 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating OCR Performance for Assistive Technology: Effects of Walking Speed, Camera Placement, and Camera Type
Feb 02, 2026Optical character recognition (OCR), which converts printed or handwritten text into machine-readable form, is widely used in assistive technology for people with blindness and low vision. Yet, most evaluations rely on static datasets that do not reflect the challenges of mobile use. In this study, we systematically evaluated OCR performance under both static and dynamic conditions. Static tests measured detection range across distances of 1-7 meters and viewing angles of 0-75 degrees horizontally. Dynamic tests examined the impact of motion by varying walking speed from slow (0.8 m/s) to very fast (1.8 m/s) and comparing three camera mounting positions: head-mounted, shoulder-mounted, and hand-held. We evaluated both a smartphone and smart glasses, using the phone's main and ultra-wide cameras. Four OCR engines were benchmarked to assess accuracy at different distances and viewing angles: Google Vision, PaddleOCR 3.0, EasyOCR, and Tesseract. PaddleOCR 3.0 was then used to evaluate accuracy at different walking speeds. Accuracy was computed at the character level using the Levenshtein ratio against manually defined ground truth. Results showed that recognition accuracy declined with increased walking speed and wider viewing angles. Google Vision achieved the highest overall accuracy, with PaddleOCR close behind as the strongest open-source alternative. Across devices, the phone's main camera achieved the highest accuracy, and a shoulder-mounted placement yielded the highest average among body positions; however, differences among shoulder, head, and hand were not statistically significant.
Robust Computer-Vision based Construction Site Detection for Assistive-Technology Applications
Mar 06, 2025Navigating urban environments poses significant challenges for people with disabilities, particularly those with blindness and low vision. Environments with dynamic and unpredictable elements like construction sites are especially challenging. Construction sites introduce hazards like uneven surfaces, obstructive barriers, hazardous materials, and excessive noise, and they can alter routing, complicating safe mobility. Existing assistive technologies are limited, as navigation apps do not account for construction sites during trip planning, and detection tools that attempt hazard recognition struggle to address the extreme variability of construction paraphernalia. This study introduces a novel computer vision-based system that integrates open-vocabulary object detection, a YOLO-based scaffolding-pole detection model, and an optical character recognition (OCR) module to comprehensively identify and interpret construction site elements for assistive navigation. In static testing across seven construction sites, the system achieved an overall accuracy of 88.56\%, reliably detecting objects from 2m to 10m within a 0$^\circ$ -- 75$^\circ$ angular offset. At closer distances (2--4m), the detection rate was 100\% at all tested angles. At
Can Foundation Models Reliably Identify Spatial Hazards? A Case Study on Curb Segmentation
Jun 11, 2024Curbs serve as vital borders that delineate safe pedestrian zones from potential vehicular traffic hazards. Curbs also represent a primary spatial hazard during dynamic navigation with significant stumbling potential. Such vulnerabilities are particularly exacerbated for persons with blindness and low vision (PBLV). Accurate visual-based discrimination of curbs is paramount for assistive technologies that aid PBLV with safe navigation in urban environments. Herein, we investigate the efficacy of curb segmentation for foundation models. We introduce the largest curb segmentation dataset to-date to benchmark leading foundation models. Our results show that state-of-the-art foundation models face significant challenges in curb segmentation. This is due to their high false-positive rates (up to 95%) with poor performance distinguishing curbs from curb-like objects or non-curb areas, such as sidewalks. In addition, the best-performing model averaged a 3.70-second inference time, underscoring problems in providing real-time assistance. In response, we propose solutions including filtered bounding box selections to achieve more accurate curb segmentation. Overall, despite the immediate flexibility of foundation models, their application for practical assistive technology applications still requires refinement. This research highlights the critical need for specialized datasets and tailored model training to address navigation challenges for PBLV and underscores implicit weaknesses in foundation models.
