 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNYC-Indoor-VPR: A Long-Term Indoor Visual Place Recognition Dataset with Semi-Automatic Annotation
Mar 31, 2024



Visual Place Recognition (VPR) in indoor environments is beneficial to humans and robots for better localization and navigation. It is challenging due to appearance changes at various frequencies, and difficulties of obtaining ground truth metric trajectories for training and evaluation. This paper introduces the NYC-Indoor-VPR dataset, a unique and rich collection of over 36,000 images compiled from 13 distinct crowded scenes in New York City taken under varying lighting conditions with appearance changes. Each scene has multiple revisits across a year. To establish the ground truth for VPR, we propose a semiautomatic annotation approach that computes the positional information of each image. Our method specifically takes pairs of videos as input and yields matched pairs of images along with their estimated relative locations. The accuracy of this matching is refined by human annotators, who utilize our annotation software to correlate the selected keyframes. Finally, we present a benchmark evaluation of several state-of-the-art VPR algorithms using our annotated dataset, revealing its challenge and thus value for VPR research.
Distillation Improves Visual Place Recognition for Low-Quality Queries
Oct 10, 2023
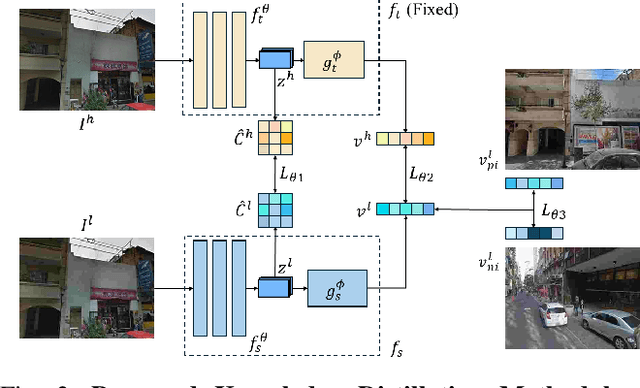
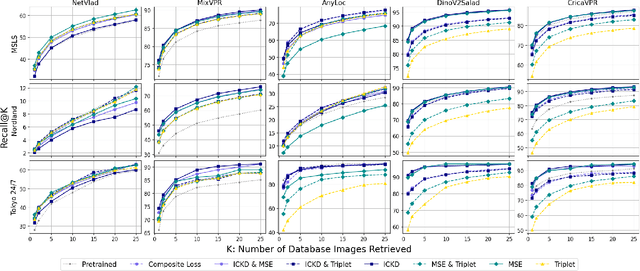
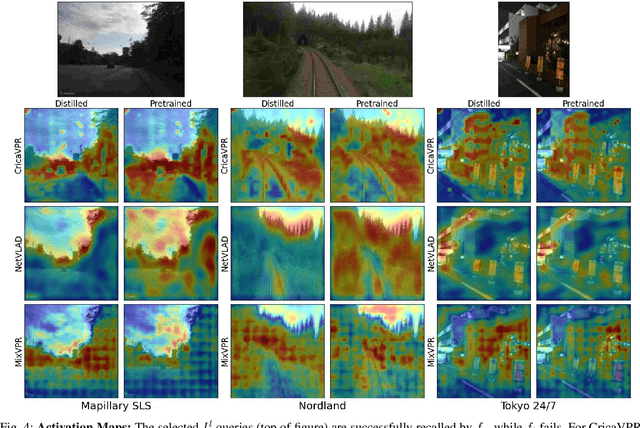
The shift to online computing for real-time visual localization often requires streaming query images/videos to a server for visual place recognition (VPR), where fast video transmission may result in reduced resolution or increased quantization. This compromises the quality of global image descriptors, leading to decreased VPR performance. To improve the low recall rate for low-quality query images, we present a simple yet effective method that uses high-quality queries only during training to distill better feature representations for deep-learning-based VPR, such as NetVLAD. Specifically, we use mean squared error (MSE) loss between the global descriptors of queries with different qualities, and inter-channel correlation knowledge distillation (ICKD) loss over their corresponding intermediate features. We validate our approach using the both Pittsburgh 250k dataset and our own indoor dataset with varying quantization levels. By fine-tuning NetVLAD parameters with our distillation-augmented losses, we achieve notable VPR recall-rate improvements over low-quality queries, as demonstrated in our extensive experimental results. We believe this work not only pushes forward the VPR research but also provides valuable insights for applications needing dependable place recognition under resource-limited conditions.
UNav: An Infrastructure-Independent Vision-Based Navigation System for People with Blindness and Low vision
Sep 22, 2022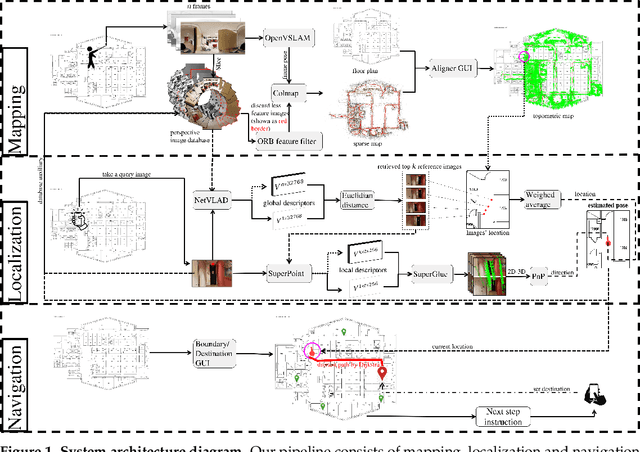

