 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Dialog Neural Coreference Resolution: Balancing Efficiency and Accuracy in Large-Scale Systems
Apr 08, 2025Large-scale coreference resolution presents a significant challenge in natural language processing, necessitating a balance between efficiency and accuracy. In response to this challenge, we introduce an End-to-End Neural Coreference Resolution system tailored for large-scale applications. Our system efficiently identifies and resolves coreference links in text, ensuring minimal computational overhead without compromising on performance. By utilizing advanced neural network architectures, we incorporate various contextual embeddings and attention mechanisms, which enhance the quality of predictions for coreference pairs. Furthermore, we apply optimization strategies to accelerate processing speeds, making the system suitable for real-world deployment. Extensive evaluations conducted on benchmark datasets demonstrate that our model achieves improved accuracy compared to existing approaches, while effectively maintaining rapid inference times. Rigorous testing confirms the ability of our system to deliver precise coreference resolutions efficiently, thereby establishing a benchmark for future advancements in this field.
Cross-Document Contextual Coreference Resolution in Knowledge Graphs
Apr 08, 2025Coreference resolution across multiple documents poses a significant challenge in natural language processing, particularly within the domain of knowledge graphs. This study introduces an innovative method aimed at identifying and resolving references to the same entities that appear across differing texts, thus enhancing the coherence and collaboration of information. Our method employs a dynamic linking mechanism that associates entities in the knowledge graph with their corresponding textual mentions. By utilizing contextual embeddings along with graph-based inference strategies, we effectively capture the relationships and interactions among entities, thereby improving the accuracy of coreference resolution. Rigorous evaluations on various benchmark datasets highlight notable advancements in our approach over traditional methodologies. The results showcase how the contextual information derived from knowledge graphs enhances the understanding of complex relationships across documents, leading to better entity linking and information extraction capabilities in applications driven by knowledge. Our technique demonstrates substantial improvements in both precision and recall, underscoring its effectiveness in the area of cross-document coreference resolution.
Enhancing Coreference Resolution with Pretrained Language Models: Bridging the Gap Between Syntax and Semantics
Apr 08, 2025


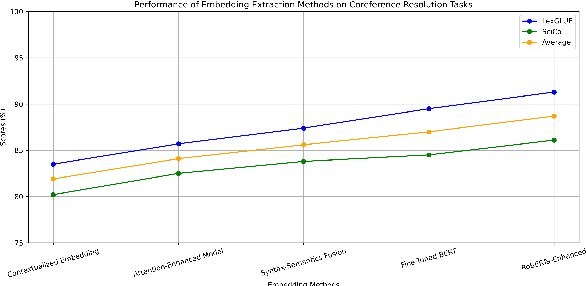
Large language models have made significant advancements in various natural language processing tasks, including coreference resolution. However, traditional methods often fall short in effectively distinguishing referential relationships due to a lack of integration between syntactic and semantic information. This study introduces an innovative framework aimed at enhancing coreference resolution by utilizing pretrained language models. Our approach combines syntax parsing with semantic role labeling to accurately capture finer distinctions in referential relationships. By employing state-of-the-art pretrained models to gather contextual embeddings and applying an attention mechanism for fine-tuning, we improve the performance of coreference tasks. Experimental results across diverse datasets show that our method surpasses conventional coreference resolution systems, achieving notable accuracy in disambiguating references. This development not only improves coreference resolution outcomes but also positively impacts other natural language processing tasks that depend on precise referential understanding.
Graph Collaborative Signals Denoising and Augmentation for Recommendation
Apr 10, 2023Graph collaborative filtering (GCF) is a popular technique for capturing high-order collaborative signals in recommendation systems. However, GCF's bipartite adjacency matrix, which defines the neighbors being aggregated based on user-item interactions, can be noisy for users/items with abundant interactions and insufficient for users/items with scarce interactions. Additionally, the adjacency matrix ignores user-user and item-item correlations, which can limit the scope of beneficial neighbors being aggregated. In this work, we propose a new graph adjacency matrix that incorporates user-user and item-item correlations, as well as a properly designed user-item interaction matrix that balances the number of interactions across all users. To achieve this, we pre-train a graph-based recommendation method to obtain users/items embeddings, and then enhance the user-item interaction matrix via top-K sampling. We also augment the symmetric user-user and item-item correlation components to the adjacency matrix. Our experiments demonstrate that the enhanced user-item interaction matrix with improved neighbors and lower density leads to significant benefits in graph-based recommendation. Moreover, we show that the inclusion of user-user and item-item correlations can improve recommendations for users with both abundant and insufficient interactions. The code is in \url{https://github.com/zfan20/GraphDA}.
