 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCP-CLIP:A Coarse-to-Fine Framework for Open-Vocabulary Semantic Segmentation with Dual Interaction
Mar 14, 2026The recent years have witnessed the remarkable development for open-vocabulary semantic segmentation (OVSS) using visual-language foundation models, yet still suffer from following fundamental challenges: (1) insufficient cross-modal communications between textual and visual spaces, and (2) significant computational costs from the interactions with massive number of categories. To address these issues, this paper describes a novel coarse-to-fine framework, called DCP-CLIP, for OVSS. Unlike prior efforts that mainly relied on pre-established category content and the inherent spatial-class interaction capability of CLIP, we dynamic constructing category-relevant textual features and explicitly models dual interactions between spatial image features and textual class semantics. Specifically, we first leverage CLIP's open-vocabulary recognition capability to identify semantic categories relevant to the image context, upon which we dynamically generate corresponding textual features to serve as initial textual guidance. Subsequently, we conduct a coarse segmentation by cross-modally integrating semantic information from textual guidance into the visual representations and achieve refined segmentation by integrating spatially enriched features from the encoder to recover fine-grained details and enhance spatial resolution. In final, we leverage spatial information from the segmentation side to refine category predictions for each mask, facilitating more precise semantic labeling. Experiments on multiple OVSS benchmarks demonstrate that DCP-CLIP outperforms existing methods by delivering both higher accuracy and greater efficiency.
IGASA: Integrated Geometry-Aware and Skip-Attention Modules for Enhanced Point Cloud Registration
Mar 13, 2026Point cloud registration (PCR) is a fundamental task in 3D vision and provides essential support for applications such as autonomous driving, robotics, and environmental modeling. Despite its widespread use, existing methods often fail when facing real-world challenges like heavy noise, significant occlusions, and large-scale transformations. These limitations frequently result in compromised registration accuracy and insufficient robustness in complex environments. In this paper, we propose IGASA as a novel registration framework constructed upon a Hierarchical Pyramid Architecture (HPA) designed for robust multi-scale feature extraction and fusion. The framework integrates two pivotal components consisting of the Hierarchical Cross-Layer Attention (HCLA) module and the Iterative Geometry-Aware Refinement (IGAR) module. The HCLA module utilizes skip attention mechanisms to align multi-resolution features and enhance local geometric consistency. Simultaneously, the IGAR module is designed for the fine matching phase by leveraging reliable correspondences established during coarse matching. This synergistic integration within the architecture allows IGASA to adapt effectively to diverse point cloud structures and intricate transformations. We evaluate the performance of IGASA on four widely recognized benchmark datasets including 3D(Lo)Match, KITTI, and nuScenes. Our extensive experiments consistently demonstrate that IGASA significantly surpasses state-of-the-art methods and achieves notable improvements in registration accuracy. This work provides a robust foundation for advancing point cloud registration techniques while offering valuable insights for practical 3D vision applications. The code for IGASA is available in \href{https://github.com/DongXu-Zhang/IGASA}{https://github.com/DongXu-Zhang/IGASA}.
GeoLoco: Leveraging 3D Geometric Priors from Visual Foundation Model for Robust RGB-Only Humanoid Locomotion
Mar 08, 2026The prevailing paradigm of perceptive humanoid locomotion relies heavily on active depth sensors. However, this depth-centric approach fundamentally discards the rich semantic and dense appearance cues of the visual world, severing low-level control from the high-level reasoning essential for general embodied intelligence. While monocular RGB offers a ubiquitous, information-dense alternative, end-to-end reinforcement learning from raw 2D pixels suffers from extreme sample inefficiency and catastrophic sim-to-real collapse due to the inherent loss of geometric scale. To break this deadlock, we propose GeoLoco, a purely RGB-driven locomotion framework that conceptualizes monocular images as high-dimensional 3D latent representations by harnessing the powerful geometric priors of a frozen, scale-aware Visual Foundation Model (VFM). Rather than naive feature concatenation, we design a proprioceptive-query multi-head cross-attention mechanism that dynamically attends to task-critical topological features conditioned on the robot's real-time gait phase. Crucially, to prevent the policy from overfitting to superficial textures, we introduce a dual-head auxiliary learning scheme. This explicit regularization forces the high-dimensional latent space to strictly align with the physical terrain geometry, ensuring robust zero-shot sim-to-real transfer. Trained exclusively in simulation, GeoLoco achieves robust zero-shot transfer to the Unitree G1 humanoid and successfully negotiates challenging terrains.
