 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisPercep: A Vision-Language Approach to Enhance Visual Perception for People with Blindness and Low Vision
Paper and Code
Oct 31, 2023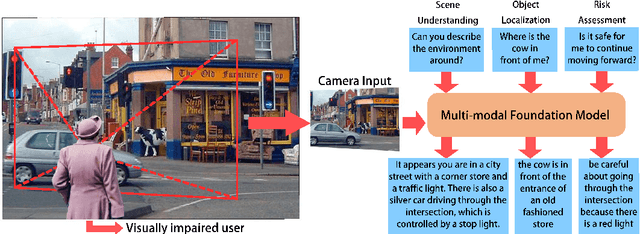

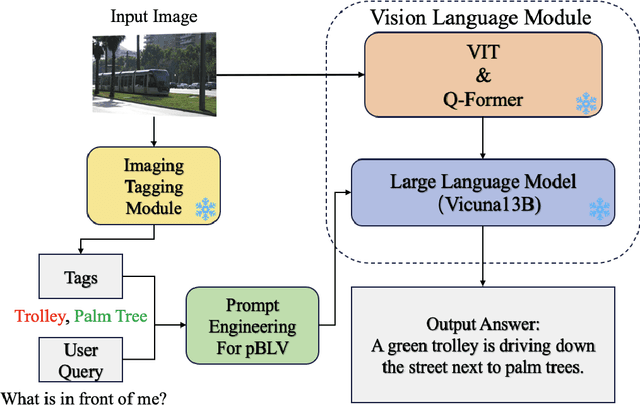

People with blindness and low vision (pBLV) encounter substantial challenges when it comes to comprehensive scene recognition and precise object identification in unfamiliar environments. Additionally, due to the vision loss, pBLV have difficulty in accessing and identifying potential tripping hazards on their own. In this paper, we present a pioneering approach that leverages a large vision-language model to enhance visual perception for pBLV, offering detailed and comprehensive descriptions of the surrounding environments and providing warnings about the potential risks. Our method begins by leveraging a large image tagging model (i.e., Recognize Anything (RAM)) to identify all common objects present in the captured images. The recognition results and user query are then integrated into a prompt, tailored specifically for pBLV using prompt engineering. By combining the prompt and input image, a large vision-language model (i.e., InstructBLIP) generates detailed and comprehensive descriptions of the environment and identifies potential risks in the environment by analyzing the environmental objects and scenes, relevant to the prompt. We evaluate our approach through experiments conducted on both indoor and outdoor datasets. Our results demonstrate that our method is able to recognize objects accurately and provide insightful descriptions and analysis of the environment for pBLV.