 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSHA: A Benchmark for Visual Language Models in Trustworthy Safety Hazard Assessment Scenarios
Mar 31, 2026Recent advances in vision-language models (VLMs) have accelerated their application to indoor safety hazards assessment. However, existing benchmarks suffer from three fundamental limitations: (1) heavy reliance on synthetic datasets constructed via simulation software, creating a significant domain gap with real-world environments; (2) oversimplified safety tasks with artificial constraints on hazard and scene types, thereby limiting model generalization; and (3) absence of rigorous evaluation protocols to thoroughly assess model capabilities in complex home safety scenarios. To address these challenges, we introduce TSHA (\textbf{T}rustworthy \textbf{S}afety \textbf{H}azards \textbf{A}ssessment), a comprehensive benchmark comprising 81,809 carefully curated training samples drawn from four complementary sources: existing indoor datasets, internet images, AIGC images, and newly captured images. This benchmark set also includes a highly challenging test set with 1707 samples, comprising not only a carefully selected subset from the training distribution but also newly added videos and panoramic images containing multiple safety hazards, used to evaluate the model's robustness in complex safety scenarios. Extensive experiments on 23 popular VLMs demonstrate that current VLMs lack robust capabilities for safety hazard assessment. Importantly, models trained on the TSHA training set not only achieve a significant performance improvement of up to +18.3 points on the TSHA test set but also exhibit enhanced generalizability across other benchmarks, underscoring the substantial contribution and importance of the TSHA benchmark.
TAME: A Trustworthy Test-Time Evolution of Agent Memory with Systematic Benchmarking
Feb 03, 2026Test-time evolution of agent memory serves as a pivotal paradigm for achieving AGI by bolstering complex reasoning through experience accumulation. However, even during benign task evolution, agent safety alignment remains vulnerable-a phenomenon known as Agent Memory Misevolution. To evaluate this phenomenon, we construct the Trust-Memevo benchmark to assess multi-dimensional trustworthiness during benign task evolution, revealing an overall decline in trustworthiness across various task domains and evaluation settings. To address this issue, we propose TAME, a dual-memory evolutionary framework that separately evolves executor memory to improve task performance by distilling generalizable methodologies, and evaluator memory to refine assessments of both safety and task utility based on historical feedback. Through a closed loop of memory filtering, draft generation, trustworthy refinement, execution, and dual-track memory updating, TAME preserves trustworthiness without sacrificing utility. Experiments demonstrate that TAME mitigates misevolution, achieving a joint improvement in both trustworthiness and task performance.
OSNIP: Breaking the Privacy-Utility-Efficiency Trilemma in LLM Inference via Obfuscated Semantic Null Space
Jan 30, 2026We propose Obfuscated Semantic Null space Injection for Privacy (OSNIP), a lightweight client-side encryption framework for privacy-preserving LLM inference. Generalizing the geometric intuition of linear kernels to the high-dimensional latent space of LLMs, we formally define the ``Obfuscated Semantic Null Space'', a high-dimensional regime that preserves semantic fidelity while enforcing near-orthogonality to the original embedding. By injecting perturbations that project the original embedding into this space, OSNIP ensures privacy without any post-processing. Furthermore, OSNIP employs a key-dependent stochastic mapping that synthesizes individualized perturbation trajectories unique to each user. Evaluations on 12 generative and classification benchmarks show that OSNIP achieves state-of-the-art performance, sharply reducing attack success rates while maintaining strong model utility under strict security constraints.
