 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplitFlow: Flow Decomposition for Inversion-Free Text-to-Image Editing
Oct 29, 2025



Rectified flow models have become a de facto standard in image generation due to their stable sampling trajectories and high-fidelity outputs. Despite their strong generative capabilities, they face critical limitations in image editing tasks: inaccurate inversion processes for mapping real images back into the latent space, and gradient entanglement issues during editing often result in outputs that do not faithfully reflect the target prompt. Recent efforts have attempted to directly map source and target distributions via ODE-based approaches without inversion; however,these methods still yield suboptimal editing quality. In this work, we propose a flow decomposition-and-aggregation framework built upon an inversion-free formulation to address these limitations. Specifically, we semantically decompose the target prompt into multiple sub-prompts, compute an independent flow for each, and aggregate them to form a unified editing trajectory. While we empirically observe that decomposing the original flow enhances diversity in the target space, generating semantically aligned outputs still requires consistent guidance toward the full target prompt. To this end, we design a projection and soft-aggregation mechanism for flow, inspired by gradient conflict resolution in multi-task learning. This approach adaptively weights the sub-target velocity fields, suppressing semantic redundancy while emphasizing distinct directions, thereby preserving both diversity and consistency in the final edited output. Experimental results demonstrate that our method outperforms existing zero-shot editing approaches in terms of semantic fidelity and attribute disentanglement. The code is available at https://github.com/Harvard-AI-and-Robotics-Lab/SplitFlow.
MapBERT: Bitwise Masked Modeling for Real-Time Semantic Mapping Generation
Jun 09, 2025Spatial awareness is a critical capability for embodied agents, as it enables them to anticipate and reason about unobserved regions. The primary challenge arises from learning the distribution of indoor semantics, complicated by sparse, imbalanced object categories and diverse spatial scales. Existing methods struggle to robustly generate unobserved areas in real time and do not generalize well to new environments. To this end, we propose \textbf{MapBERT}, a novel framework designed to effectively model the distribution of unseen spaces. Motivated by the observation that the one-hot encoding of semantic maps aligns naturally with the binary structure of bit encoding, we, for the first time, leverage a lookup-free BitVAE to encode semantic maps into compact bitwise tokens. Building on this, a masked transformer is employed to infer missing regions and generate complete semantic maps from limited observations. To enhance object-centric reasoning, we propose an object-aware masking strategy that masks entire object categories concurrently and pairs them with learnable embeddings, capturing implicit relationships between object embeddings and spatial tokens. By learning these relationships, the model more effectively captures indoor semantic distributions crucial for practical robotic tasks. Experiments on Gibson benchmarks show that MapBERT achieves state-of-the-art semantic map generation, balancing computational efficiency with accurate reconstruction of unobserved regions.
H2-COMPACT: Human-Humanoid Co-Manipulation via Adaptive Contact Trajectory Policies
May 23, 2025We present a hierarchical policy-learning framework that enables a legged humanoid to cooperatively carry extended loads with a human partner using only haptic cues for intent inference. At the upper tier, a lightweight behavior-cloning network consumes six-axis force/torque streams from dual wrist-mounted sensors and outputs whole-body planar velocity commands that capture the leader's applied forces. At the lower tier, a deep-reinforcement-learning policy, trained under randomized payloads (0-3 kg) and friction conditions in Isaac Gym and validated in MuJoCo and on a real Unitree G1, maps these high-level twists to stable, under-load joint trajectories. By decoupling intent interpretation (force -> velocity) from legged locomotion (velocity -> joints), our method combines intuitive responsiveness to human inputs with robust, load-adaptive walking. We collect training data without motion-capture or markers, only synchronized RGB video and F/T readings, employing SAM2 and WHAM to extract 3D human pose and velocity. In real-world trials, our humanoid achieves cooperative carry-and-move performance (completion time, trajectory deviation, velocity synchrony, and follower-force) on par with a blindfolded human-follower baseline. This work is the first to demonstrate learned haptic guidance fused with full-body legged control for fluid human-humanoid co-manipulation. Code and videos are available on the H2-COMPACT website.
