 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNav: An Infrastructure-Independent Vision-Based Navigation System for People with Blindness and Low vision
Sep 22, 2022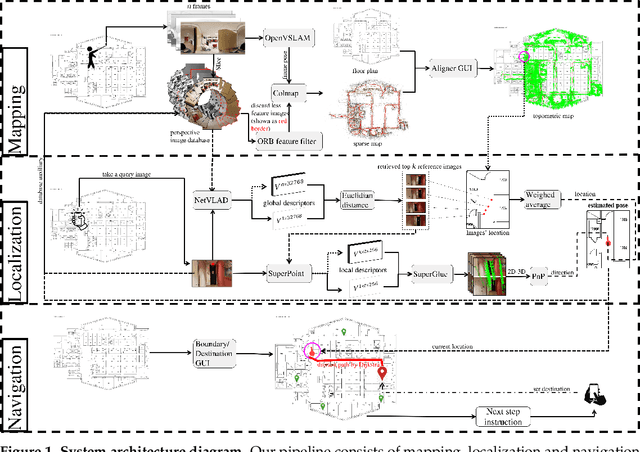

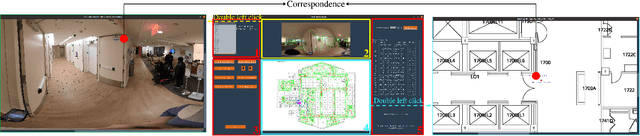

Vision-based localization approaches now underpin newly emerging navigation pipelines for myriad use cases from robotics to assistive technologies. Compared to sensor-based solutions, vision-based localization does not require pre-installed sensor infrastructure, which is costly, time-consuming, and/or often infeasible at scale. Herein, we propose a novel vision-based localization pipeline for a specific use case: navigation support for end-users with blindness and low vision. Given a query image taken by an end-user on a mobile application, the pipeline leverages a visual place recognition (VPR) algorithm to find similar images in a reference image database of the target space. The geolocations of these similar images are utilized in downstream tasks that employ a weighted-average method to estimate the end-user's location and a perspective-n-point (PnP) algorithm to estimate the end-user's direction. Additionally, this system implements Dijkstra's algorithm to calculate a shortest path based on a navigable map that includes trip origin and destination. The topometric map used for localization and navigation is built using a customized graphical user interface that projects a 3D reconstructed sparse map, built from a sequence of images, to the corresponding a priori 2D floor plan. Sequential images used for map construction can be collected in a pre-mapping step or scavenged through public databases/citizen science. The end-to-end system can be installed on any internet-accessible device with a camera that hosts a custom mobile application. For evaluation purposes, mapping and localization were tested in a complex hospital environment. The evaluation results demonstrate that our system can achieve localization with an average error of less than 1 meter without knowledge of the camera's intrinsic parameters, such as focal length.
Advancing COVID-19 Diagnosis with Privacy-Preserving Collaboration in Artificial Intelligence
Nov 18, 2021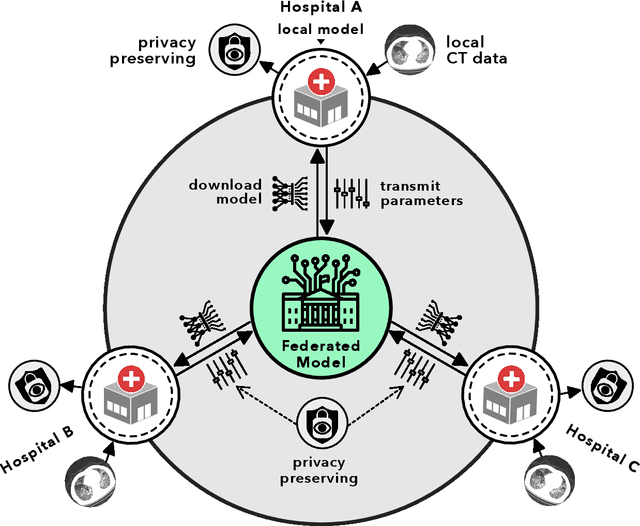
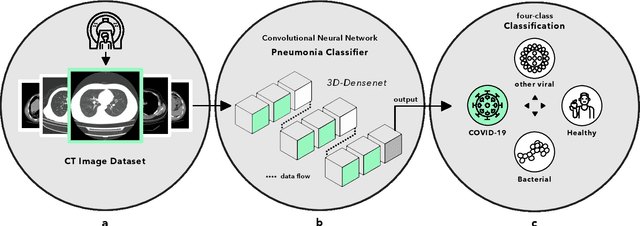
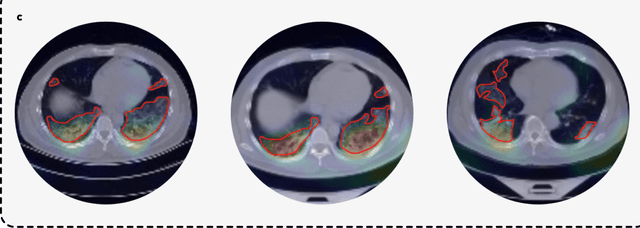
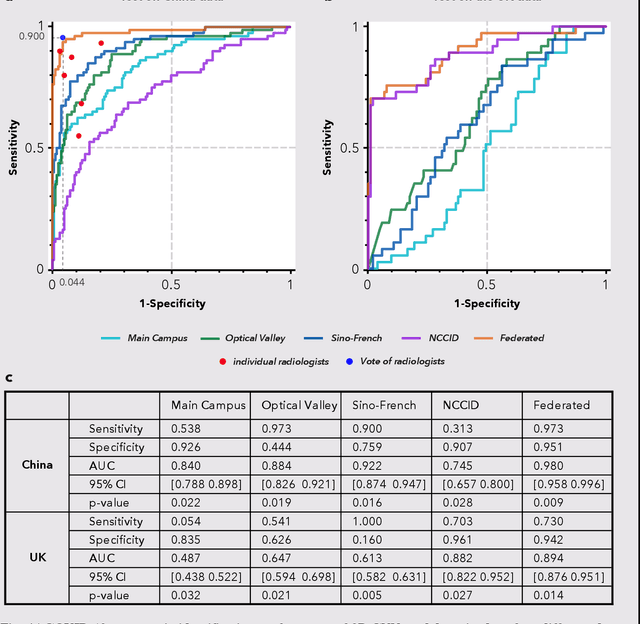
Artificial intelligence (AI) provides a promising substitution for streamlining COVID-19 diagnoses. However, concerns surrounding security and trustworthiness impede the collection of large-scale representative medical data, posing a considerable challenge for training a well-generalised model in clinical practices. To address this, we launch the Unified CT-COVID AI Diagnostic Initiative (UCADI), where the AI model can be distributedly trained and independently executed at each host institution under a federated learning framework (FL) without data sharing. Here we show that our FL model outperformed all the local models by a large yield (test sensitivity /specificity in China: 0.973/0.951, in the UK: 0.730/0.942), achieving comparable performance with a panel of professional radiologists. We further evaluated the model on the hold-out (collected from another two hospitals leaving out the FL) and heterogeneous (acquired with contrast materials) data, provided visual explanations for decisions made by the model, and analysed the trade-offs between the model performance and the communication costs in the federated training process. Our study is based on 9,573 chest computed tomography scans (CTs) from 3,336 patients collected from 23 hospitals located in China and the UK. Collectively, our work advanced the prospects of utilising federated learning for privacy-preserving AI in digital health.