 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAwesomeLit: Towards Hypothesis Generation with Agent-Supported Literature Research
Mar 23, 2026There are different goals for literature research, from understanding an unfamiliar topic to generate hypothesis for the next research project. The nature of literature research also varies according to user's familiarity level of the topic. For inexperienced researchers, identifying gaps in the existing literature and generating feasible hypothesis are crucial but challenging. While general ``deep research'' tools can be used, they are not designed for such use case, thus often not effective. In addition, the ``black box" nature and hallucination of Large Language Models (LLMs) often lead to distrust. In this paper, we introduce a human-agent collaborative visualization system AwesomeLit to address this need. It has several novel features: a transparent user-steerable agentic workflow; a dynamically generated query exploring tree, visualizing the exploration path and provenance; and a semantic similarity view, depicting the relationships between papers. It enables users to transition from general intentions to detailed research topics. Finally, a qualitative study involving several early researchers showed that AwesomeLit is effective in helping users explore unfamiliar topics, identify promising research directions, and improve confidence in research results.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
SchoenbAt: Rethinking Attention with Polynomial basis
May 18, 2025Kernelized attention extends the attention mechanism by modeling sequence correlations through kernel functions, making significant progresses in optimizing attention. Under the guarantee of harmonic analysis theory, kernel functions can be expanded with basis functions, inspiring random feature-based approaches to enhance the efficiency of kernelized attention while maintaining predictive performance. However, current random feature-based works are limited to the Fourier basis expansions under Bochner's theorem. We propose Schoenberg's theorem-based attention (SchoenbAt), which approximates dot-product kernelized attention with the polynomial basis under Schoenberg's theorem via random Maclaurin features and applies a two-stage regularization to constrain the input space and restore the output scale, acting as a drop-in replacement of dot-product kernelized attention. Our theoretical proof of the unbiasedness and concentration error bound of SchoenbAt supports its efficiency and accuracy as a kernelized attention approximation, which is also empirically validated under various random feature dimensions. Evaluations on real-world datasets demonstrate that SchoenbAt significantly enhances computational speed while preserving competitive performance in terms of precision, outperforming several efficient attention methods.
Generalization-Enhanced Few-Shot Object Detection in Remote Sensing
Jan 05, 2025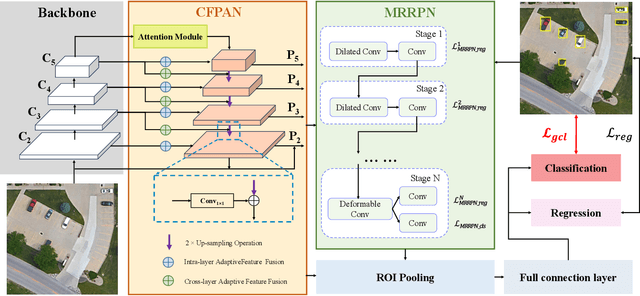
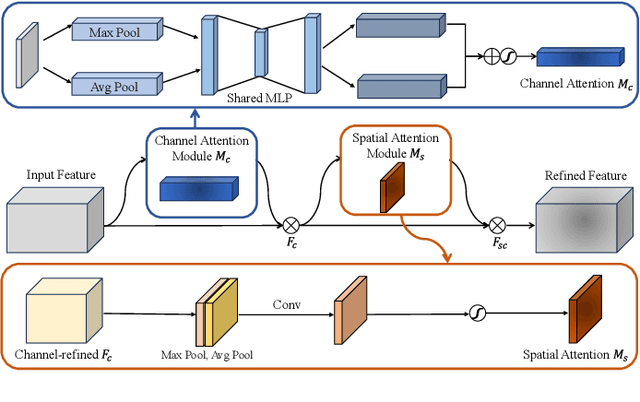

Remote sensing object detection is particularly challenging due to the high resolution, multi-scale features, and diverse ground object characteristics inherent in satellite and UAV imagery. These challenges necessitate more advanced approaches for effective object detection in such environments. While deep learning methods have achieved remarkable success in remote sensing object detection, they typically rely on large amounts of labeled data. Acquiring sufficient labeled data, particularly for novel or rare objects, is both challenging and time-consuming in remote sensing scenarios, limiting the generalization capabilities of existing models. To address these challenges, few-shot learning (FSL) has emerged as a promising approach, aiming to enable models to learn new classes from limited labeled examples. Building on this concept, few-shot object detection (FSOD) specifically targets object detection challenges in data-limited conditions. However, the generalization capability of FSOD models, particularly in remote sensing, is often constrained by the complex and diverse characteristics of the objects present in such environments. In this paper, we propose the Generalization-Enhanced Few-Shot Object Detection (GE-FSOD) model to improve the generalization capability in remote sensing FSOD tasks. Our model introduces three key innovations: the Cross-Level Fusion Pyramid Attention Network (CFPAN) for enhanced multi-scale feature representation, the Multi-Stage Refinement Region Proposal Network (MRRPN) for more accurate region proposals, and the Generalized Classification Loss (GCL) for improved classification performance in few-shot scenarios. Extensive experiments on the DIOR and NWPU VHR-10 datasets show that our model achieves state-of-the-art performance for few-shot object detection in remote sensing.