Embodied Chain of Action Reasoning with Multi-Modal Foundation Model for Humanoid Loco-manipulation
Apr 13, 2025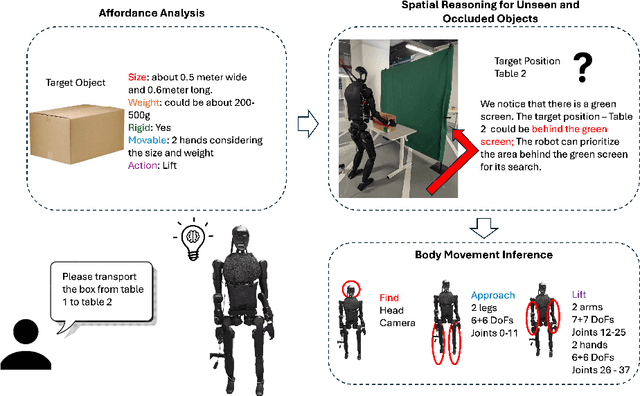
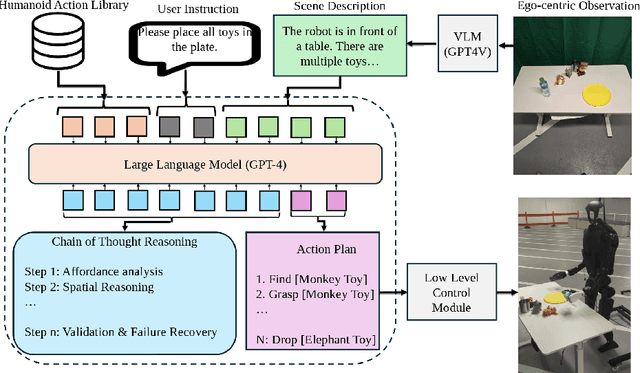
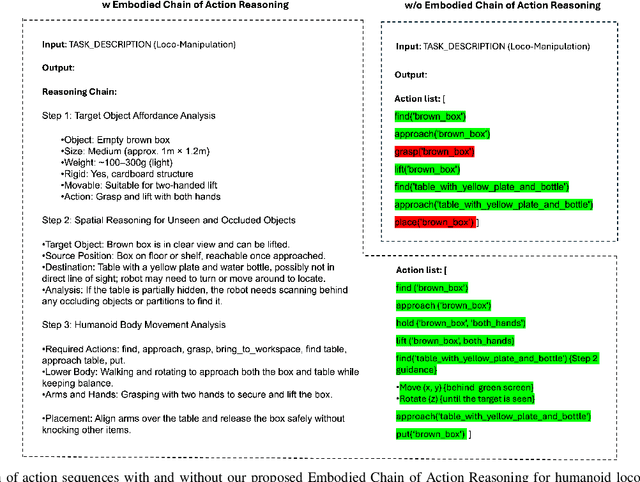

Enabling humanoid robots to autonomously perform loco-manipulation tasks in complex, unstructured environments poses significant challenges. This entails equipping robots with the capability to plan actions over extended horizons while leveraging multi-modality to bridge gaps between high-level planning and actual task execution. Recent advancements in multi-modal foundation models have showcased substantial potential in enhancing planning and reasoning abilities, particularly in the comprehension and processing of semantic information for robotic control tasks. In this paper, we introduce a novel framework based on foundation models that applies the embodied chain of action reasoning methodology to autonomously plan actions from textual instructions for humanoid loco-manipulation. Our method integrates humanoid-specific chain of thought methodology, including detailed affordance and body movement analysis, which provides a breakdown of the task into a sequence of locomotion and manipulation actions. Moreover, we incorporate spatial reasoning based on the observation and target object properties to effectively navigate where target position may be unseen or occluded. Through rigorous experimental setups on object rearrangement, manipulations and loco-manipulation tasks on a real-world environment, we evaluate our method's efficacy on the decoupled upper and lower body control and demonstrate the effectiveness of the chain of robotic action reasoning strategies in comprehending human instructions.
