 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Document Contextual Coreference Resolution in Knowledge Graphs
Apr 08, 2025Coreference resolution across multiple documents poses a significant challenge in natural language processing, particularly within the domain of knowledge graphs. This study introduces an innovative method aimed at identifying and resolving references to the same entities that appear across differing texts, thus enhancing the coherence and collaboration of information. Our method employs a dynamic linking mechanism that associates entities in the knowledge graph with their corresponding textual mentions. By utilizing contextual embeddings along with graph-based inference strategies, we effectively capture the relationships and interactions among entities, thereby improving the accuracy of coreference resolution. Rigorous evaluations on various benchmark datasets highlight notable advancements in our approach over traditional methodologies. The results showcase how the contextual information derived from knowledge graphs enhances the understanding of complex relationships across documents, leading to better entity linking and information extraction capabilities in applications driven by knowledge. Our technique demonstrates substantial improvements in both precision and recall, underscoring its effectiveness in the area of cross-document coreference resolution.
Enhancing Coreference Resolution with Pretrained Language Models: Bridging the Gap Between Syntax and Semantics
Apr 08, 2025


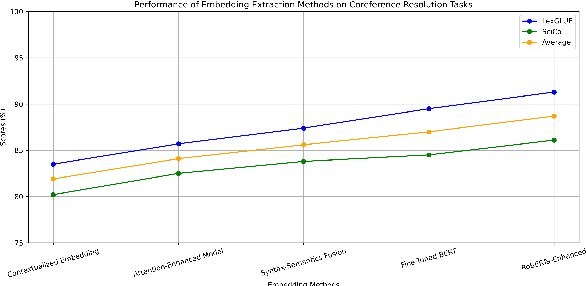
Large language models have made significant advancements in various natural language processing tasks, including coreference resolution. However, traditional methods often fall short in effectively distinguishing referential relationships due to a lack of integration between syntactic and semantic information. This study introduces an innovative framework aimed at enhancing coreference resolution by utilizing pretrained language models. Our approach combines syntax parsing with semantic role labeling to accurately capture finer distinctions in referential relationships. By employing state-of-the-art pretrained models to gather contextual embeddings and applying an attention mechanism for fine-tuning, we improve the performance of coreference tasks. Experimental results across diverse datasets show that our method surpasses conventional coreference resolution systems, achieving notable accuracy in disambiguating references. This development not only improves coreference resolution outcomes but also positively impacts other natural language processing tasks that depend on precise referential understanding.
End-to-End Dialog Neural Coreference Resolution: Balancing Efficiency and Accuracy in Large-Scale Systems
Apr 08, 2025Large-scale coreference resolution presents a significant challenge in natural language processing, necessitating a balance between efficiency and accuracy. In response to this challenge, we introduce an End-to-End Neural Coreference Resolution system tailored for large-scale applications. Our system efficiently identifies and resolves coreference links in text, ensuring minimal computational overhead without compromising on performance. By utilizing advanced neural network architectures, we incorporate various contextual embeddings and attention mechanisms, which enhance the quality of predictions for coreference pairs. Furthermore, we apply optimization strategies to accelerate processing speeds, making the system suitable for real-world deployment. Extensive evaluations conducted on benchmark datasets demonstrate that our model achieves improved accuracy compared to existing approaches, while effectively maintaining rapid inference times. Rigorous testing confirms the ability of our system to deliver precise coreference resolutions efficiently, thereby establishing a benchmark for future advancements in this field.
SPA: Towards A Computational Friendly Cloud-Base and On-Devices Collaboration Seq2seq Personalized Generation
Mar 11, 2024Large language models(LLMs) have shown its outperforming ability on various tasks and question answering. However, LLMs require high computation cost and large memory cost. At the same time, LLMs may cause privacy leakage when training or prediction procedure contains sensitive information. In this paper, we propose SPA(Side Plugin Adaption), a lightweight architecture for fast on-devices inference and privacy retaining on the constraints of strict on-devices computation and memory constraints. Compared with other on-devices seq2seq generation, SPA could make a fast and stable inference on low-resource constraints, allowing it to obtain cost effiency. Our method establish an interaction between a pretrained LLMs on-cloud and additive parameters on-devices, which could provide the knowledge on both pretrained LLMs and private personal feature.Further more, SPA provides a framework to keep feature-base parameters on private guaranteed but low computational devices while leave the parameters containing general information on the high computational devices.