 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGNNVerifier: Graph-based Verifier for LLM Task Planning
Mar 17, 2026Large language models (LLMs) facilitate the development of autonomous agents. As a core component of such agents, task planning aims to decompose complex natural language requests into concrete, solvable sub-tasks. Since LLM-generated plans are frequently prone to hallucinations and sensitive to long-context prom-pts, recent research has introduced plan verifiers to identify and correct potential flaws. However, most existing approaches still rely on an LLM as the verifier via additional prompting for plan review or self-reflection. LLM-based verifiers can be misled by plausible narration and struggle to detect failures caused by structural relations across steps, such as type mismatches, missing intermediates, or broken dependencies. To address these limitations, we propose a graph-based verifier for LLM task planning. Specifically, the proposed method has four major components: Firstly, we represent a plan as a directed graph with enriched attributes, where nodes denote sub-tasks and edges encode execution order and dependency constraints. Secondly, a graph neural network (GNN) then performs structural evaluation and diagnosis, producing a graph-level plausibility score for plan acceptance as well as node/edge-level risk scores to localize erroneous regions. Thirdly, we construct controllable perturbations from ground truth plan graphs, and automatically generate training data with fine-grained annotations. Finally, guided by the feedback from our GNN verifier, we enable an LLM to conduct local edits (e.g., tool replacement or insertion) to correct the plan when the graph-level score is insufficient. Extensive experiments across diverse datasets, backbone LLMs, and planners demonstrate that our GNNVerifier achieves significant gains in improving plan quality. Our data and code is available at https://github.com/BUPT-GAMMA/GNNVerifier.
A Light and Smart Wearable Platform with Multimodal Foundation Model for Enhanced Spatial Reasoning in People with Blindness and Low Vision
May 16, 2025People with blindness and low vision (pBLV) face significant challenges, struggling to navigate environments and locate objects due to limited visual cues. Spatial reasoning is crucial for these individuals, as it enables them to understand and interpret the spatial relationships in their surroundings, enhancing their ability to navigate and interact more safely and independently. Current multi-modal large language (MLLM) models for low vision people lack the spatial reasoning capabilities needed to effectively assist in these tasks. Moreover, there is a notable absence of lightweight, easy-to-use systems that allow pBLV to effectively perceive and interact with their surrounding environment. In this paper, we propose a novel spatial enhanced multi-modal large language model based approach for visually impaired individuals. By fine-tuning the MLLM to incorporate spatial reasoning capabilities, our method significantly improves the understanding of environmental context, which is critical for navigation and object recognition. The innovation extends to a hardware component, designed as an attachment for glasses, ensuring increased accessibility and ease of use. This integration leverages advanced VLMs to interpret visual data and provide real-time, spatially aware feedback to the user. Our approach aims to bridge the gap between advanced machine learning models and practical, user-friendly assistive devices, offering a robust solution for visually impaired users to navigate their surroundings more effectively and independently. The paper includes an in-depth evaluation using the VizWiz dataset, demonstrating substantial improvements in accuracy and user experience. Additionally, we design a comprehensive dataset to evaluate our method's effectiveness in realworld situations, demonstrating substantial improvements in accuracy and user experience.
Embodied Chain of Action Reasoning with Multi-Modal Foundation Model for Humanoid Loco-manipulation
Apr 13, 2025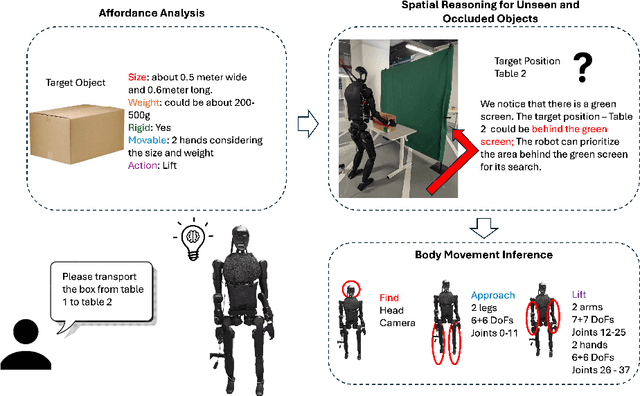
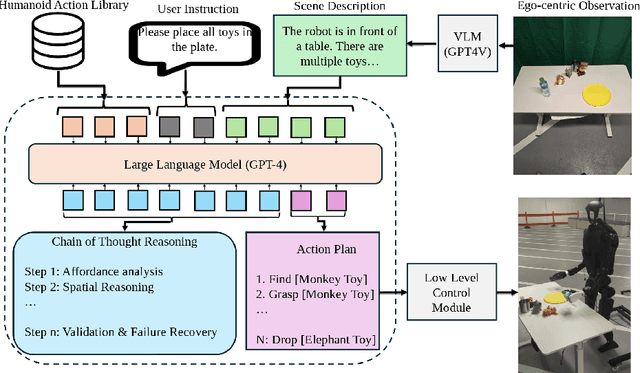
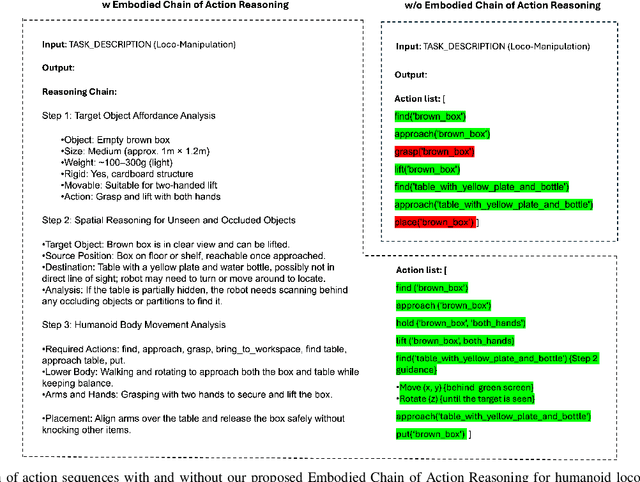