RS-RAG: Bridging Remote Sensing Imagery and Comprehensive Knowledge with a Multi-Modal Dataset and Retrieval-Augmented Generation Model
Apr 07, 2025



Recent progress in VLMs has demonstrated impressive capabilities across a variety of tasks in the natural image domain. Motivated by these advancements, the remote sensing community has begun to adopt VLMs for remote sensing vision-language tasks, including scene understanding, image captioning, and visual question answering. However, existing remote sensing VLMs typically rely on closed-set scene understanding and focus on generic scene descriptions, yet lack the ability to incorporate external knowledge. This limitation hinders their capacity for semantic reasoning over complex or context-dependent queries that involve domain-specific or world knowledge. To address these challenges, we first introduced a multimodal Remote Sensing World Knowledge (RSWK) dataset, which comprises high-resolution satellite imagery and detailed textual descriptions for 14,141 well-known landmarks from 175 countries, integrating both remote sensing domain knowledge and broader world knowledge. Building upon this dataset, we proposed a novel Remote Sensing Retrieval-Augmented Generation (RS-RAG) framework, which consists of two key components. The Multi-Modal Knowledge Vector Database Construction module encodes remote sensing imagery and associated textual knowledge into a unified vector space. The Knowledge Retrieval and Response Generation module retrieves and re-ranks relevant knowledge based on image and/or text queries, and incorporates the retrieved content into a knowledge-augmented prompt to guide the VLM in producing contextually grounded responses. We validated the effectiveness of our approach on three representative vision-language tasks, including image captioning, image classification, and visual question answering, where RS-RAG significantly outperformed state-of-the-art baselines.
ResLPR: A LiDAR Data Restoration Network and Benchmark for Robust Place Recognition Against Weather Corruptions
Mar 16, 2025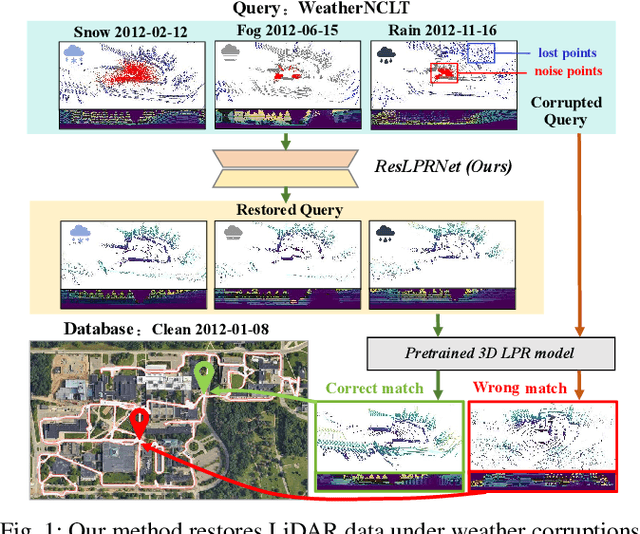
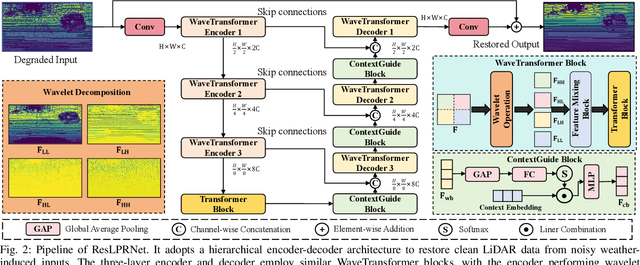
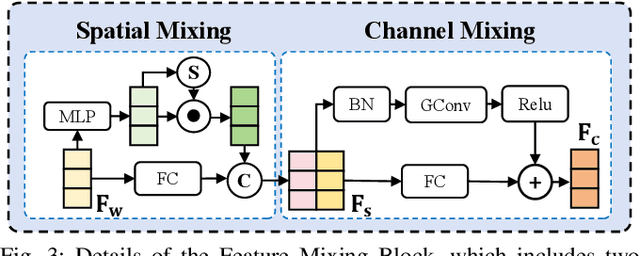
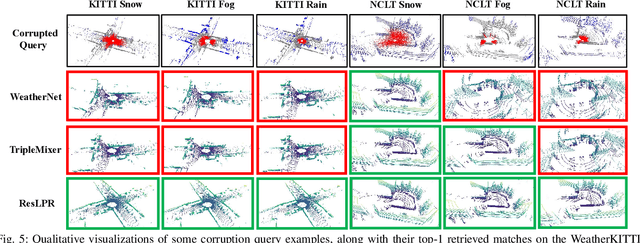
LiDAR-based place recognition (LPR) is a key component for autonomous driving, and its resilience to environmental corruption is critical for safety in high-stakes applications. While state-of-the-art (SOTA) LPR methods perform well in clean weather, they still struggle with weather-induced corruption commonly encountered in driving scenarios. To tackle this, we propose ResLPRNet, a novel LiDAR data restoration network that largely enhances LPR performance under adverse weather by restoring corrupted LiDAR scans using a wavelet transform-based network. ResLPRNet is efficient, lightweight and can be integrated plug-and-play with pretrained LPR models without substantial additional computational cost. Given the lack of LPR datasets under adverse weather, we introduce ResLPR, a novel benchmark that examines SOTA LPR methods under a wide range of LiDAR distortions induced by severe snow, fog, and rain conditions. Experiments on our proposed WeatherKITTI and WeatherNCLT datasets demonstrate the resilience and notable gains achieved by using our restoration method with multiple LPR approaches in challenging weather scenarios. Our code and benchmark are publicly available here: https://github.com/nubot-nudt/ResLPR.
