 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopoSD: Topology-Enhanced Lane Segment Perception with SDMap Prior
Nov 22, 2024



Recent advances in autonomous driving systems have shifted towards reducing reliance on high-definition maps (HDMaps) due to the huge costs of annotation and maintenance. Instead, researchers are focusing on online vectorized HDMap construction using on-board sensors. However, sensor-only approaches still face challenges in long-range perception due to the restricted views imposed by the mounting angles of onboard cameras, just as human drivers also rely on bird's-eye-view navigation maps for a comprehensive understanding of road structures. To address these issues, we propose to train the perception model to "see" standard definition maps (SDMaps). We encode SDMap elements into neural spatial map representations and instance tokens, and then incorporate such complementary features as prior information to improve the bird's eye view (BEV) feature for lane geometry and topology decoding. Based on the lane segment representation framework, the model simultaneously predicts lanes, centrelines and their topology. To further enhance the ability of geometry prediction and topology reasoning, we also use a topology-guided decoder to refine the predictions by exploiting the mutual relationships between topological and geometric features. We perform extensive experiments on OpenLane-V2 datasets to validate the proposed method. The results show that our model outperforms state-of-the-art methods by a large margin, with gains of +6.7 and +9.1 on the mAP and topology metrics. Our analysis also reveals that models trained with SDMap noise augmentation exhibit enhanced robustness.
EIVEN: Efficient Implicit Attribute Value Extraction using Multimodal LLM
Apr 13, 2024
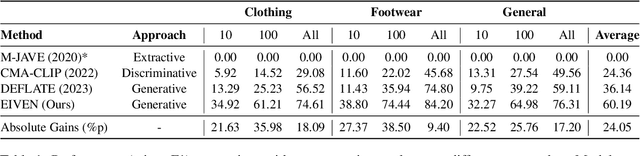
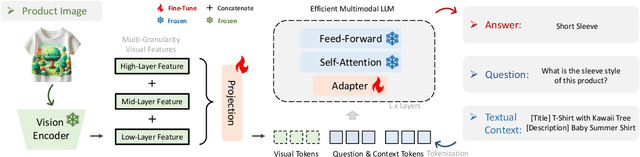
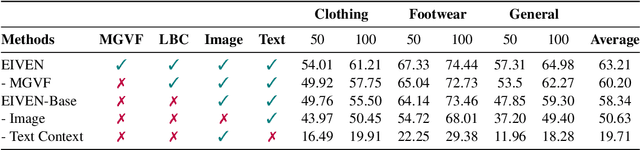
In e-commerce, accurately extracting product attribute values from multimodal data is crucial for improving user experience and operational efficiency of retailers. However, previous approaches to multimodal attribute value extraction often struggle with implicit attribute values embedded in images or text, rely heavily on extensive labeled data, and can easily confuse similar attribute values. To address these issues, we introduce EIVEN, a data- and parameter-efficient generative framework that pioneers the use of multimodal LLM for implicit attribute value extraction. EIVEN leverages the rich inherent knowledge of a pre-trained LLM and vision encoder to reduce reliance on labeled data. We also introduce a novel Learning-by-Comparison technique to reduce model confusion by enforcing attribute value comparison and difference identification. Additionally, we construct initial open-source datasets for multimodal implicit attribute value extraction. Our extensive experiments reveal that EIVEN significantly outperforms existing methods in extracting implicit attribute values while requiring less labeled data.
Logic-Scaffolding: Personalized Aspect-Instructed Recommendation Explanation Generation using LLMs
Dec 22, 2023



The unique capabilities of Large Language Models (LLMs), such as the natural language text generation ability, position them as strong candidates for providing explanation for recommendations. However, despite the size of the LLM, most existing models struggle to produce zero-shot explanations reliably. To address this issue, we propose a framework called Logic-Scaffolding, that combines the ideas of aspect-based explanation and chain-of-thought prompting to generate explanations through intermediate reasoning steps. In this paper, we share our experience in building the framework and present an interactive demonstration for exploring our results.