* Short Paper Accepted by SIGIR 2023, 6 pages
Self-Regulation for Semantic Segmentation
Aug 22, 2021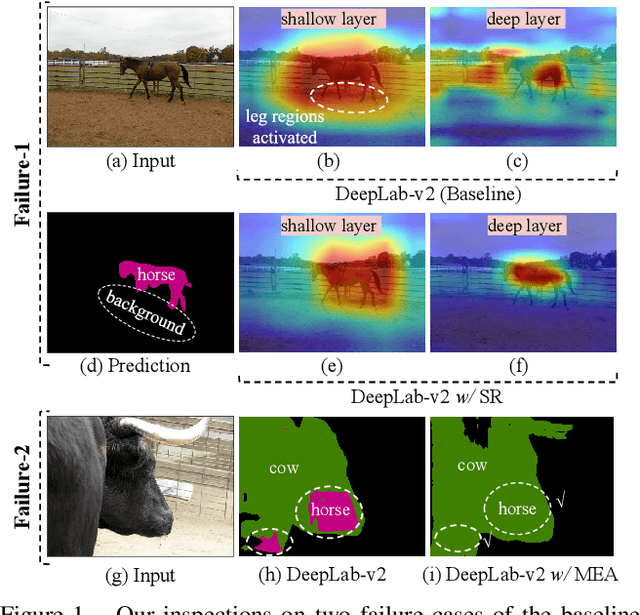
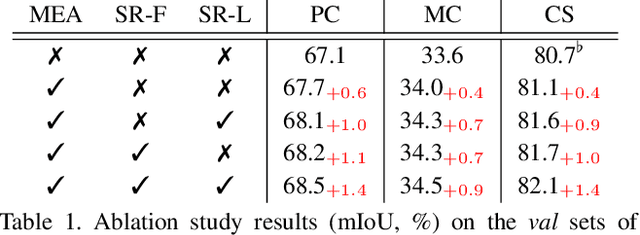
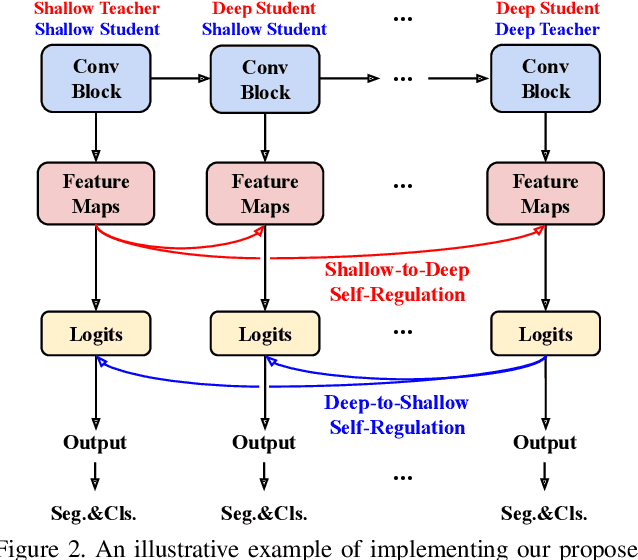
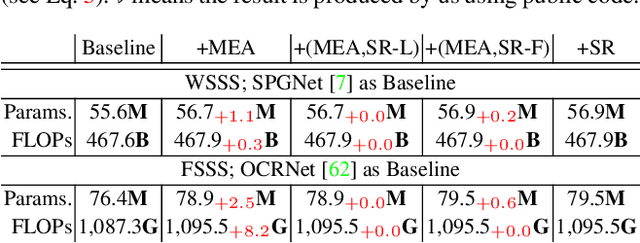
In this paper, we seek reasons for the two major failure cases in Semantic Segmentation (SS): 1) missing small objects or minor object parts, and 2) mislabeling minor parts of large objects as wrong classes. We have an interesting finding that Failure-1 is due to the underuse of detailed features and Failure-2 is due to the underuse of visual contexts. To help the model learn a better trade-off, we introduce several Self-Regulation (SR) losses for training SS neural networks. By "self", we mean that the losses are from the model per se without using any additional data or supervision. By applying the SR losses, the deep layer features are regulated by the shallow ones to preserve more details; meanwhile, shallow layer classification logits are regulated by the deep ones to capture more semantics. We conduct extensive experiments on both weakly and fully supervised SS tasks, and the results show that our approach consistently surpasses the baselines. We also validate that SR losses are easy to implement in various state-of-the-art SS models, e.g., SPGNet and OCRNet, incurring little computational overhead during training and none for testing.