 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymmetric Generative Recommendation via Multi-Expert Projection and Multi-Faceted Hierarchical Quantization
May 14, 2026Generative Recommendation (GenRec) models reformulate recommendation as a sequence generation task, representing items as discrete Semantic IDs used symmetrically as both inputs and prediction targets. We identify a critical dual-stage information bottleneck in this design: (1) the Input Bottleneck, where lossy quantization degrades fine-grained semantics, while popularity bias skews the learned representations toward frequent items, and (2) the Output Bottleneck, where imprecise discrete targets limit supervision quality. To address these issues, we propose AsymRec, an asymmetric continuous-discrete framework that decouples input and output representations. Specifically, Multi-expert Semantic Projection (MSP) maps continuous embeddings into the Transformer's hidden space via expert-specialized projections, preserving semantic richness and improving generalization to infrequent items. Multi-faceted Hierarchical Quantization (MHQ) constructs high-capacity, structured discrete targets through multi-view and multi-level quantization with semantic regularization, preventing dimensional collapse while retaining fine-grained distinctions. Extensive experiments demonstrate that AsymRec consistently outperforms state-of-the-art generative recommenders by an average of 15.8 %. The code will be released.
TokenFormer: Unify the Multi-Field and Sequential Recommendation Worlds
Apr 15, 2026Recommender systems have historically developed along two largely independent paradigms: feature interaction models for modeling correlations among multi-field categorical features, and sequential models for capturing user behavior dynamics from historical interaction sequences. Although recent trends attempt to bridge these paradigms within shared backbones, we empirically reveal that naive unifying these two branches may lead to a failure mode of Sequential Collapse Propagation (SCP). That is, the interaction with those dimensionally ill non-sequence fields leads to the dimensional collapse of the sequence features. To overcome this challenge, we propose TokenFormer, a unified recommendation architecture with the following innovations. First, we introduce a Bottom-Full-Top-Sliding (BFTS) attention scheme, which applies full self-attention in the lower layers and shrinking-window sliding attention in the upper layers. Second, we introduce a Non-Linear Interaction Representation (NLIR) that applies one-sided non-linear multiplicative transformations to the hidden states. Extensive experiments on public benchmarks and Tencent's advertising platform demonstrate state-of-the-art performance, while detailed analysis confirm that TokenFormer significantly improves dimensional robustness and representation discriminability under unified modeling.
EvolvingGS: High-Fidelity Streamable Volumetric Video via Evolving 3D Gaussian Representation
Mar 07, 2025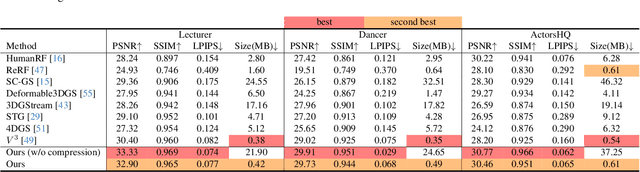
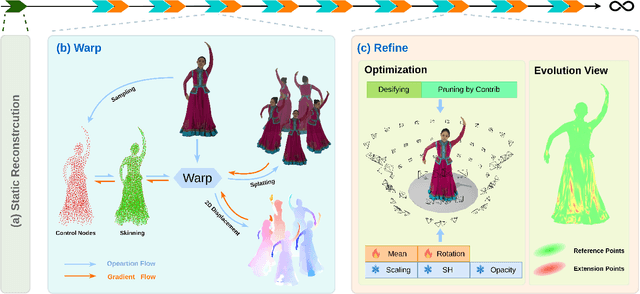
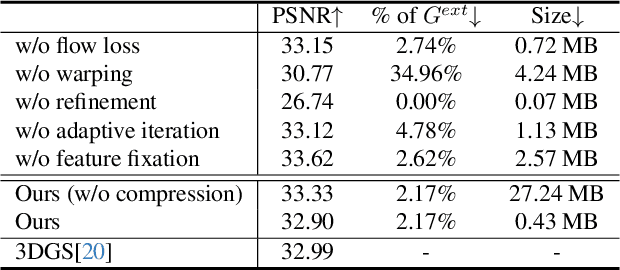

We have recently seen great progress in 3D scene reconstruction through explicit point-based 3D Gaussian Splatting (3DGS), notable for its high quality and fast rendering speed. However, reconstructing dynamic scenes such as complex human performances with long durations remains challenging. Prior efforts fall short of modeling a long-term sequence with drastic motions, frequent topology changes or interactions with props, and resort to segmenting the whole sequence into groups of frames that are processed independently, which undermines temporal stability and thereby leads to an unpleasant viewing experience and inefficient storage footprint. In view of this, we introduce EvolvingGS, a two-stage strategy that first deforms the Gaussian model to coarsely align with the target frame, and then refines it with minimal point addition/subtraction, particularly in fast-changing areas. Owing to the flexibility of the incrementally evolving representation, our method outperforms existing approaches in terms of both per-frame and temporal quality metrics while maintaining fast rendering through its purely explicit representation. Moreover, by exploiting temporal coherence between successive frames, we propose a simple yet effective compression algorithm that achieves over 50x compression rate. Extensive experiments on both public benchmarks and challenging custom datasets demonstrate that our method significantly advances the state-of-the-art in dynamic scene reconstruction, particularly for extended sequences with complex human performances.