A Chain-of-Thought Subspace Meta-Learning for Few-shot Image Captioning with Large Vision and Language Models
Feb 19, 2025A large-scale vision and language model that has been pretrained on massive data encodes visual and linguistic prior, which makes it easier to generate images and language that are more natural and realistic. Despite this, there is still a significant domain gap between the modalities of vision and language, especially when training data is scarce in few-shot settings, where only very limited data are available for training. In order to mitigate this issue, a multi-modal meta-learning framework has been proposed to bridge the gap between two frozen pretrained large vision and language models by introducing a tunable prompt connecting these two large models. For few-shot image captioning, the existing multi-model meta-learning framework utilizes a one-step prompting scheme to accumulate the visual features of input images to guide the language model, which struggles to generate accurate image descriptions with only a few training samples. Instead, we propose a chain-of-thought (CoT) meta-learning scheme as a multi-step image captioning procedure to better imitate how humans describe images. In addition, we further propose to learn different meta-parameters of the model corresponding to each CoT step in distinct subspaces to avoid interference. We evaluated our method on three commonly used image captioning datasets, i.e., MSCOCO, Flickr8k, and Flickr30k, under few-shot settings. The results of our experiments indicate that our chain-of-thought subspace meta-learning strategy is superior to the baselines in terms of performance across different datasets measured by different metrics.
FedRSClip: Federated Learning for Remote Sensing Scene Classification Using Vision-Language Models
Jan 05, 2025



Remote sensing data is often distributed across multiple institutions, and due to privacy concerns and data-sharing restrictions, leveraging large-scale datasets in a centralized training framework is challenging. Federated learning offers a promising solution by enabling collaborative model training across distributed data sources without requiring data centralization. However, current Vision-Language Models (VLMs), which typically contain billions of parameters, pose significant communication challenges for traditional federated learning approaches based on model parameter updates, as they would incur substantial communication costs. In this paper, we propose FedRSCLIP, the first federated learning framework designed for remote sensing image classification based on a VLM, specifically CLIP. FedRSCLIP addresses the challenges of data heterogeneity and large-scale model transmission in federated environments by introducing Prompt Learning, which optimizes only a small set of tunable parameters. The framework introduces a dual-prompt mechanism, comprising Shared Prompts for global knowledge sharing and Private Prompts for client-specific adaptation. To maintain semantic coherence between shared and private prompts, we propose the Dual Prompt Alignment Constraint to balance global consistency and local adaptability across diverse client distributions. Additionally, to enhance cross-modal representation learning, we introduce the Cross-Modal Feature Alignment Constraint to align multimodal features between text and image prompts. To validate the effectiveness of our proposed model, we construct a Fed-RSIC dataset based on three existing remote sensing image classification datasets, specifically designed to simulate various federated learning configurations. Experimental results demonstrate the effectiveness and superiority of FedRSCLIP in remote sensing image classification.