Enabling humanoid robots to autonomously perform loco-manipulation tasks in complex, unstructured environments poses significant challenges. This entails equipping robots with the capability to plan actions over extended horizons while leveraging multi-modality to bridge gaps between high-level planning and actual task execution. Recent advancements in multi-modal foundation models have showcased substantial potential in enhancing planning and reasoning abilities, particularly in the comprehension and processing of semantic information for robotic control tasks. In this paper, we introduce a novel framework based on foundation models that applies the embodied chain of action reasoning methodology to autonomously plan actions from textual instructions for humanoid loco-manipulation. Our method integrates humanoid-specific chain of thought methodology, including detailed affordance and body movement analysis, which provides a breakdown of the task into a sequence of locomotion and manipulation actions. Moreover, we incorporate spatial reasoning based on the observation and target object properties to effectively navigate where target position may be unseen or occluded. Through rigorous experimental setups on object rearrangement, manipulations and loco-manipulation tasks on a real-world environment, we evaluate our method's efficacy on the decoupled upper and lower body control and demonstrate the effectiveness of the chain of robotic action reasoning strategies in comprehending human instructions.
A Chain-of-Thought Subspace Meta-Learning for Few-shot Image Captioning with Large Vision and Language Models
Feb 19, 2025A large-scale vision and language model that has been pretrained on massive data encodes visual and linguistic prior, which makes it easier to generate images and language that are more natural and realistic. Despite this, there is still a significant domain gap between the modalities of vision and language, especially when training data is scarce in few-shot settings, where only very limited data are available for training. In order to mitigate this issue, a multi-modal meta-learning framework has been proposed to bridge the gap between two frozen pretrained large vision and language models by introducing a tunable prompt connecting these two large models. For few-shot image captioning, the existing multi-model meta-learning framework utilizes a one-step prompting scheme to accumulate the visual features of input images to guide the language model, which struggles to generate accurate image descriptions with only a few training samples. Instead, we propose a chain-of-thought (CoT) meta-learning scheme as a multi-step image captioning procedure to better imitate how humans describe images. In addition, we further propose to learn different meta-parameters of the model corresponding to each CoT step in distinct subspaces to avoid interference. We evaluated our method on three commonly used image captioning datasets, i.e., MSCOCO, Flickr8k, and Flickr30k, under few-shot settings. The results of our experiments indicate that our chain-of-thought subspace meta-learning strategy is superior to the baselines in terms of performance across different datasets measured by different metrics.
MdEval: Massively Multilingual Code Debugging
Nov 04, 2024



Code large language models (LLMs) have made significant progress in code debugging by directly generating the correct code based on the buggy code snippet. Programming benchmarks, typically consisting of buggy code snippet and their associated test cases, are used to assess the debugging capabilities of LLMs. However, many existing benchmarks primarily focus on Python and are often limited in terms of language diversity (e.g., DebugBench and DebugEval). To advance the field of multilingual debugging with LLMs, we propose the first massively multilingual debugging benchmark, which includes 3.6K test samples of 18 programming languages and covers the automated program repair (APR) task, the code review (CR) task, and the bug identification (BI) task. Further, we introduce the debugging instruction corpora MDEVAL-INSTRUCT by injecting bugs into the correct multilingual queries and solutions (xDebugGen). Further, a multilingual debugger xDebugCoder trained on MDEVAL-INSTRUCT as a strong baseline specifically to handle the bugs of a wide range of programming languages (e.g. "Missing Mut" in language Rust and "Misused Macro Definition" in language C). Our extensive experiments on MDEVAL reveal a notable performance gap between open-source models and closed-source LLMs (e.g., GPT and Claude series), highlighting huge room for improvement in multilingual code debugging scenarios.
GAMap: Zero-Shot Object Goal Navigation with Multi-Scale Geometric-Affordance Guidance
Oct 31, 2024