NYC-Indoor-VPR: A Long-Term Indoor Visual Place Recognition Dataset with Semi-Automatic Annotation
Mar 31, 2024



Visual Place Recognition (VPR) in indoor environments is beneficial to humans and robots for better localization and navigation. It is challenging due to appearance changes at various frequencies, and difficulties of obtaining ground truth metric trajectories for training and evaluation. This paper introduces the NYC-Indoor-VPR dataset, a unique and rich collection of over 36,000 images compiled from 13 distinct crowded scenes in New York City taken under varying lighting conditions with appearance changes. Each scene has multiple revisits across a year. To establish the ground truth for VPR, we propose a semiautomatic annotation approach that computes the positional information of each image. Our method specifically takes pairs of videos as input and yields matched pairs of images along with their estimated relative locations. The accuracy of this matching is refined by human annotators, who utilize our annotation software to correlate the selected keyframes. Finally, we present a benchmark evaluation of several state-of-the-art VPR algorithms using our annotated dataset, revealing its challenge and thus value for VPR research.
VisPercep: A Vision-Language Approach to Enhance Visual Perception for People with Blindness and Low Vision
Oct 31, 2023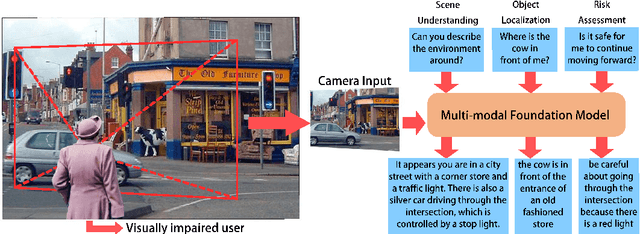

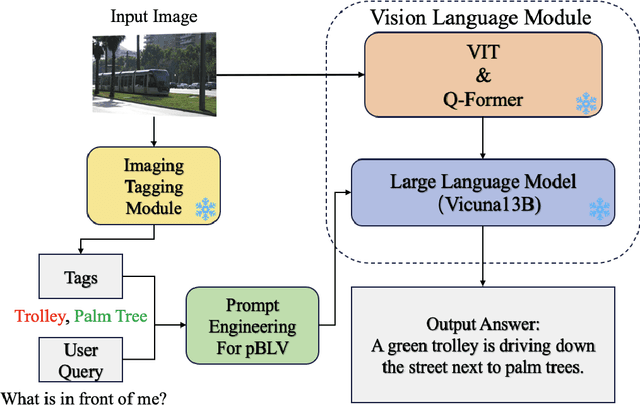

People with blindness and low vision (pBLV) encounter substantial challenges when it comes to comprehensive scene recognition and precise object identification in unfamiliar environments. Additionally, due to the vision loss, pBLV have difficulty in accessing and identifying potential tripping hazards on their own. In this paper, we present a pioneering approach that leverages a large vision-language model to enhance visual perception for pBLV, offering detailed and comprehensive descriptions of the surrounding environments and providing warnings about the potential risks. Our method begins by leveraging a large image tagging model (i.e., Recognize Anything (RAM)) to identify all common objects present in the captured images. The recognition results and user query are then integrated into a prompt, tailored specifically for pBLV using prompt engineering. By combining the prompt and input image, a large vision-language model (i.e., InstructBLIP) generates detailed and comprehensive descriptions of the environment and identifies potential risks in the environment by analyzing the environmental objects and scenes, relevant to the prompt. We evaluate our approach through experiments conducted on both indoor and outdoor datasets. Our results demonstrate that our method is able to recognize objects accurately and provide insightful descriptions and analysis of the environment for pBLV.
