 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEVDiffLoc: End-to-End LiDAR Global Localization in BEV View based on Diffusion Model
Paper and Code
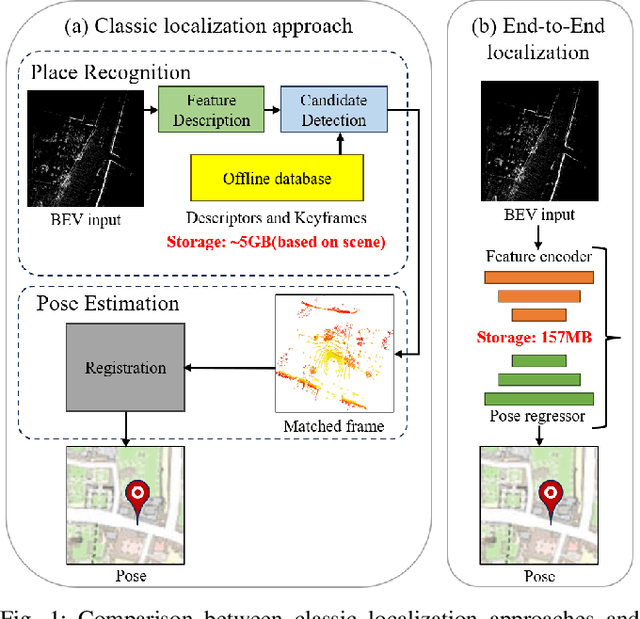
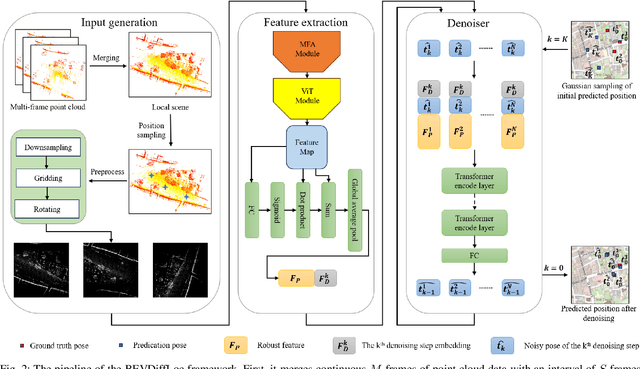
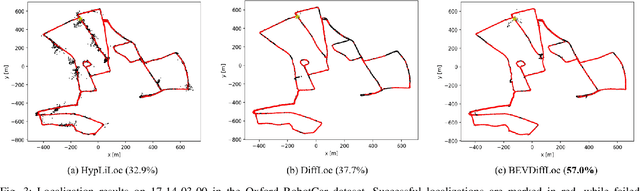
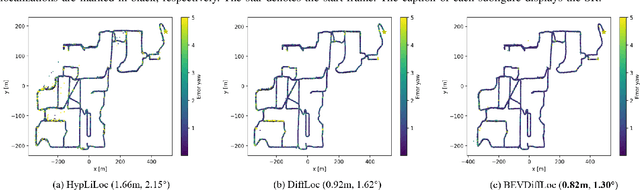
Localization is one of the core parts of modern robotics. Classic localization methods typically follow the retrieve-then-register paradigm, achieving remarkable success. Recently, the emergence of end-to-end localization approaches has offered distinct advantages, including a streamlined system architecture and the elimination of the need to store extensive map data. Although these methods have demonstrated promising results, current end-to-end localization approaches still face limitations in robustness and accuracy. Bird's-Eye-View (BEV) image is one of the most widely adopted data representations in autonomous driving. It significantly reduces data complexity while preserving spatial structure and scale consistency, making it an ideal representation for localization tasks. However, research on BEV-based end-to-end localization remains notably insufficient. To fill this gap, we propose BEVDiffLoc, a novel framework that formulates LiDAR localization as a conditional generation of poses. Leveraging the properties of BEV, we first introduce a specific data augmentation method to significantly enhance the diversity of input data. Then, the Maximum Feature Aggregation Module and Vision Transformer are employed to learn robust features while maintaining robustness against significant rotational view variations. Finally, we incorporate a diffusion model that iteratively refines the learned features to recover the absolute pose. Extensive experiments on the Oxford Radar RobotCar and NCLT datasets demonstrate that BEVDiffLoc outperforms the baseline methods. Our code is available at https://github.com/nubot-nudt/BEVDiffLoc.