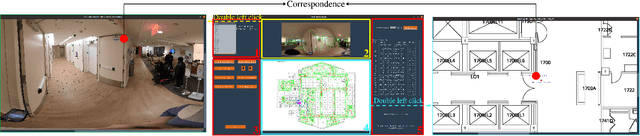

Vision-based localization approaches now underpin newly emerging navigation pipelines for myriad use cases from robotics to assistive technologies. Compared to sensor-based solutions, vision-based localization does not require pre-installed sensor infrastructure, which is costly, time-consuming, and/or often infeasible at scale. Herein, we propose a novel vision-based localization pipeline for a specific use case: navigation support for end-users with blindness and low vision. Given a query image taken by an end-user on a mobile application, the pipeline leverages a visual place recognition (VPR) algorithm to find similar images in a reference image database of the target space. The geolocations of these similar images are utilized in downstream tasks that employ a weighted-average method to estimate the end-user's location and a perspective-n-point (PnP) algorithm to estimate the end-user's direction. Additionally, this system implements Dijkstra's algorithm to calculate a shortest path based on a navigable map that includes trip origin and destination. The topometric map used for localization and navigation is built using a customized graphical user interface that projects a 3D reconstructed sparse map, built from a sequence of images, to the corresponding a priori 2D floor plan. Sequential images used for map construction can be collected in a pre-mapping step or scavenged through public databases/citizen science. The end-to-end system can be installed on any internet-accessible device with a camera that hosts a custom mobile application. For evaluation purposes, mapping and localization were tested in a complex hospital environment. The evaluation results demonstrate that our system can achieve localization with an average error of less than 1 meter without knowledge of the camera's intrinsic parameters, such as focal length.
Contrastive Spatial Reasoning on Multi-View Line Drawings
Apr 27, 2021
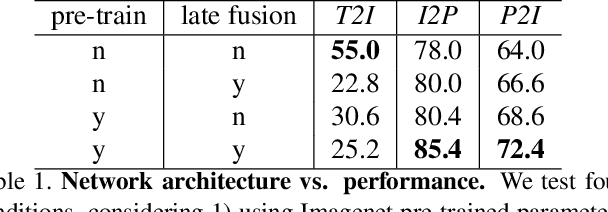
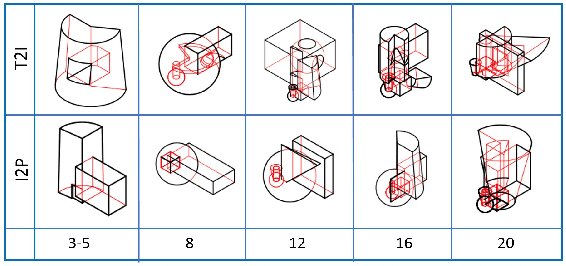

Spatial reasoning on multi-view line drawings by state-of-the-art supervised deep networks is recently shown with puzzling low performances on the SPARE3D dataset. To study the reason behind the low performance and to further our understandings of these tasks, we design controlled experiments on both input data and network designs. Guided by the hindsight from these experiment results, we propose a simple contrastive learning approach along with other network modifications to improve the baseline performance. Our approach uses a self-supervised binary classification network to compare the line drawing differences between various views of any two similar 3D objects. It enables deep networks to effectively learn detail-sensitive yet view-invariant line drawing representations of 3D objects. Experiments show that our method could significantly increase the baseline performance in SPARE3D, while some popular self-supervised learning methods cannot.