MMAD: The First-Ever Comprehensive Benchmark for Multimodal Large Language Models in Industrial Anomaly Detection
Oct 12, 2024



In the field of industrial inspection, Multimodal Large Language Models (MLLMs) have a high potential to renew the paradigms in practical applications due to their robust language capabilities and generalization abilities. However, despite their impressive problem-solving skills in many domains, MLLMs' ability in industrial anomaly detection has not been systematically studied. To bridge this gap, we present MMAD, the first-ever full-spectrum MLLMs benchmark in industrial Anomaly Detection. We defined seven key subtasks of MLLMs in industrial inspection and designed a novel pipeline to generate the MMAD dataset with 39,672 questions for 8,366 industrial images. With MMAD, we have conducted a comprehensive, quantitative evaluation of various state-of-the-art MLLMs. The commercial models performed the best, with the average accuracy of GPT-4o models reaching 74.9%. However, this result falls far short of industrial requirements. Our analysis reveals that current MLLMs still have significant room for improvement in answering questions related to industrial anomalies and defects. We further explore two training-free performance enhancement strategies to help models improve in industrial scenarios, highlighting their promising potential for future research.
CAR: Controllable Autoregressive Modeling for Visual Generation
Oct 07, 2024



Controllable generation, which enables fine-grained control over generated outputs, has emerged as a critical focus in visual generative models. Currently, there are two primary technical approaches in visual generation: diffusion models and autoregressive models. Diffusion models, as exemplified by ControlNet and T2I-Adapter, offer advanced control mechanisms, whereas autoregressive models, despite showcasing impressive generative quality and scalability, remain underexplored in terms of controllability and flexibility. In this study, we introduce Controllable AutoRegressive Modeling (CAR), a novel, plug-and-play framework that integrates conditional control into multi-scale latent variable modeling, enabling efficient control generation within a pre-trained visual autoregressive model. CAR progressively refines and captures control representations, which are injected into each autoregressive step of the pre-trained model to guide the generation process. Our approach demonstrates excellent controllability across various types of conditions and delivers higher image quality compared to previous methods. Additionally, CAR achieves robust generalization with significantly fewer training resources compared to those required for pre-training the model. To the best of our knowledge, we are the first to propose a control framework for pre-trained autoregressive visual generation models.
Decision Boundary-aware Knowledge Consolidation Generates Better Instance-Incremental Learner
Jun 05, 2024Instance-incremental learning (IIL) focuses on learning continually with data of the same classes. Compared to class-incremental learning (CIL), the IIL is seldom explored because IIL suffers less from catastrophic forgetting (CF). However, besides retaining knowledge, in real-world deployment scenarios where the class space is always predefined, continual and cost-effective model promotion with the potential unavailability of previous data is a more essential demand. Therefore, we first define a new and more practical IIL setting as promoting the model's performance besides resisting CF with only new observations. Two issues have to be tackled in the new IIL setting: 1) the notorious catastrophic forgetting because of no access to old data, and 2) broadening the existing decision boundary to new observations because of concept drift. To tackle these problems, our key insight is to moderately broaden the decision boundary to fail cases while retain old boundary. Hence, we propose a novel decision boundary-aware distillation method with consolidating knowledge to teacher to ease the student learning new knowledge. We also establish the benchmarks on existing datasets Cifar-100 and ImageNet. Notably, extensive experiments demonstrate that the teacher model can be a better incremental learner than the student model, which overturns previous knowledge distillation-based methods treating student as the main role.
