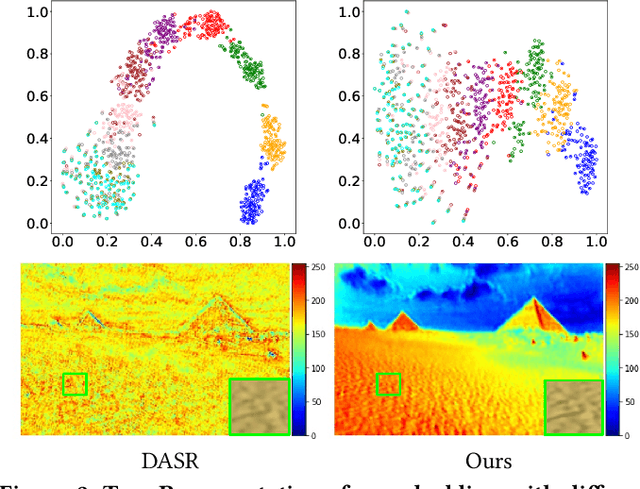
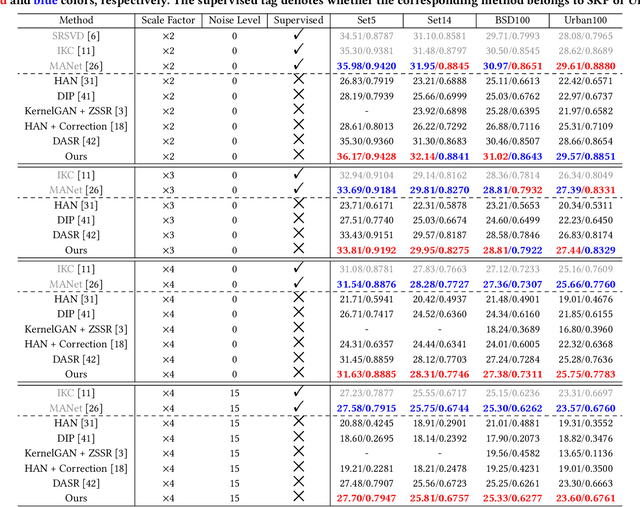
To achieve promising results on blind image super-resolution (SR), some attempts leveraged the low resolution (LR) images to predict the kernel and improve the SR performance. However, these Supervised Kernel Prediction (SKP) methods are impractical due to the unavailable real-world blur kernels. Although some Unsupervised Degradation Prediction (UDP) methods are proposed to bypass this problem, the \textit{inconsistency} between degradation embedding and SR feature is still challenging. By exploring the correlations between degradation embedding and SR feature, we observe that jointly learning the content and degradation aware feature is optimal. Based on this observation, a Content and Degradation aware SR Network dubbed CDSR is proposed. Specifically, CDSR contains three newly-established modules: (1) a Lightweight Patch-based Encoder (LPE) is applied to jointly extract content and degradation features; (2) a Domain Query Attention based module (DQA) is employed to adaptively reduce the inconsistency; (3) a Codebook-based Space Compress module (CSC) that can suppress the redundant information. Extensive experiments on several benchmarks demonstrate that the proposed CDSR outperforms the existing UDP models and achieves competitive performance on PSNR and SSIM even compared with the state-of-the-art SKP methods.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022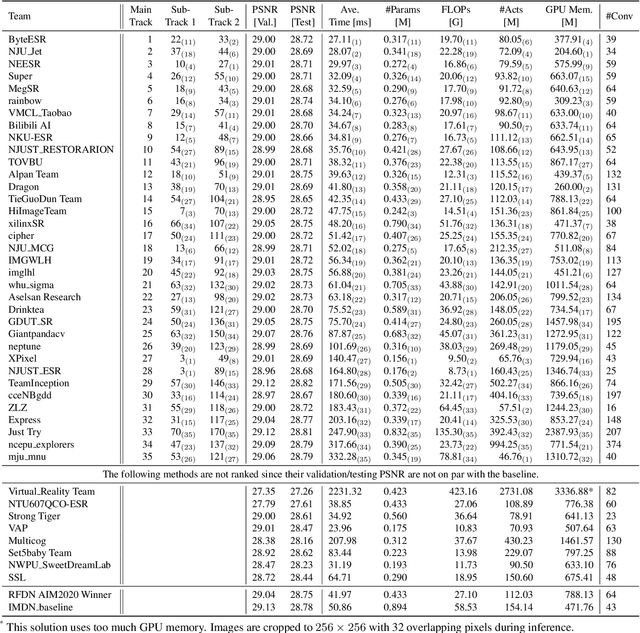
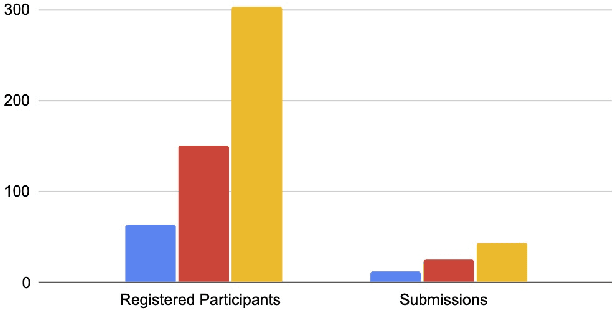
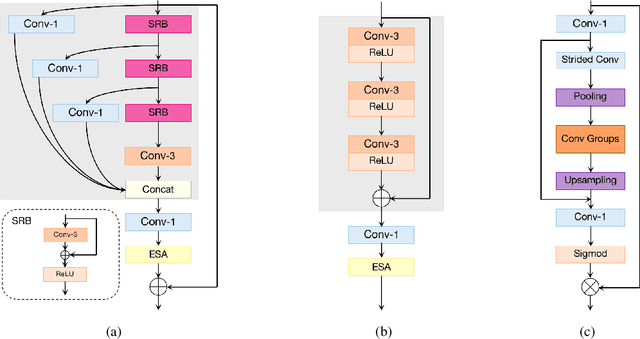
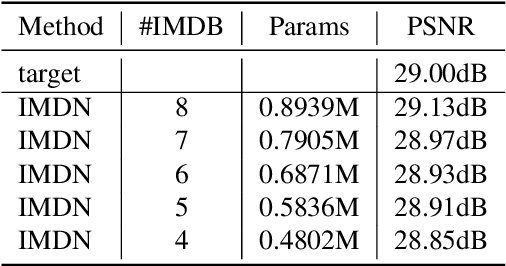
This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