Latent-Space Autoregressive World Model for Efficient and Robust Image-Goal Navigation
Nov 14, 2025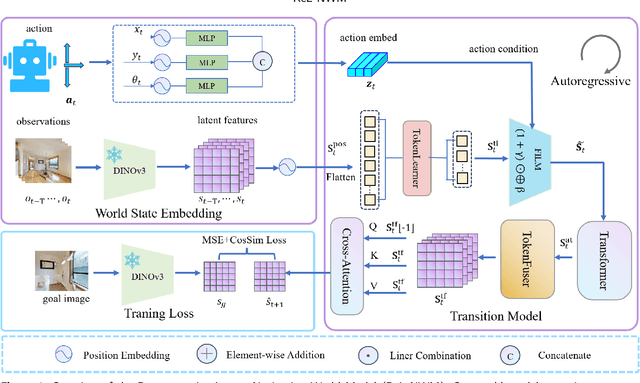
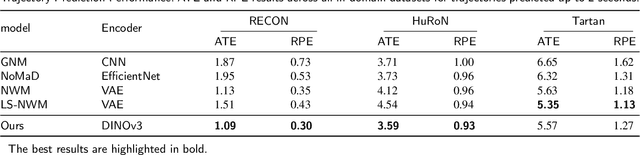

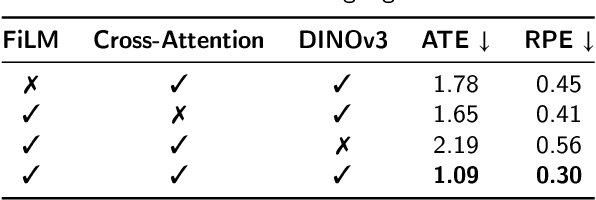
Traditional navigation methods rely heavily on accurate localization and mapping. In contrast, world models that capture environmental dynamics in latent space have opened up new perspectives for navigation tasks, enabling systems to move beyond traditional multi-module pipelines. However, world model often suffers from high computational costs in both training and inference. To address this, we propose LS-NWM - a lightweight latent space navigation world model that is trained and operates entirely in latent space, compared to the state-of-the-art baseline, our method reduces training time by approximately 3.2x and planning time by about 447x,while further improving navigation performance with a 35% higher SR and an 11% higher SPL. The key idea is that accurate pixel-wise environmental prediction is unnecessary for navigation. Instead, the model predicts future latent states based on current observational features and action inputs, then performs path planning and decision-making within this compact representation, significantly improving computational efficiency. By incorporating an autoregressive multi-frame prediction strategy during training, the model effectively captures long-term spatiotemporal dependencies, thereby enhancing navigation performance in complex scenarios. Experimental results demonstrate that our method achieves state-of-the-art navigation performance while maintaining a substantial efficiency advantage over existing approaches.
Dual-Arm Hierarchical Planning for Laboratory Automation: Vibratory Sieve Shaker Operations
Sep 18, 2025
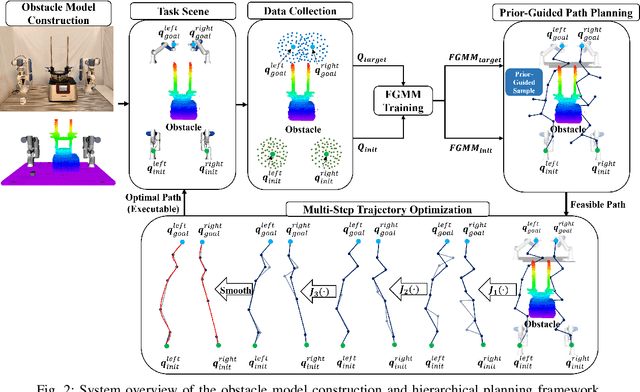
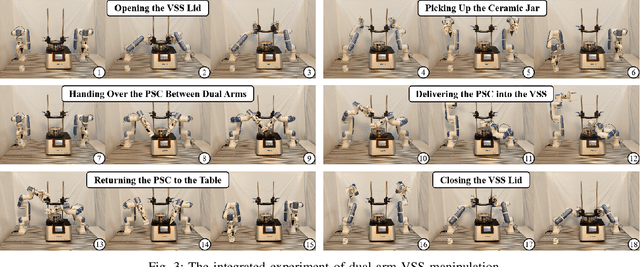
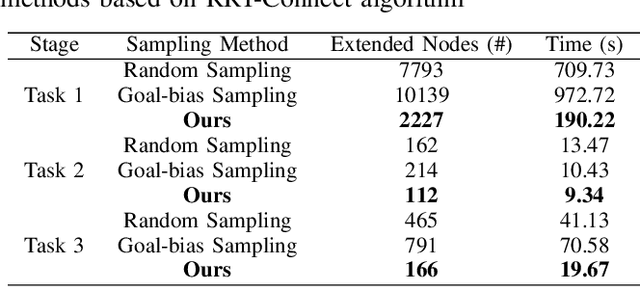
This paper addresses the challenges of automating vibratory sieve shaker operations in a materials laboratory, focusing on three critical tasks: 1) dual-arm lid manipulation in 3 cm clearance spaces, 2) bimanual handover in overlapping workspaces, and 3) obstructed powder sample container delivery with orientation constraints. These tasks present significant challenges, including inefficient sampling in narrow passages, the need for smooth trajectories to prevent spillage, and suboptimal paths generated by conventional methods. To overcome these challenges, we