Macformer: Transformer with Random Maclaurin Feature Attention
Aug 21, 2024



Random feature attention (RFA) adopts random fourier feature (RFF) methods to approximate the softmax function, resulting in a linear time and space attention mechanism that enables the construction of an efficient Transformer. Inspired by RFA, we propose Macformer, a Transformer architecture that employs random Maclaurin features (RMF) to approximate various dot-product kernels, thereby accelerating attention computations for long sequence. Macformer consists of Random Maclaurin Feature Attention (RMFA) and pre-post Scaling Batch Normalization (ppSBN), the former is an unbiased approximation for dot-product kernelized attention and the later is a two-stage regularization mechanism guaranteeing the error of RMFA. We conducted toy experiments to demonstrate the efficiency of RMFA and ppSBN, and experiments on long range arena (LRA) benchmark to validate the acceleration and accuracy of Macformer with different dot-product kernels. Experiment results of Macformer are consistent with our theoretical analysis.
Being Aware of Localization Accuracy By Generating Predicted-IoU-Guided Quality Scores
Sep 23, 2023Localization Quality Estimation (LQE) helps to improve detection performance as it benefits post processing through jointly considering classification score and localization accuracy. In this perspective, for further leveraging the close relationship between localization accuracy and IoU (Intersection-Over-Union), and for depressing those inconsistent predictions, we designed an elegant LQE branch to acquire localization quality score guided by predicted IoU. Distinctly, for alleviating the inconsistency of classification score and localization quality during training and inference, under which some predictions with low classification scores but high LQE scores will impair the performance, instead of separately and independently setting, we embedded LQE branch into classification branch, producing a joint classification-localization-quality representation. Then a novel one stage detector termed CLQ is proposed. Extensive experiments show that CLQ achieves state-of-the-arts' performance at an accuracy of 47.8 AP and a speed of 11.5 fps with ResNeXt-101 as backbone on COCO test-dev. Finally, we extend CLQ to ATSS, producing a reliable 1.2 AP gain, showing our model's strong adaptability and scalability. Codes are released at https://github.com/PanffeeReal/CLQ.
Hessian-Free Second-Order Adversarial Examples for Adversarial Learning
Jul 04, 2022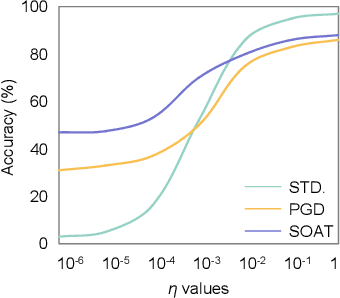
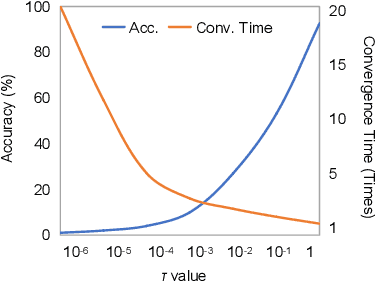
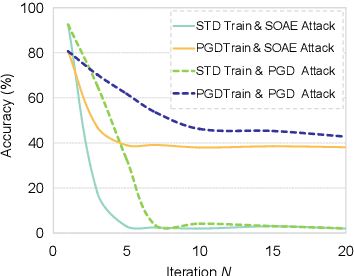
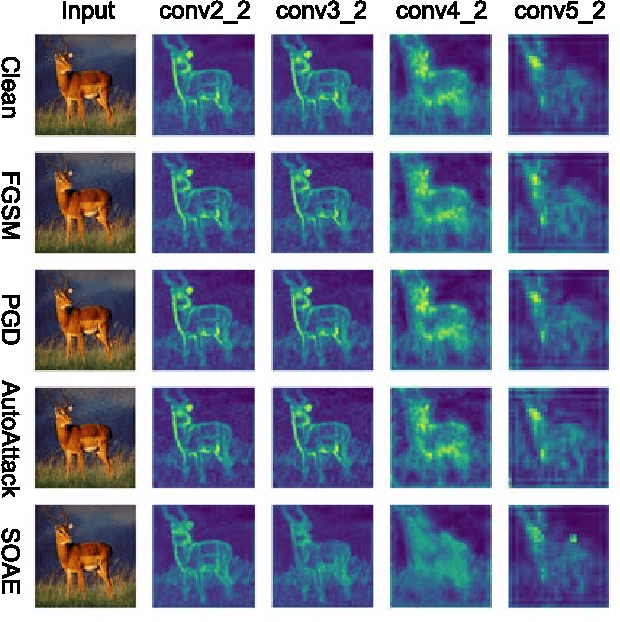
Recent studies show deep neural networks (DNNs) are extremely vulnerable to the elaborately designed adversarial examples. Adversarial learning with those adversarial examples has been proved as one of the most effective methods to defend against such an attack. At present, most existing adversarial examples generation methods are based on first-order gradients, which can hardly further improve models' robustness, especially when facing second-order adversarial attacks. Compared with first-order gradients, second-order gradients provide a more accurate approximation of the loss landscape with respect to natural examples. Inspired by this, our work crafts second-order adversarial examples and uses them to train DNNs. Nevertheless, second-order optimization involves time-consuming calculation for Hessian-inverse. We propose an approximation method through transforming the problem into an optimization in the Krylov subspace, which remarkably reduce the computational complexity to speed up the training procedure. Extensive experiments conducted on the MINIST and CIFAR-10 datasets show that our adversarial learning with second-order adversarial examples outperforms other fisrt-order methods, which can improve the model robustness against a wide range of attacks.