 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Change Detection with Vision-Language Representation Learning
Apr 13, 2026Scene change detection (SCD) is crucial for urban monitoring and navigation but remains challenging in real-world environments due to lighting variations, seasonal shifts, viewpoint differences, and complex urban layouts. Existing methods rely primarily on low-level visual features, limiting their ability to accurately identify changed objects amid the visual complexity of urban scenes. In this paper, we propose LangSCD, a vision-language framework for scene change detection that overcomes this single-modal limitation by incorporating semantic reasoning through language. Our approach introduces a modular language component that leverages vision-language models (VLMs) to generate textual descriptions of scene changes, which are fused with visual features through a cross-modal feature enhancer. We further introduce a geometric-semantic matching module that refines the predicted masks by enforcing semantic consistency and spatial completeness. Existing real-world scene change detection benchmarks provide only binary change annotations, which are insufficient for downstream applications requiring fine-grained understanding of scene dynamics. To address this limitation, we introduce NYC-CD, a large-scale dataset of 8,122 real-world image pairs collected in New York City with multiclass change annotations generated through a semi-automatic pipeline. Extensive experiments across multiple street-view benchmarks demonstrate that our language and matching modules consistently improve existing change-detection architectures, achieving state-of-the-art performance and highlighting the value of integrating linguistic reasoning with visual representations for robust scene change detection.
Can Foundation Models Reliably Identify Spatial Hazards? A Case Study on Curb Segmentation
Jun 11, 2024Curbs serve as vital borders that delineate safe pedestrian zones from potential vehicular traffic hazards. Curbs also represent a primary spatial hazard during dynamic navigation with significant stumbling potential. Such vulnerabilities are particularly exacerbated for persons with blindness and low vision (PBLV). Accurate visual-based discrimination of curbs is paramount for assistive technologies that aid PBLV with safe navigation in urban environments. Herein, we investigate the efficacy of curb segmentation for foundation models. We introduce the largest curb segmentation dataset to-date to benchmark leading foundation models. Our results show that state-of-the-art foundation models face significant challenges in curb segmentation. This is due to their high false-positive rates (up to 95%) with poor performance distinguishing curbs from curb-like objects or non-curb areas, such as sidewalks. In addition, the best-performing model averaged a 3.70-second inference time, underscoring problems in providing real-time assistance. In response, we propose solutions including filtered bounding box selections to achieve more accurate curb segmentation. Overall, despite the immediate flexibility of foundation models, their application for practical assistive technology applications still requires refinement. This research highlights the critical need for specialized datasets and tailored model training to address navigation challenges for PBLV and underscores implicit weaknesses in foundation models.
NYC-Indoor-VPR: A Long-Term Indoor Visual Place Recognition Dataset with Semi-Automatic Annotation
Mar 31, 2024



Visual Place Recognition (VPR) in indoor environments is beneficial to humans and robots for better localization and navigation. It is challenging due to appearance changes at various frequencies, and difficulties of obtaining ground truth metric trajectories for training and evaluation. This paper introduces the NYC-Indoor-VPR dataset, a unique and rich collection of over 36,000 images compiled from 13 distinct crowded scenes in New York City taken under varying lighting conditions with appearance changes. Each scene has multiple revisits across a year. To establish the ground truth for VPR, we propose a semiautomatic annotation approach that computes the positional information of each image. Our method specifically takes pairs of videos as input and yields matched pairs of images along with their estimated relative locations. The accuracy of this matching is refined by human annotators, who utilize our annotation software to correlate the selected keyframes. Finally, we present a benchmark evaluation of several state-of-the-art VPR algorithms using our annotated dataset, revealing its challenge and thus value for VPR research.
NYU-VPR: Long-Term Visual Place Recognition Benchmark with View Direction and Data Anonymization Influences
Oct 18, 2021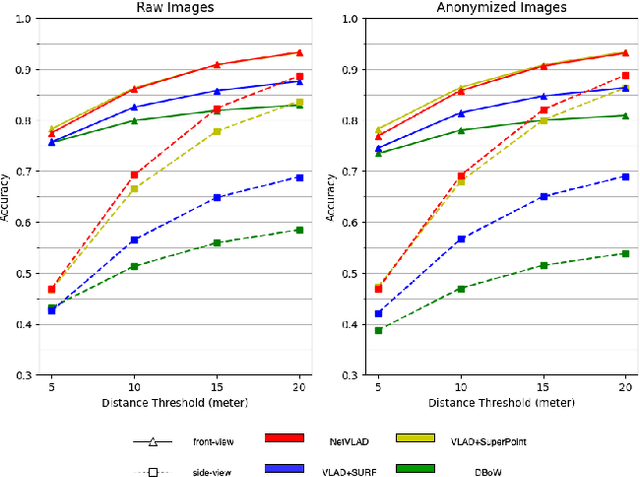
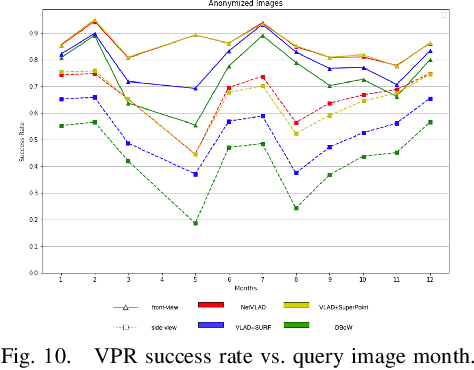


Visual place recognition (VPR) is critical in not only localization and mapping for autonomous driving vehicles, but also assistive navigation for the visually impaired population. To enable a long-term VPR system on a large scale, several challenges need to be addressed. First, different applications could require different image view directions, such as front views for self-driving cars while side views for the low vision people. Second, VPR in metropolitan scenes can often cause privacy concerns due to the imaging of pedestrian and vehicle identity information, calling for the need for data anonymization before VPR queries and database construction. Both factors could lead to VPR performance variations that are not well understood yet. To study their influences, we present the NYU-VPR dataset that contains more than 200,000 images over a 2km by 2km area near the New York University campus, taken within the whole year of 2016. We present benchmark results on several popular VPR algorithms showing that side views are significantly more challenging for current VPR methods while the influence of data anonymization is almost negligible, together with our hypothetical explanations and in-depth analysis.