Addressing the Rank Degeneration in Sequential Recommendation via Singular Spectrum Smoothing
Jun 21, 2023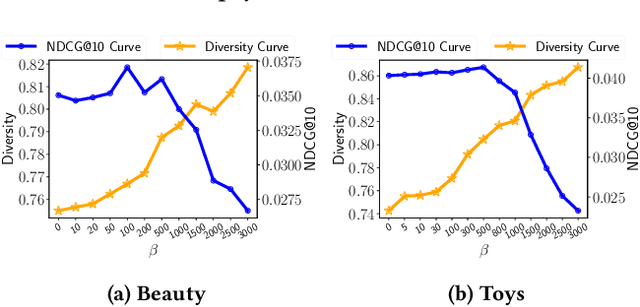
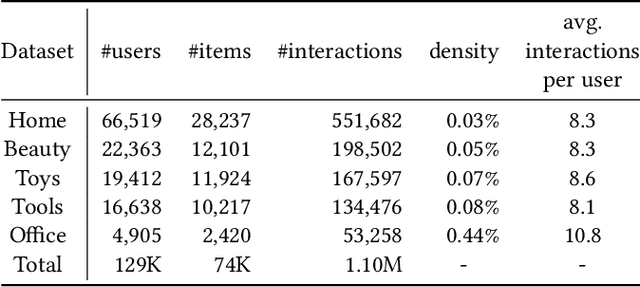
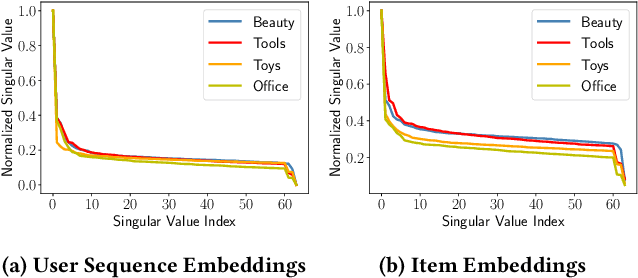
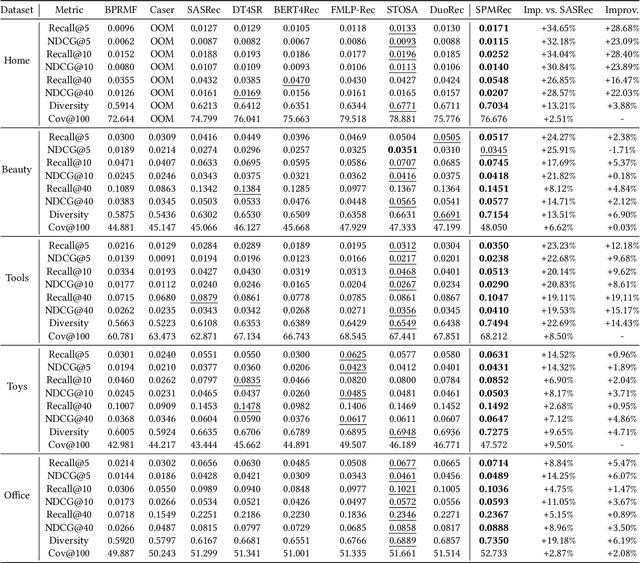
Sequential recommendation (SR) investigates the dynamic user preferences modeling and generates the next-item prediction. The next item preference is typically generated by the affinity between the sequence and item representations. However, both sequence and item representations suffer from the rank degeneration issue due to the data sparsity problem. The rank degeneration issue significantly impairs the representations for SR. This motivates us to measure how severe is the rank degeneration issue and alleviate the sequence and item representation rank degeneration issues simultaneously for SR. In this work, we theoretically connect the sequence representation degeneration issue with the item rank degeneration, particularly for short sequences and cold items. We also identify the connection between the fast singular value decay phenomenon and the rank collapse issue in transformer sequence output and item embeddings. We propose the area under the singular value curve metric to evaluate the severity of the singular value decay phenomenon and use it as an indicator of rank degeneration. We further introduce a novel singular spectrum smoothing regularization to alleviate the rank degeneration on both sequence and item sides, which is the Singular sPectrum sMoothing for sequential Recommendation (SPMRec). We also establish a correlation between the ranks of sequence and item embeddings and the rank of the user-item preference prediction matrix, which can affect recommendation diversity. We conduct experiments on four benchmark datasets to demonstrate the superiority of SPMRec over the state-of-the-art recommendation methods, especially in short sequences. The experiments also demonstrate a strong connection between our proposed singular spectrum smoothing and recommendation diversity.