Zero-Shot Object Goal Navigation (ZS-OGN) enables robots or agents to navigate toward objects of unseen categories without object-specific training. Traditional approaches often leverage categorical semantic information for navigation guidance, which struggles when only objects are partially observed or detailed and functional representations of the environment are lacking. To resolve the above two issues, we propose \textit{Geometric-part and Affordance Maps} (GAMap), a novel method that integrates object parts and affordance attributes as navigation guidance. Our method includes a multi-scale scoring approach to capture geometric-part and affordance attributes of objects at different scales. Comprehensive experiments conducted on HM3D and Gibson benchmark datasets demonstrate improvements in Success Rate and Success weighted by Path Length, underscoring the efficacy of our geometric-part and affordance-guided navigation approach in enhancing robot autonomy and versatility, without any additional object-specific training or fine-tuning with the semantics of unseen objects and/or the locomotions of the robot.
Zero-shot Object Navigation with Vision-Language Models Reasoning
Oct 24, 2024



Object navigation is crucial for robots, but traditional methods require substantial training data and cannot be generalized to unknown environments. Zero-shot object navigation (ZSON) aims to address this challenge, allowing robots to interact with unknown objects without specific training data. Language-driven zero-shot object navigation (L-ZSON) is an extension of ZSON that incorporates natural language instructions to guide robot navigation and interaction with objects. In this paper, we propose a novel Vision Language model with a Tree-of-thought Network (VLTNet) for L-ZSON. VLTNet comprises four main modules: vision language model understanding, semantic mapping, tree-of-thought reasoning and exploration, and goal identification. Among these modules, Tree-of-Thought (ToT) reasoning and exploration module serves as a core component, innovatively using the ToT reasoning framework for navigation frontier selection during robot exploration. Compared to conventional frontier selection without reasoning, navigation using ToT reasoning involves multi-path reasoning processes and backtracking when necessary, enabling globally informed decision-making with higher accuracy. Experimental results on PASTURE and RoboTHOR benchmarks demonstrate the outstanding performance of our model in LZSON, particularly in scenarios involving complex natural language as target instructions.
VisPercep: A Vision-Language Approach to Enhance Visual Perception for People with Blindness and Low Vision
Oct 31, 2023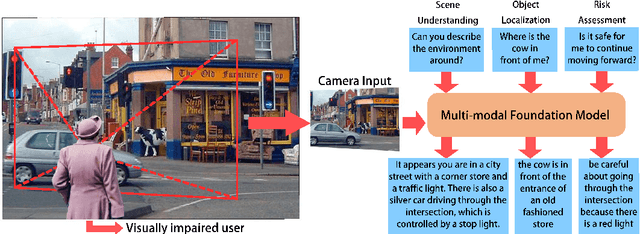

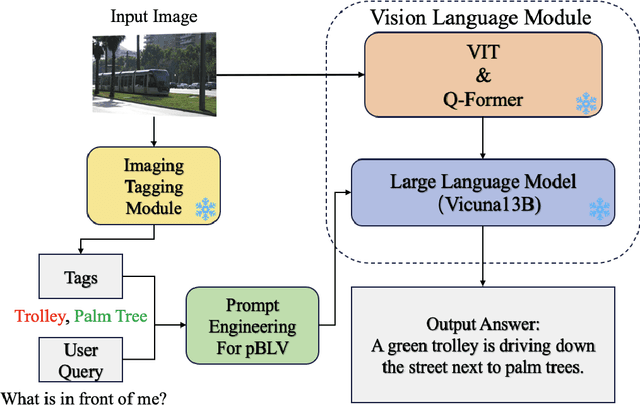

People with blindness and low vision (pBLV) encounter substantial challenges when it comes to comprehensive scene recognition and precise object identification in unfamiliar environments. Additionally, due to the vision loss, pBLV have difficulty in accessing and identifying potential tripping hazards on their own. In this paper, we present a pioneering approach that leverages a large vision-language model to enhance visual perception for pBLV, offering detailed and comprehensive descriptions of the surrounding environments and providing warnings about the potential risks. Our method begins by leveraging a large image tagging model (i.e., Recognize Anything (RAM)) to identify all common objects present in the captured images. The recognition results and user query are then integrated into a prompt, tailored specifically for pBLV using prompt engineering. By combining the prompt and input image, a large vision-language model (i.e., InstructBLIP) generates detailed and comprehensive descriptions of the environment and identifies potential risks in the environment by analyzing the environmental objects and scenes, relevant to the prompt. We evaluate our approach through experiments conducted on both indoor and outdoor datasets. Our results demonstrate that our method is able to recognize objects accurately and provide insightful descriptions and analysis of the environment for pBLV.
The Hitchhiker's Guide to Program Analysis: A Journey with Large Language Models
Aug 01, 2023