Joint Learning Content and Degradation Aware Feature for Blind Super-Resolution
Aug 29, 2022
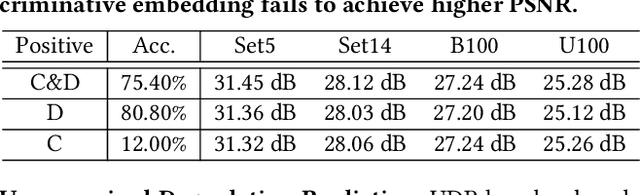
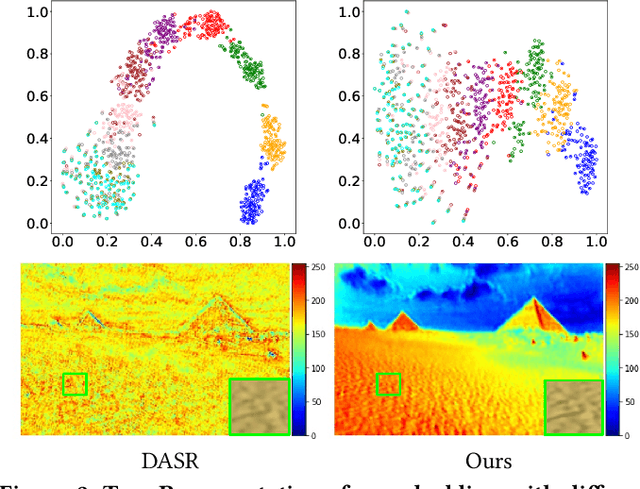
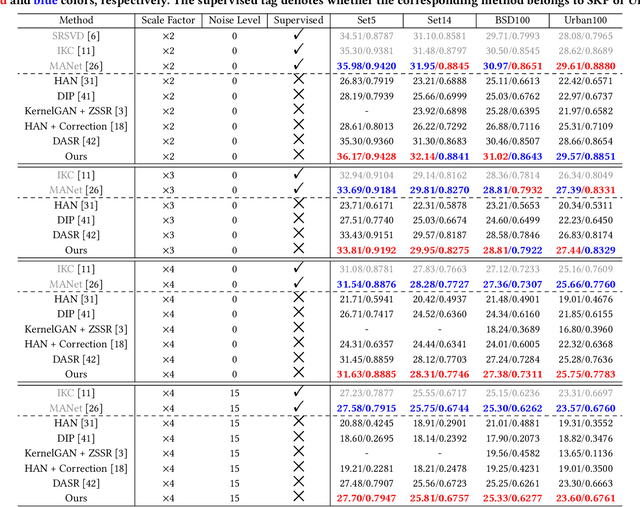
To achieve promising results on blind image super-resolution (SR), some attempts leveraged the low resolution (LR) images to predict the kernel and improve the SR performance. However, these Supervised Kernel Prediction (SKP) methods are impractical due to the unavailable real-world blur kernels. Although some Unsupervised Degradation Prediction (UDP) methods are proposed to bypass this problem, the \textit{inconsistency} between degradation embedding and SR feature is still challenging. By exploring the correlations between degradation embedding and SR feature, we observe that jointly learning the content and degradation aware feature is optimal. Based on this observation, a Content and Degradation aware SR Network dubbed CDSR is proposed. Specifically, CDSR contains three newly-established modules: (1) a Lightweight Patch-based Encoder (LPE) is applied to jointly extract content and degradation features; (2) a Domain Query Attention based module (DQA) is employed to adaptively reduce the inconsistency; (3) a Codebook-based Space Compress module (CSC) that can suppress the redundant information. Extensive experiments on several benchmarks demonstrate that the proposed CDSR outperforms the existing UDP models and achieves competitive performance on PSNR and SSIM even compared with the state-of-the-art SKP methods.