Generalization-Enhanced Few-Shot Object Detection in Remote Sensing
Jan 05, 2025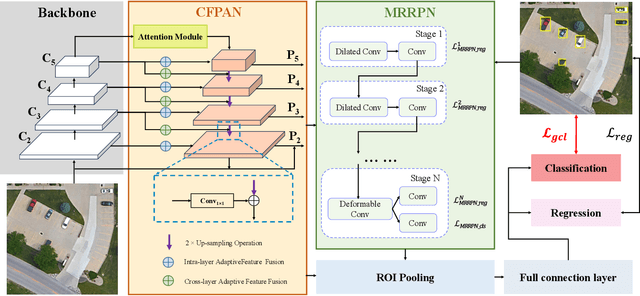
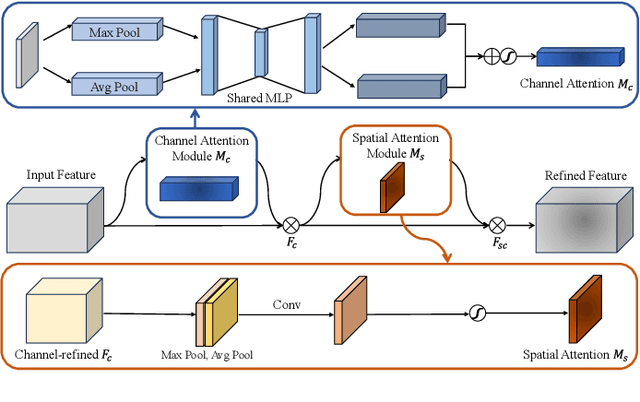
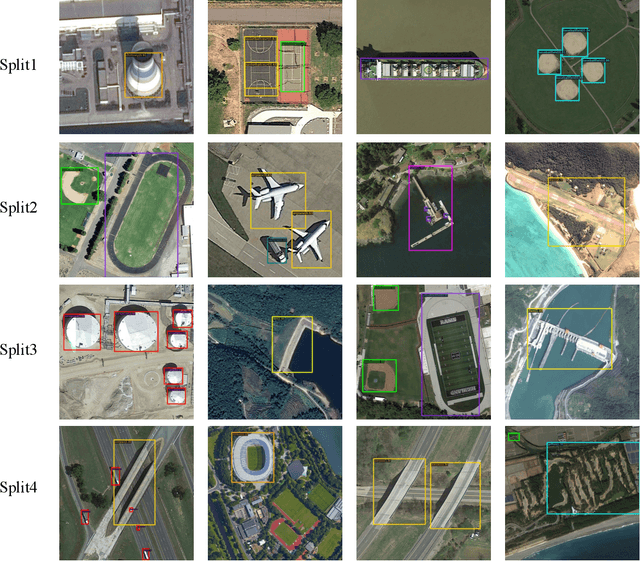

Remote sensing object detection is particularly challenging due to the high resolution, multi-scale features, and diverse ground object characteristics inherent in satellite and UAV imagery. These challenges necessitate more advanced approaches for effective object detection in such environments. While deep learning methods have achieved remarkable success in remote sensing object detection, they typically rely on large amounts of labeled data. Acquiring sufficient labeled data, particularly for novel or rare objects, is both challenging and time-consuming in remote sensing scenarios, limiting the generalization capabilities of existing models. To address these challenges, few-shot learning (FSL) has emerged as a promising approach, aiming to enable models to learn new classes from limited labeled examples. Building on this concept, few-shot object detection (FSOD) specifically targets object detection challenges in data-limited conditions. However, the generalization capability of FSOD models, particularly in remote sensing, is often constrained by the complex and diverse characteristics of the objects present in such environments. In this paper, we propose the Generalization-Enhanced Few-Shot Object Detection (GE-FSOD) model to improve the generalization capability in remote sensing FSOD tasks. Our model introduces three key innovations: the Cross-Level Fusion Pyramid Attention Network (CFPAN) for enhanced multi-scale feature representation, the Multi-Stage Refinement Region Proposal Network (MRRPN) for more accurate region proposals, and the Generalized Classification Loss (GCL) for improved classification performance in few-shot scenarios. Extensive experiments on the DIOR and NWPU VHR-10 datasets show that our model achieves state-of-the-art performance for few-shot object detection in remote sensing.
Impact of Data Distribution on Fairness Guarantees in Equitable Deep Learning
Dec 29, 2024



We present a comprehensive theoretical framework analyzing the relationship between data distributions and fairness guarantees in equitable deep learning. Our work establishes novel theoretical bounds that explicitly account for data distribution heterogeneity across demographic groups, while introducing a formal analysis framework that minimizes expected loss differences across these groups. We derive comprehensive theoretical bounds for fairness errors and convergence rates, and characterize how distributional differences between groups affect the fundamental trade-off between fairness and accuracy. Through extensive experiments on diverse datasets, including FairVision (ophthalmology), CheXpert (chest X-rays), HAM10000 (dermatology), and FairFace (facial recognition), we validate our theoretical findings and demonstrate that differences in feature distributions across demographic groups significantly impact model fairness, with performance disparities particularly pronounced in racial categories. The theoretical bounds we derive crroborate these empirical observations, providing insights into the fundamental limits of achieving fairness in deep learning models when faced with heterogeneous data distributions. This work advances our understanding of fairness in AI-based diagnosis systems and provides a theoretical foundation for developing more equitable algorithms. The code for analysis is publicly available via \url{https://github.com/Harvard-Ophthalmology-AI-Lab/fairness_guarantees}.