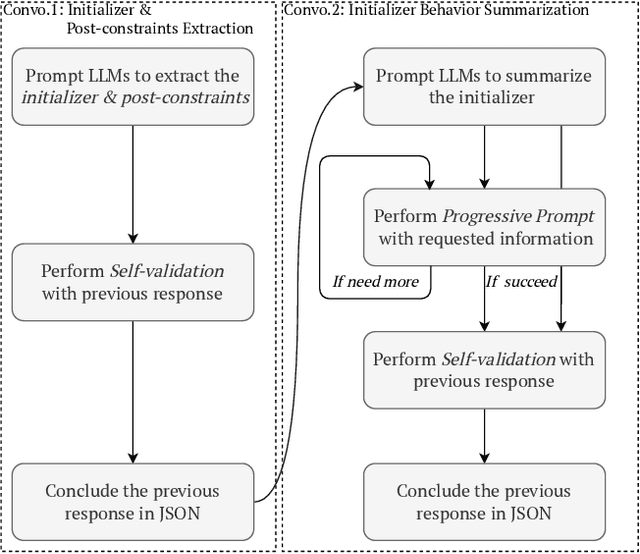

Static analysis is a widely used technique in software engineering for identifying and mitigating bugs. However, a significant hurdle lies in achieving a delicate balance between precision and scalability. Large Language Models (LLMs) offer a promising alternative, as recent advances demonstrate remarkable capabilities in comprehending, generating, and even debugging code. Yet, the logic of bugs can be complex and require sophisticated reasoning and a large analysis scope spanning multiple functions. Therefore, at this point, LLMs are better used in an assistive role to complement static analysis. In this paper, we take a deep dive into the open space of LLM-assisted static analysis, using use-before-initialization (UBI) bugs as a case study. To this end, we develop LLift, a fully automated agent that interfaces with both a static analysis tool and an LLM. By carefully designing the agent and the prompts, we are able to overcome a number of challenges, including bug-specific modeling, the large problem scope, the non-deterministic nature of LLMs, etc. Tested in a real-world scenario analyzing nearly a thousand potential UBI bugs produced by static analysis, LLift demonstrates an extremely potent capability, showcasing a high precision (50%) and recall rate (100%). It even identified 13 previously unknown UBI bugs in the Linux kernel. This research paves the way for new opportunities and methodologies in the use of LLMs for bug discovery in extensive, real-world datasets.
Understanding the Impact of Image Quality and Distance of Objects to Object Detection Performance
Sep 17, 2022
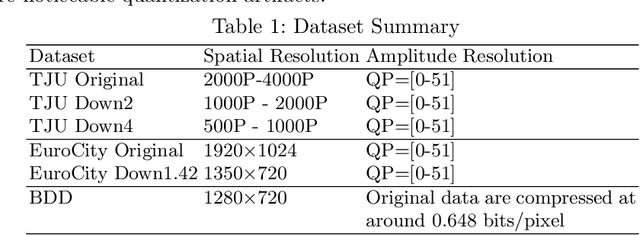


Deep learning has made great strides for object detection in images. The detection accuracy and computational cost of object detection depend on the spatial resolution of an image, which may be constrained by both the camera and storage considerations. Compression is often achieved by reducing either spatial or amplitude resolution or, at times, both, both of which have well-known effects on performance. Detection accuracy also depends on the distance of the object of interest from the camera. Our work examines the impact of spatial and amplitude resolution, as well as object distance, on object detection accuracy and computational cost. We develop a resolution-adaptive variant of YOLOv5 (RA-YOLO), which varies the number of scales in the feature pyramid and detection head based on the spatial resolution of the input image. To train and evaluate this new method, we created a dataset of images with diverse spatial and amplitude resolutions by combining images from the TJU and Eurocity datasets and generating different resolutions by applying spatial resizing and compression. We first show that RA-YOLO achieves a good trade-off between detection accuracy and inference time over a large range of spatial resolutions. We then evaluate the impact of spatial and amplitude resolutions on object detection accuracy using the proposed RA-YOLO model. We demonstrate that the optimal spatial resolution that leads to the highest detection accuracy depends on the 'tolerated' image size. We further assess the impact of the distance of an object to the camera on the detection accuracy and show that higher spatial resolution enables a greater detection range. These results provide important guidelines for choosing the image spatial resolution and compression settings predicated on available bandwidth, storage, desired inference time, and/or desired detection range, in practical applications.