propose a hierarchical planning framework combining Prior-Guided Path Planning and Multi-Step Trajectory Optimization. The former uses a finite Gaussian mixture model to improve sampling efficiency in narrow passages, while the latter refines paths by shortening, simplifying, imposing joint constraints, and B-spline smoothing. Experimental results demonstrate the framework's effectiveness: planning time is reduced by up to 80.4%, and waypoints are decreased by 89.4%. Furthermore, the system completes the full vibratory sieve shaker operation workflow in a physical experiment, validating its practical applicability for complex laboratory automation.
Grasp Like Humans: Learning Generalizable Multi-Fingered Grasping from Human Proprioceptive Sensorimotor Integration
Sep 10, 2025



Tactile and kinesthetic perceptions are crucial for human dexterous manipulation, enabling reliable grasping of objects via proprioceptive sensorimotor integration. For robotic hands, even though acquiring such tactile and kinesthetic feedback is feasible, establishing a direct mapping from this sensory feedback to motor actions remains challenging. In this paper, we propose a novel glove-mediated tactile-kinematic perception-prediction framework for grasp skill transfer from human intuitive and natural operation to robotic execution based on imitation learning, and its effectiveness is validated through generalized grasping tasks, including those involving deformable objects. Firstly, we integrate a data glove to capture tactile and kinesthetic data at the joint level. The glove is adaptable for both human and robotic hands, allowing data collection from natural human hand demonstrations across different scenarios. It ensures consistency in the raw data format, enabling evaluation of grasping for both human and robotic hands. Secondly, we establish a unified representation of multi-modal inputs based on graph structures with polar coordinates. We explicitly integrate the morphological differences into the designed representation, enhancing the compatibility across different demonstrators and robotic hands. Furthermore, we introduce the Tactile-Kinesthetic Spatio-Temporal Graph Networks (TK-STGN), which leverage multidimensional subgraph convolutions and attention-based LSTM layers to extract spatio-temporal features from graph inputs to predict node-based states for each hand joint. These predictions are then mapped to final commands through a force-position hybrid mapping.