Distillation Improves Visual Place Recognition for Low-Quality Queries
Oct 10, 2023
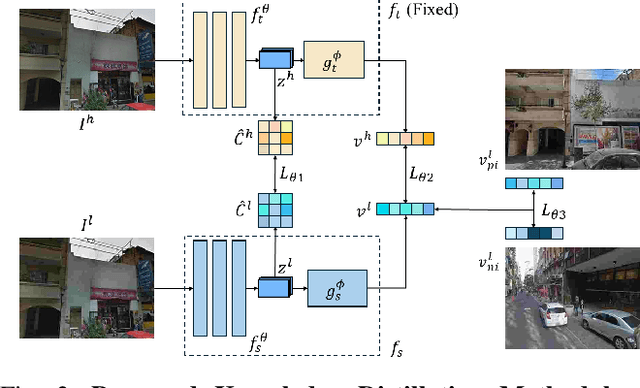
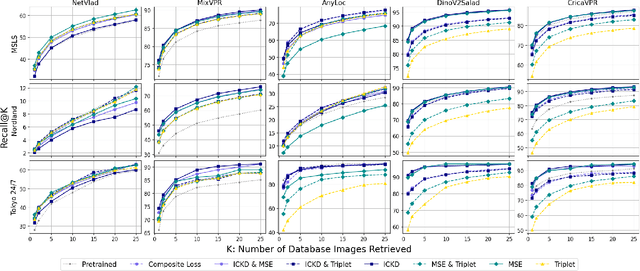
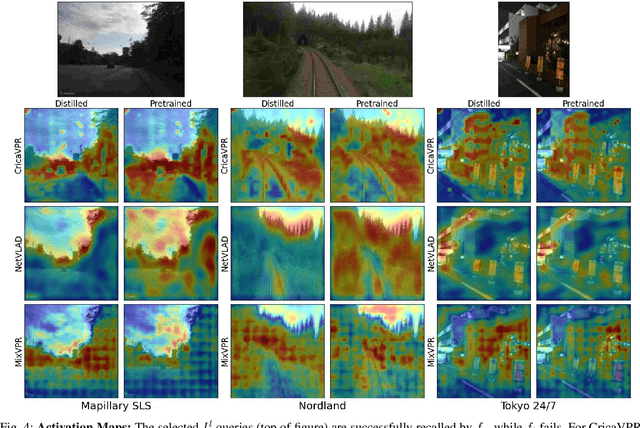
The shift to online computing for real-time visual localization often requires streaming query images/videos to a server for visual place recognition (VPR), where fast video transmission may result in reduced resolution or increased quantization. This compromises the quality of global image descriptors, leading to decreased VPR performance. To improve the low recall rate for low-quality query images, we present a simple yet effective method that uses high-quality queries only during training to distill better feature representations for deep-learning-based VPR, such as NetVLAD. Specifically, we use mean squared error (MSE) loss between the global descriptors of queries with different qualities, and inter-channel correlation knowledge distillation (ICKD) loss over their corresponding intermediate features. We validate our approach using the both Pittsburgh 250k dataset and our own indoor dataset with varying quantization levels. By fine-tuning NetVLAD parameters with our distillation-augmented losses, we achieve notable VPR recall-rate improvements over low-quality queries, as demonstrated in our extensive experimental results. We believe this work not only pushes forward the VPR research but also provides valuable insights for applications needing dependable place recognition under resource-limited conditions.
UNav: An Infrastructure-Independent Vision-Based Navigation System for People with Blindness and Low vision
Sep 22, 2022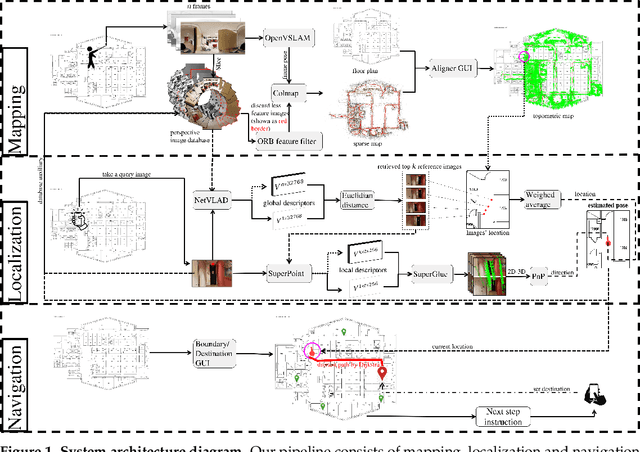

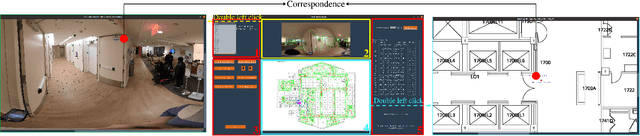

Vision-based localization approaches now underpin newly emerging navigation pipelines for myriad use cases from robotics to assistive technologies. Compared to sensor-based solutions, vision-based localization does not require pre-installed sensor infrastructure, which is costly, time-consuming, and/or often infeasible at scale. Herein, we propose a novel vision-based localization pipeline for a specific use case: navigation support for end-users with blindness and low vision. Given a query image taken by an end-user on a mobile application, the pipeline leverages a visual place recognition (VPR) algorithm to find similar images in a reference image database of the target space. The geolocations of these similar images are utilized in downstream tasks that employ a weighted-average method to estimate the end-user's location and a perspective-n-point (PnP) algorithm to estimate the end-user's direction. Additionally, this system implements Dijkstra's algorithm to calculate a shortest path based on a navigable map that includes trip origin and destination. The topometric map used for localization and navigation is built using a customized graphical user interface that projects a 3D reconstructed sparse map, built from a sequence of images, to the corresponding a priori 2D floor plan. Sequential images used for map construction can be collected in a pre-mapping step or scavenged through public databases/citizen science. The end-to-end system can be installed on any internet-accessible device with a camera that hosts a custom mobile application. For evaluation purposes, mapping and localization were tested in a complex hospital environment. The evaluation results demonstrate that our system can achieve localization with an average error of less than 1 meter without knowledge of the camera's intrinsic parameters, such as focal length.