Revisiting Benchmark and Assessment: An Agent-based Exploratory Dynamic Evaluation Framework for LLMs
Oct 15, 2024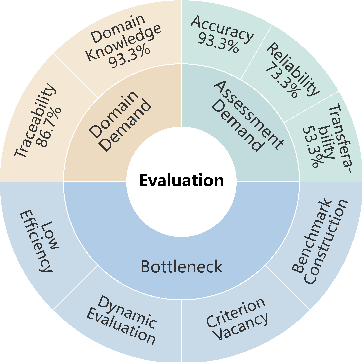



While various vertical domain large language models (LLMs) have been developed, the challenge of automatically evaluating their performance across different domains remains significant in addressing real-world user needs. Current benchmark-based evaluation methods exhibit rigid, purposeless interactions and rely on pre-collected static datasets that are costly to build, inflexible across domains, and misaligned with practical user needs. To address this, we revisit the evaluation components and introduce two definitions: **Benchmark+**, which extends traditional QA benchmarks into a more flexible ``strategy-criterion'' format; and **Assessment+**, which enhances the interaction process for greater exploration and enables both quantitative metrics and qualitative insights that capture nuanced target LLM behaviors from richer multi-turn interactions. We propose an agent-based evaluation framework called *TestAgent*, which implements these two concepts through retrieval augmented generation and reinforcement learning. Experiments on tasks ranging from building vertical domain evaluation from scratch to activating existing benchmarks demonstrate the effectiveness of *TestAgent* across various scenarios. We believe this work offers an interesting perspective on automatic evaluation for LLMs.
Real-IAD: A Real-World Multi-View Dataset for Benchmarking Versatile Industrial Anomaly Detection
Mar 19, 2024Industrial anomaly detection (IAD) has garnered significant attention and experienced rapid development. However, the recent development of IAD approach has encountered certain difficulties due to dataset limitations. On the one hand, most of the state-of-the-art methods have achieved saturation (over 99% in AUROC) on mainstream datasets such as MVTec, and the differences of methods cannot be well distinguished, leading to a significant gap between public datasets and actual application scenarios. On the other hand, the research on various new practical anomaly detection settings is limited by the scale of the dataset, posing a risk of overfitting in evaluation results. Therefore, we propose a large-scale, Real-world, and multi-view Industrial Anomaly Detection dataset, named Real-IAD, which contains 150K high-resolution images of 30 different objects, an order of magnitude larger than existing datasets. It has a larger range of defect area and ratio proportions, making it more challenging than previous datasets. To make the dataset closer to real application scenarios, we adopted a multi-view shooting method and proposed sample-level evaluation metrics. In addition, beyond the general unsupervised anomaly detection setting, we propose a new setting for Fully Unsupervised Industrial Anomaly Detection (FUIAD) based on the observation that the yield rate in industrial production is usually greater than 60%, which has more practical application value. Finally, we report the results of popular IAD methods on the Real-IAD dataset, providing a highly challenging benchmark to promote the development of the IAD field.
UniM-OV3D: Uni-Modality Open-Vocabulary 3D Scene Understanding with Fine-Grained Feature Representation
Jan 31, 2024



3D open-vocabulary scene understanding aims to recognize arbitrary novel categories beyond the base label space. However, existing works not only fail to fully utilize all the available modal information in the 3D domain but also lack sufficient granularity in representing the features of each modality. In this paper, we propose a unified multimodal 3D open-vocabulary scene understanding network, namely UniM-OV3D, which aligns point clouds with image, language and depth. To better integrate global and local features of the point clouds, we design a hierarchical point cloud feature extraction module that learns comprehensive fine-grained feature representations. Further, to facilitate the learning of coarse-to-fine point-semantic representations from captions, we propose the utilization of hierarchical 3D caption pairs, capitalizing on geometric constraints across various viewpoints of 3D scenes. Extensive experimental results demonstrate the effectiveness and superiority of our method in open-vocabulary semantic and instance segmentation, which achieves state-of-the-art performance on both indoor and outdoor benchmarks such as ScanNet, ScanNet200, S3IDS and nuScenes. Code is available at https://github.com/hithqd/UniM-OV3D.
Dual Path Transformer with Partition Attention
May 24, 2023



This paper introduces a novel attention mechanism, called dual attention, which is both efficient and effective. The dual attention mechanism consists of two parallel components: local attention generated by Convolutional Neural Networks (CNNs) and long-range attention generated by Vision Transformers (ViTs). To address the high computational complexity and memory footprint of vanilla Multi-Head Self-Attention (MHSA), we introduce a novel Multi-Head Partition-wise Attention (MHPA) mechanism. The partition-wise attention approach models both intra-partition and inter-partition attention simultaneously. Building on the dual attention block and partition-wise attention mechanism, we present a hierarchical vision backbone called DualFormer. We evaluate the effectiveness of our model on several computer vision tasks, including image classification on ImageNet, object detection on COCO, and semantic segmentation on Cityscapes. Specifically, the proposed DualFormer-XS achieves 81.5\% top-1 accuracy on ImageNet, outperforming the recent state-of-the-art MPViT-XS by 0.6\% top-1 accuracy with much higher throughput.