Personalized Federated Domain Adaptation for Item-to-Item Recommendation
Jun 05, 2023Item-to-Item (I2I) recommendation is an important function in most recommendation systems, which generates replacement or complement suggestions for a particular item based on its semantic similarities to other cataloged items. Given that subsets of items in a recommendation system might be co-interacted with by the same set of customers, graph-based models, such as graph neural networks (GNNs), provide a natural framework to combine, ingest and extract valuable insights from such high-order relational interactions between cataloged items, as well as their metadata features, as has been shown in many recent studies. However, learning GNNs effectively for I2I requires ingesting a large amount of relational data, which might not always be available, especially in new, emerging market segments. To mitigate this data bottleneck, we postulate that recommendation patterns learned from existing mature market segments (with private data) could be adapted to build effective warm-start models for emerging ones. To achieve this, we propose and investigate a personalized federated modeling framework based on GNNs to summarize, assemble and adapt recommendation patterns across market segments with heterogeneous customer behaviors into effective local models. Our key contribution is a personalized graph adaptation model that bridges the gap between recent literature on federated GNNs and (non-graph) personalized federated learning, which either does not optimize for the adaptability of the federated model or is restricted to local models with homogeneous parameterization, excluding GNNs with heterogeneous local graphs.
Zero-shot Item-based Recommendation via Multi-task Product Knowledge Graph Pre-Training
May 12, 2023Existing recommender systems face difficulties with zero-shot items, i.e. items that have no historical interactions with users during the training stage. Though recent works extract universal item representation via pre-trained language models (PLMs), they ignore the crucial item relationships. This paper presents a novel paradigm for the Zero-Shot Item-based Recommendation (ZSIR) task, which pre-trains a model on product knowledge graph (PKG) to refine the item features from PLMs. We identify three challenges for pre-training PKG, which are multi-type relations in PKG, semantic divergence between item generic information and relations and domain discrepancy from PKG to downstream ZSIR task. We address the challenges by proposing four pre-training tasks and novel task-oriented adaptation (ToA) layers. Moreover, this paper discusses how to fine-tune the model on new recommendation task such that the ToA layers are adapted to ZSIR task. Comprehensive experiments on 18 markets dataset are conducted to verify the effectiveness of the proposed model in both knowledge prediction and ZSIR task.
Graph Collaborative Signals Denoising and Augmentation for Recommendation
Apr 10, 2023Graph collaborative filtering (GCF) is a popular technique for capturing high-order collaborative signals in recommendation systems. However, GCF's bipartite adjacency matrix, which defines the neighbors being aggregated based on user-item interactions, can be noisy for users/items with abundant interactions and insufficient for users/items with scarce interactions. Additionally, the adjacency matrix ignores user-user and item-item correlations, which can limit the scope of beneficial neighbors being aggregated. In this work, we propose a new graph adjacency matrix that incorporates user-user and item-item correlations, as well as a properly designed user-item interaction matrix that balances the number of interactions across all users. To achieve this, we pre-train a graph-based recommendation method to obtain users/items embeddings, and then enhance the user-item interaction matrix via top-K sampling. We also augment the symmetric user-user and item-item correlation components to the adjacency matrix. Our experiments demonstrate that the enhanced user-item interaction matrix with improved neighbors and lower density leads to significant benefits in graph-based recommendation. Moreover, we show that the inclusion of user-user and item-item correlations can improve recommendations for users with both abundant and insufficient interactions. The code is in \url{https://github.com/zfan20/GraphDA}.