Understanding the Impact of Image Quality and Distance of Objects to Object Detection Performance
Sep 17, 2022
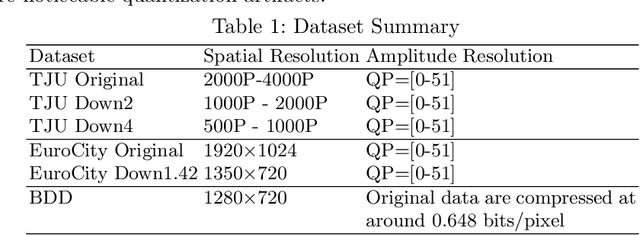


Deep learning has made great strides for object detection in images. The detection accuracy and computational cost of object detection depend on the spatial resolution of an image, which may be constrained by both the camera and storage considerations. Compression is often achieved by reducing either spatial or amplitude resolution or, at times, both, both of which have well-known effects on performance. Detection accuracy also depends on the distance of the object of interest from the camera. Our work examines the impact of spatial and amplitude resolution, as well as object distance, on object detection accuracy and computational cost. We develop a resolution-adaptive variant of YOLOv5 (RA-YOLO), which varies the number of scales in the feature pyramid and detection head based on the spatial resolution of the input image. To train and evaluate this new method, we created a dataset of images with diverse spatial and amplitude resolutions by combining images from the TJU and Eurocity datasets and generating different resolutions by applying spatial resizing and compression. We first show that RA-YOLO achieves a good trade-off between detection accuracy and inference time over a large range of spatial resolutions. We then evaluate the impact of spatial and amplitude resolutions on object detection accuracy using the proposed RA-YOLO model. We demonstrate that the optimal spatial resolution that leads to the highest detection accuracy depends on the 'tolerated' image size. We further assess the impact of the distance of an object to the camera on the detection accuracy and show that higher spatial resolution enables a greater detection range. These results provide important guidelines for choosing the image spatial resolution and compression settings predicated on available bandwidth, storage, desired inference time, and/or desired detection range, in practical applications.
Detect and Approach: Close-Range Navigation Support for People with Blindness and Low Vision
Aug 17, 2022

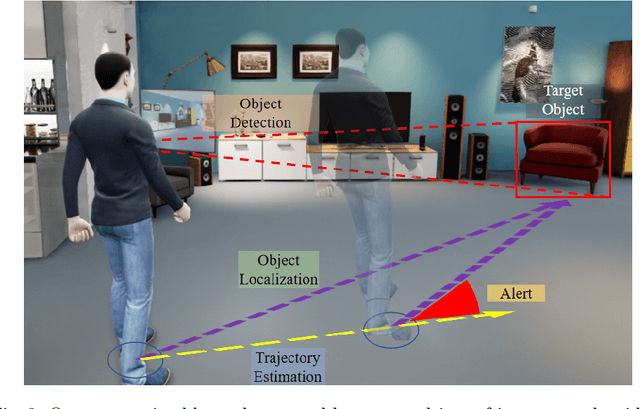
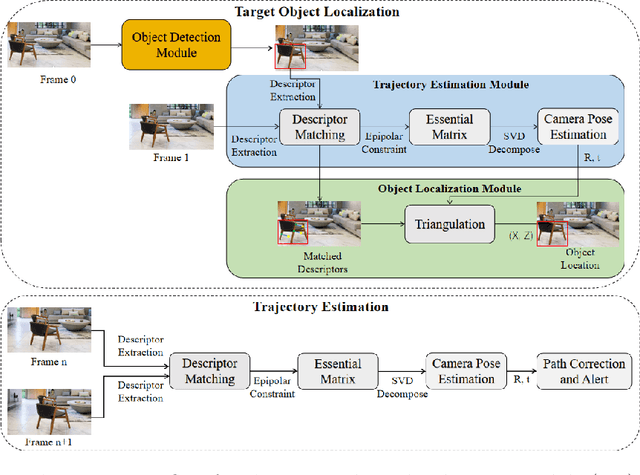