Thunder: Thumbnail based Fast Lightweight Image Denoising Network
May 24, 2022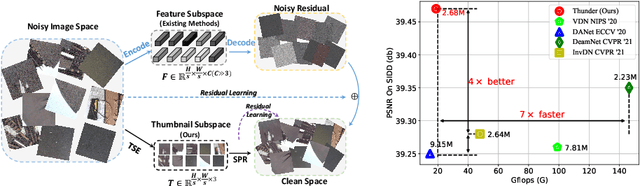
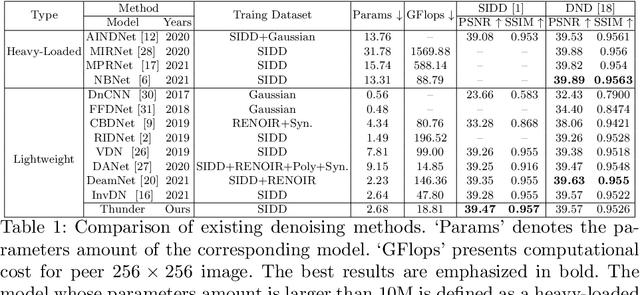
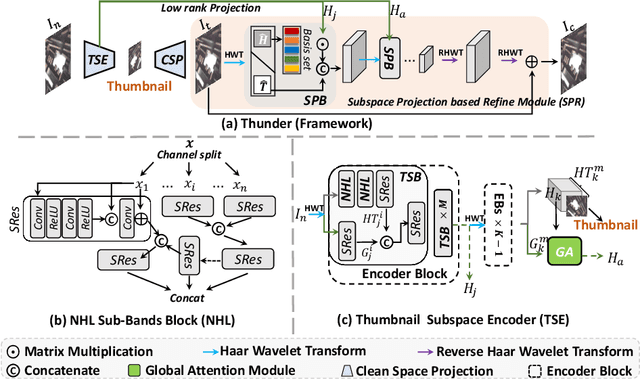
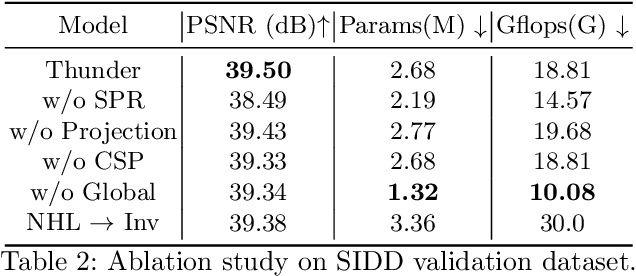
To achieve promising results on removing noise from real-world images, most of existing denoising networks are formulated with complex network structure, making them impractical for deployment. Some attempts focused on reducing the number of filters and feature channels but suffered from large performance loss, and a more practical and lightweight denoising network with fast inference speed is of high demand. To this end, a \textbf{Thu}mb\textbf{n}ail based \textbf{D}\textbf{e}noising Netwo\textbf{r}k dubbed Thunder, is proposed and implemented as a lightweight structure for fast restoration without comprising the denoising capabilities. Specifically, the Thunder model contains two newly-established modules: (1) a wavelet-based Thumbnail Subspace Encoder (TSE) which can leverage sub-bands correlation to provide an approximate thumbnail based on the low-frequent feature; (2) a Subspace Projection based Refine Module (SPR) which can restore the details for thumbnail progressively based on the subspace projection approach. Extensive experiments have been carried out on two real-world denoising benchmarks, demonstrating that the proposed Thunder outperforms the existing lightweight models and achieves competitive performance on PSNR and SSIM when compared with the complex designs.
Fast Camera Image Denoising on Mobile GPUs with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021

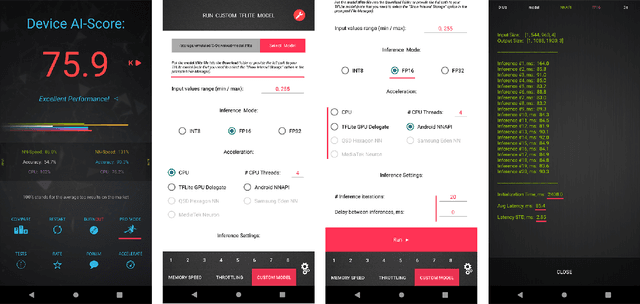
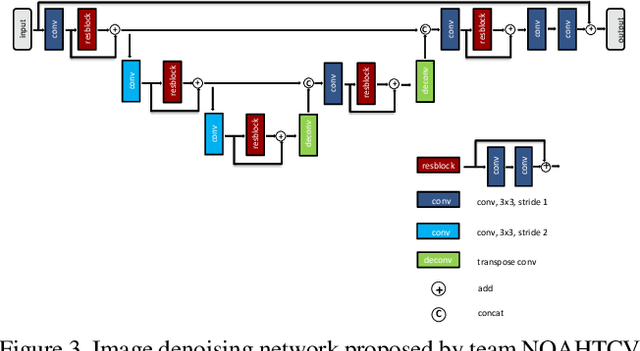
Image denoising is one of the most critical problems in mobile photo processing. While many solutions have been proposed for this task, they are usually working with synthetic data and are too computationally expensive to run on mobile devices. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based image denoising solution that can demonstrate high efficiency on smartphone GPUs. For this, the participants were provided with a novel large-scale dataset consisting of noisy-clean image pairs captured in the wild. The runtime of all models was evaluated on the Samsung Exynos 2100 chipset with a powerful Mali GPU capable of accelerating floating-point and quantized neural networks. The proposed solutions are fully compatible with any mobile GPU and are capable of processing 480p resolution images under 40-80 ms while achieving high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.