Spectrum-to-Kernel Translation for Accurate Blind Image Super-Resolution
Oct 23, 2021


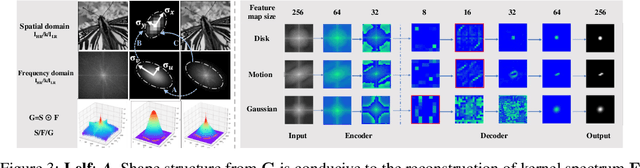
Deep-learning based Super-Resolution (SR) methods have exhibited promising performance under non-blind setting where blur kernel is known. However, blur kernels of Low-Resolution (LR) images in different practical applications are usually unknown. It may lead to significant performance drop when degradation process of training images deviates from that of real images. In this paper, we propose a novel blind SR framework to super-resolve LR images degraded by arbitrary blur kernel with accurate kernel estimation in frequency domain. To our best knowledge, this is the first deep learning method which conducts blur kernel estimation in frequency domain. Specifically, we first demonstrate that feature representation in frequency domain is more conducive for blur kernel reconstruction than in spatial domain. Next, we present a Spectrum-to-Kernel (S$2$K) network to estimate general blur kernels in diverse forms. We use a Conditional GAN (CGAN) combined with SR-oriented optimization target to learn the end-to-end translation from degraded images' spectra to unknown kernels. Extensive experiments on both synthetic and real-world images demonstrate that our proposed method sufficiently reduces blur kernel estimation error, thus enables the off-the-shelf non-blind SR methods to work under blind setting effectively, and achieves superior performance over state-of-the-art blind SR methods, averagely by 1.39dB, 0.48dB on commom blind SR setting (with Gaussian kernels) for scales $2\times$ and $4\times$, respectively.