People with blindness and low vision (pBLV) experience significant challenges when locating final destinations or targeting specific objects in unfamiliar environments. Furthermore, besides initially locating and orienting oneself to a target object, approaching the final target from one's present position is often frustrating and challenging, especially when one drifts away from the initial planned path to avoid obstacles. In this paper, we develop a novel wearable navigation solution to provide real-time guidance for a user to approach a target object of interest efficiently and effectively in unfamiliar environments. Our system contains two key visual computing functions: initial target object localization in 3D and continuous estimation of the user's trajectory, both based on the 2D video captured by a low-cost monocular camera mounted on in front of the chest of the user. These functions enable the system to suggest an initial navigation path, continuously update the path as the user moves, and offer timely recommendation about the correction of the user's path. Our experiments demonstrate that our system is able to operate with an error of less than 0.5 meter both outdoor and indoor. The system is entirely vision-based and does not need other sensors for navigation, and the computation can be run with the Jetson processor in the wearable system to facilitate real-time navigation assistance.
NYU-VPR: Long-Term Visual Place Recognition Benchmark with View Direction and Data Anonymization Influences
Oct 18, 2021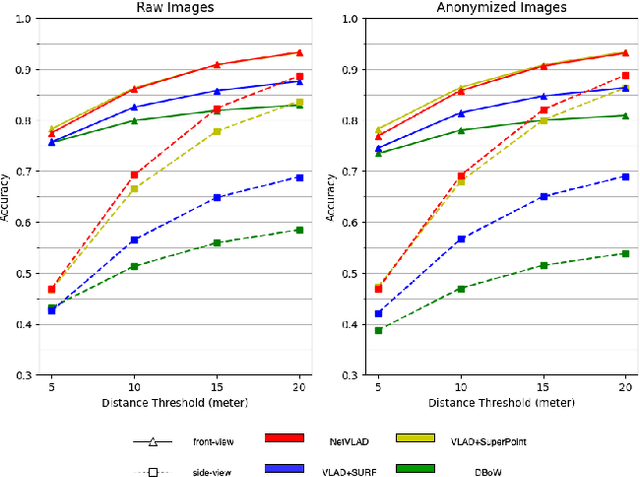
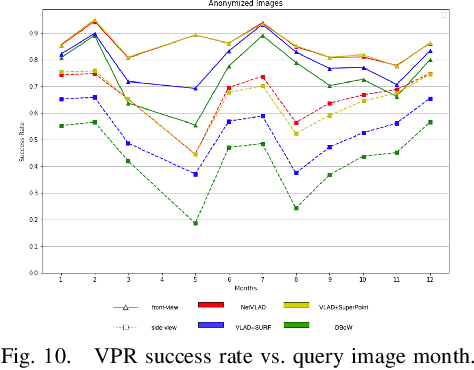


Visual place recognition (VPR) is critical in not only localization and mapping for autonomous driving vehicles, but also assistive navigation for the visually impaired population. To enable a long-term VPR system on a large scale, several challenges need to be addressed. First, different applications could require different image view directions, such as front views for self-driving cars while side views for the low vision people. Second, VPR in metropolitan scenes can often cause privacy concerns due to the imaging of pedestrian and vehicle identity information, calling for the need for data anonymization before VPR queries and database construction. Both factors could lead to VPR performance variations that are not well understood yet. To study their influences, we present the NYU-VPR dataset that contains more than 200,000 images over a 2km by 2km area near the New York University campus, taken within the whole year of 2016. We present benchmark results on several popular VPR algorithms showing that side views are significantly more challenging for current VPR methods while the influence of data anonymization is almost negligible, together with our hypothetical explanations and in-depth analysis.