Probabilistic Temporal Masked Attention for Cross-view Online Action Detection
Aug 23, 2025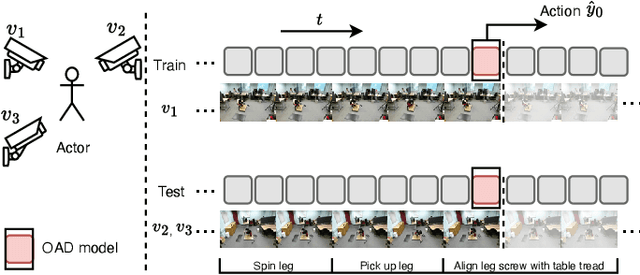
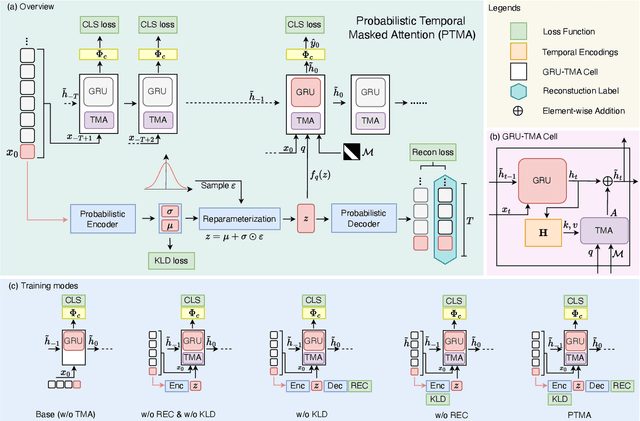
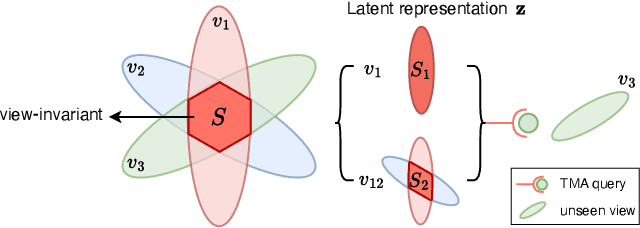
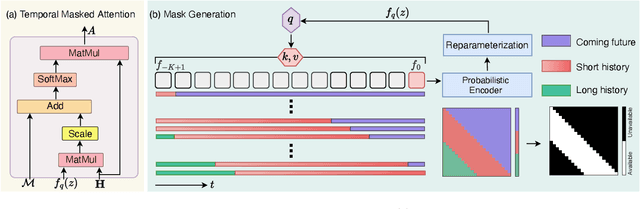
As a critical task in video sequence classification within computer vision, Online Action Detection (OAD) has garnered significant attention. The sensitivity of mainstream OAD models to varying video viewpoints often hampers their generalization when confronted with unseen sources. To address this limitation, we propose a novel Probabilistic Temporal Masked Attention (PTMA) model, which leverages probabilistic modeling to derive latent compressed representations of video frames in a cross-view setting. The PTMA model incorporates a GRU-based temporal masked attention (TMA) cell, which leverages these representations to effectively query the input video sequence, thereby enhancing information interaction and facilitating autoregressive frame-level video analysis. Additionally, multi-view information can be integrated into the probabilistic modeling to facilitate the extraction of view-invariant features. Experiments conducted under three evaluation protocols: cross-subject (cs), cross-view (cv), and cross-subject-view (csv) show that PTMA achieves state-of-the-art performance on the DAHLIA, IKEA ASM, and Breakfast datasets.
SurfAAV: Design and Implementation of a Novel Multimodal Surfing Aquatic-Aerial Vehicle
Jun 18, 2025



Despite significant advancements in the research of aquatic-aerial robots, existing configurations struggle to efficiently perform underwater, surface, and aerial movement simultaneously. In this paper, we propose a novel multimodal surfing aquatic-aerial vehicle, SurfAAV, which efficiently integrates underwater navigation, surface gliding, and aerial flying capabilities. Thanks to the design of the novel differential thrust vectoring hydrofoil, SurfAAV can achieve efficient surface gliding and underwater navigation without the need for a buoyancy adjustment system. This design provides flexible operational capabilities for both surface and underwater tasks, enabling the robot to quickly carry out underwater monitoring activities. Additionally, when it is necessary to reach another water body, SurfAAV can switch to aerial mode through a gliding takeoff, flying to the target water area to perform corresponding tasks. The main contribution of this letter lies in proposing a new solution for underwater, surface, and aerial movement, designing a novel hybrid prototype concept, developing the required control laws, and validating the robot's ability to successfully perform surface gliding and gliding takeoff. SurfAAV achieves a maximum surface gliding speed of 7.96 m/s and a maximum underwater speed of 3.1 m/s. The prototype's surface gliding maneuverability and underwater cruising maneuverability both exceed those of existing aquatic-aerial vehicles.
UniDetox: Universal Detoxification of Large Language Models via Dataset Distillation
Apr 29, 2025We present UniDetox, a universally applicable method designed to mitigate toxicity across various large language models (LLMs). Previous detoxification methods are typically model-specific, addressing only individual models or model families, and require careful hyperparameter tuning due to the trade-off between detoxification efficacy and language modeling performance. In contrast, UniDetox provides a detoxification technique that can be universally applied to a wide range of LLMs without the need for separate model-specific tuning. Specifically, we propose a novel and efficient dataset distillation technique for detoxification using contrastive decoding. This approach distills detoxifying representations in the form of synthetic text data, enabling universal detoxification of any LLM through fine-tuning with the distilled text. Our experiments demonstrate that the detoxifying text distilled from GPT-2 can effectively detoxify larger models, including OPT, Falcon, and LLaMA-2. Furthermore, UniDetox eliminates the need for separate hyperparameter tuning for each model, as a single hyperparameter configuration can be seamlessly applied across different models. Additionally, analysis of the detoxifying text reveals a reduction in politically biased content, providing insights into the attributes necessary for effective detoxification of LLMs.