* Short Paper Accepted by SIGIR 2023, 6 pages
Mutual Wasserstein Discrepancy Minimization for Sequential Recommendation
Jan 28, 2023Self-supervised sequential recommendation significantly improves recommendation performance by maximizing mutual information with well-designed data augmentations. However, the mutual information estimation is based on the calculation of Kullback Leibler divergence with several limitations, including asymmetrical estimation, the exponential need of the sample size, and training instability. Also, existing data augmentations are mostly stochastic and can potentially break sequential correlations with random modifications. These two issues motivate us to investigate an alternative robust mutual information measurement capable of modeling uncertainty and alleviating KL divergence limitations. To this end, we propose a novel self-supervised learning framework based on Mutual WasserStein discrepancy minimization MStein for the sequential recommendation. We propose the Wasserstein Discrepancy Measurement to measure the mutual information between augmented sequences. Wasserstein Discrepancy Measurement builds upon the 2-Wasserstein distance, which is more robust, more efficient in small batch sizes, and able to model the uncertainty of stochastic augmentation processes. We also propose a novel contrastive learning loss based on Wasserstein Discrepancy Measurement. Extensive experiments on four benchmark datasets demonstrate the effectiveness of MStein over baselines. More quantitative analyses show the robustness against perturbations and training efficiency in batch size. Finally, improvements analysis indicates better representations of popular users or items with significant uncertainty. The source code is at https://github.com/zfan20/MStein.
Episodes Discovery Recommendation with Multi-Source Augmentations
Jan 17, 2023



Recommender systems (RS) commonly retrieve potential candidate items for users from a massive number of items by modeling user interests based on historical interactions. However, historical interaction data is highly sparse, and most items are long-tail items, which limits the representation learning for item discovery. This problem is further augmented by the discovery of novel or cold-start items. For example, after a user displays interest in bitcoin financial investment shows in the podcast space, a recommender system may want to suggest, e.g., a newly released blockchain episode from a more technical show. Episode correlations help the discovery, especially when interaction data of episodes is limited. Accordingly, we build upon the classical Two-Tower model and introduce the novel Multi-Source Augmentations using a Contrastive Learning framework (MSACL) to enhance episode embedding learning by incorporating positive episodes from numerous correlated semantics. Extensive experiments on a real-world podcast recommendation dataset from a large audio streaming platform demonstrate the effectiveness of the proposed framework for user podcast exploration and cold-start episode recommendation.
Sequential Recommendation with Auxiliary Item Relationships via Multi-Relational Transformer
Oct 28, 2022Sequential Recommendation (SR) models user dynamics and predicts the next preferred items based on the user history. Existing SR methods model the 'was interacted before' item-item transitions observed in sequences, which can be viewed as an item relationship. However, there are multiple auxiliary item relationships, e.g., items from similar brands and with similar contents in real-world scenarios. Auxiliary item relationships describe item-item affinities in multiple different semantics and alleviate the long-lasting cold start problem in the recommendation. However, it remains a significant challenge to model auxiliary item relationships in SR. To simultaneously model high-order item-item transitions in sequences and auxiliary item relationships, we propose a Multi-relational Transformer capable of modeling auxiliary item relationships for SR (MT4SR). Specifically, we propose a novel self-attention module, which incorporates arbitrary item relationships and weights item relationships accordingly. Second, we regularize intra-sequence item relationships with a novel regularization module to supervise attentions computations. Third, for inter-sequence item relationship pairs, we introduce a novel inter-sequence related items modeling module. Finally, we conduct experiments on four benchmark datasets and demonstrate the effectiveness of MT4SR over state-of-the-art methods and the improvements on the cold start problem. The code is available at https://github.com/zfan20/MT4SR.