Joint Learning Content and Degradation Aware Feature for Blind Super-Resolution
Aug 29, 2022
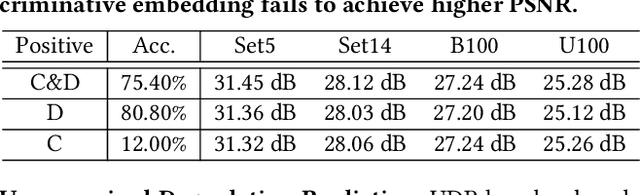
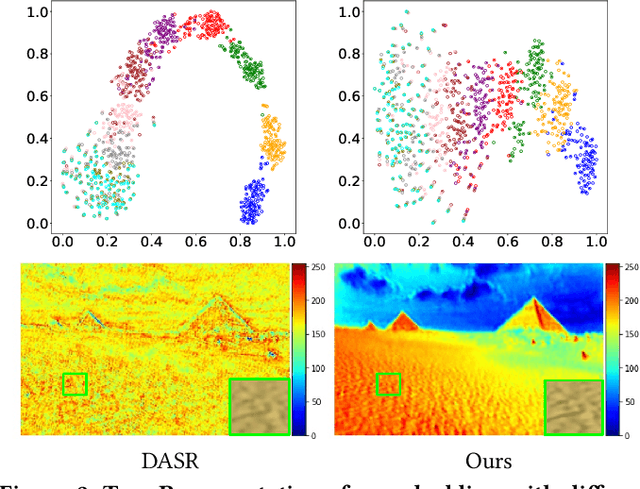
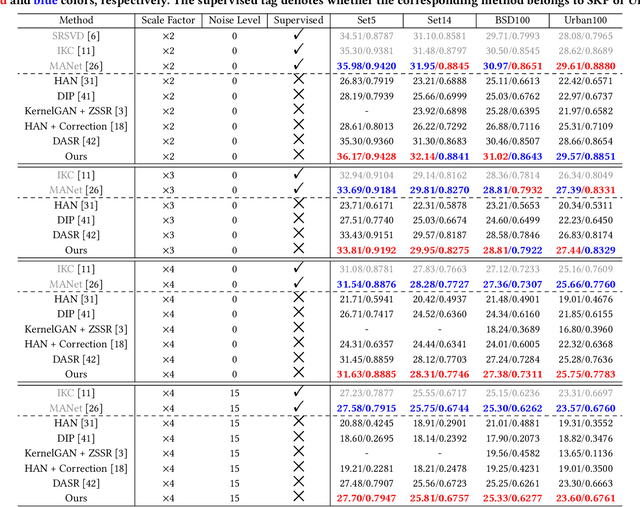
To achieve promising results on blind image super-resolution (SR), some attempts leveraged the low resolution (LR) images to predict the kernel and improve the SR performance. However, these Supervised Kernel Prediction (SKP) methods are impractical due to the unavailable real-world blur kernels. Although some Unsupervised Degradation Prediction (UDP) methods are proposed to bypass this problem, the \textit{inconsistency} between degradation embedding and SR feature is still challenging. By exploring the correlations between degradation embedding and SR feature, we observe that jointly learning the content and degradation aware feature is optimal. Based on this observation, a Content and Degradation aware SR Network dubbed CDSR is proposed. Specifically, CDSR contains three newly-established modules: (1) a Lightweight Patch-based Encoder (LPE) is applied to jointly extract content and degradation features; (2) a Domain Query Attention based module (DQA) is employed to adaptively reduce the inconsistency; (3) a Codebook-based Space Compress module (CSC) that can suppress the redundant information. Extensive experiments on several benchmarks demonstrate that the proposed CDSR outperforms the existing UDP models and achieves competitive performance on PSNR and SSIM even compared with the state-of-the-art SKP methods.