UGNA-VPR: A Novel Training Paradigm for Visual Place Recognition Based on Uncertainty-Guided NeRF Augmentation
Mar 27, 2025
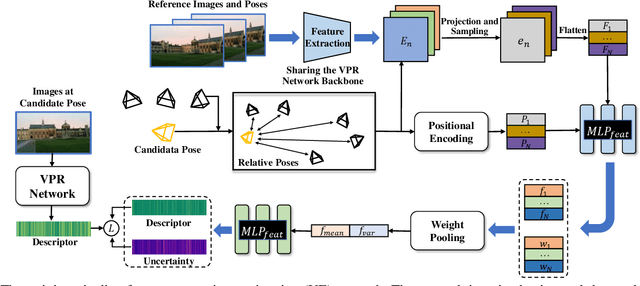
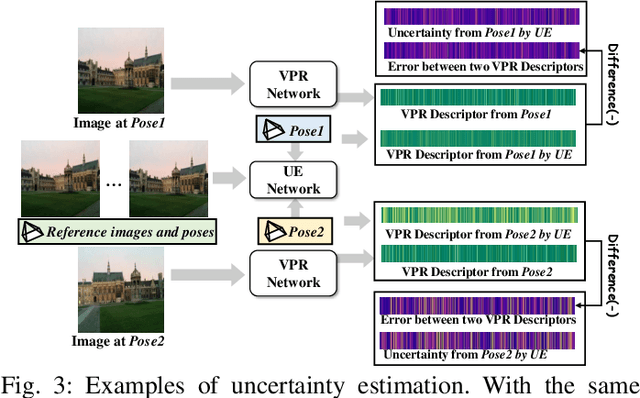
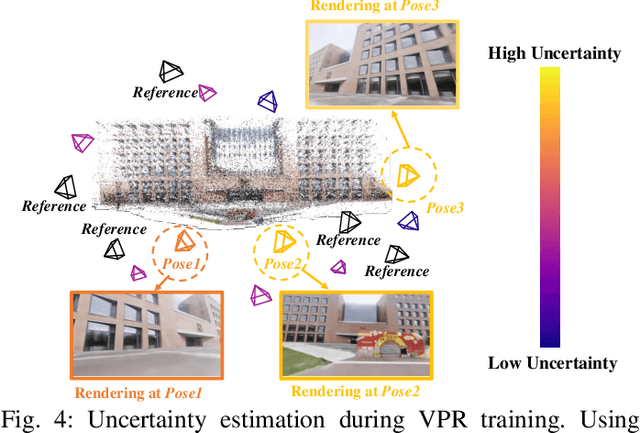
Visual place recognition (VPR) is crucial for robots to identify previously visited locations, playing an important role in autonomous navigation in both indoor and outdoor environments. However, most existing VPR datasets are limited to single-viewpoint scenarios, leading to reduced recognition accuracy, particularly in multi-directional driving or feature-sparse scenes. Moreover, obtaining additional data to mitigate these limitations is often expensive. This paper introduces a novel training paradigm to improve the performance of existing VPR networks by enhancing multi-view diversity within current datasets through uncertainty estimation and NeRF-based data augmentation. Specifically, we initially train NeRF using the existing VPR dataset. Then, our devised self-supervised uncertainty estimation network identifies places with high uncertainty. The poses of these uncertain places are input into NeRF to generate new synthetic observations for further training of VPR networks. Additionally, we propose an improved storage method for efficient organization of augmented and original training data. We conducted extensive experiments on three datasets and tested three different VPR backbone networks. The results demonstrate that our proposed training paradigm significantly improves VPR performance by fully utilizing existing data, outperforming other training approaches. We further validated the effectiveness of our approach on self-recorded indoor and outdoor datasets, consistently demonstrating superior results. Our dataset and code have been released at \href{https://github.com/nubot-nudt/UGNA-VPR}{https://github.com/nubot-nudt/UGNA-VPR}.