 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePADD: Path-Aligned Decompression Distillation for Non-Router Teacher to Guide MoE Student Learning
Jun 09, 2026As large language models (LLMs) continue to scale, it becomes increasingly challenging to grow model capacity under fixed computation budgets. We propose Path-Aligned Decompression Distillation (PADD), a framework for distilling knowledge from dense teachers without explicit routing into mixture-of-experts (MoE) students while learning high-quality routing policies. PADD organizes knowledge distillation into four stages in two phases: an initialization phase (Stage I) that builds diverse functionality in the student's experts through teacher neuron clustering and student-expert warmup, and a training phase (Stages II--IV) that integrates online adaptive distillation, path-refined policy optimization, and reward-augmented load balancing in a single training pipeline. Experiments on mathematical reasoning benchmarks demonstrate that PADD yields substantial gains over strong baselines at the same inference cost and that the MoE student can match or surpass its dense teacher. They also demonstrate effective teacher-to-student knowledge distillation and stable routing behavior.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Dep-Search: Learning Dependency-Aware Reasoning Traces with Persistent Memory
Jan 26, 2026Large Language Models (LLMs) have demonstrated remarkable capabilities in complex reasoning tasks, particularly when augmented with search mechanisms that enable systematic exploration of external knowledge bases. The field has evolved from traditional retrieval-augmented generation (RAG) frameworks to more sophisticated search-based frameworks that orchestrate multi-step reasoning through explicit search strategies. However, existing search frameworks still rely heavily on implicit natural language reasoning to determine search strategies and how to leverage retrieved information across reasoning steps. This reliance on implicit reasoning creates fundamental challenges for managing dependencies between sub-questions, efficiently reusing previously retrieved knowledge, and learning optimal search strategies through reinforcement learning. To address these limitations, we propose Dep-Search, a dependency-aware search framework that advances beyond existing search frameworks by integrating structured reasoning, retrieval, and persistent memory through GRPO. Dep-Search introduces explicit control mechanisms that enable the model to decompose questions with dependency relationships, retrieve information when needed, access previously stored knowledge from memory, and summarize long reasoning contexts into reusable memory entries. Through extensive experiments on seven diverse question answering datasets, we demonstrate that Dep-Search significantly enhances LLMs' ability to tackle complex multi-hop reasoning tasks, achieving substantial improvements over strong baselines across different model scales.
ToolGate: Contract-Grounded and Verified Tool Execution for LLMs
Jan 08, 2026Large Language Models (LLMs) augmented with external tools have demonstrated remarkable capabilities in complex reasoning tasks. However, existing frameworks rely heavily on natural language reasoning to determine when tools can be invoked and whether their results should be committed, lacking formal guarantees for logical safety and verifiability. We present \textbf{ToolGate}, a forward execution framework that provides logical safety guarantees and verifiable state evolution for LLM tool calling. ToolGate maintains an explicit symbolic state space as a typed key-value mapping representing trusted world information throughout the reasoning process. Each tool is formalized as a Hoare-style contract consisting of a precondition and a postcondition, where the precondition gates tool invocation by checking whether the current state satisfies the required conditions, and the postcondition determines whether the tool's result can be committed to update the state through runtime verification. Our approach guarantees that the symbolic state evolves only through verified tool executions, preventing invalid or hallucinated results from corrupting the world representation. Experimental validation demonstrates that ToolGate significantly improves the reliability and verifiability of tool-augmented LLM systems while maintaining competitive performance on complex multi-step reasoning tasks. This work establishes a foundation for building more trustworthy and debuggable AI systems that integrate language models with external tools.
NC2C: Automated Convexification of Generic Non-Convex Optimization Problems
Jan 08, 2026Non-convex optimization problems are pervasive across mathematical programming, engineering design, and scientific computing, often posing intractable challenges for traditional solvers due to their complex objective functions and constrained landscapes. To address the inefficiency of manual convexification and the over-reliance on expert knowledge, we propose NC2C, an LLM-based end-to-end automated framework designed to transform generic non-convex optimization problems into solvable convex forms using large language models. NC2C leverages LLMs' mathematical reasoning capabilities to autonomously detect non-convex components, select optimal convexification strategies, and generate rigorous convex equivalents. The framework integrates symbolic reasoning, adaptive transformation techniques, and iterative validation, equipped with error correction loops and feasibility domain correction mechanisms to ensure the robustness and validity of transformed problems. Experimental results on a diverse dataset of 100 generic non-convex problems demonstrate that NC2C achieves an 89.3\% execution rate and a 76\% success rate in producing feasible, high-quality convex transformations. This outperforms baseline methods by a significant margin, highlighting NC2C's ability to leverage LLMs for automated non-convex to convex transformation, reduce expert dependency, and enable efficient deployment of convex solvers for previously intractable optimization tasks.
LLM-OptiRA: LLM-Driven Optimization of Resource Allocation for Non-Convex Problems in Wireless Communications
May 04, 2025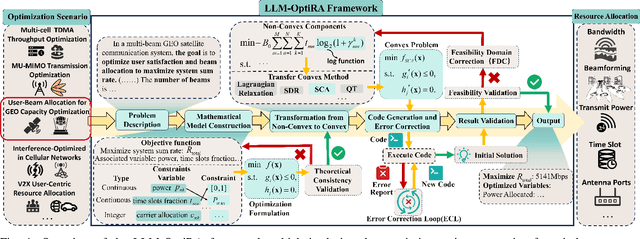
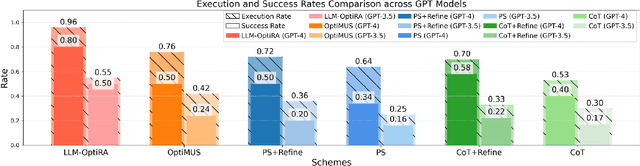
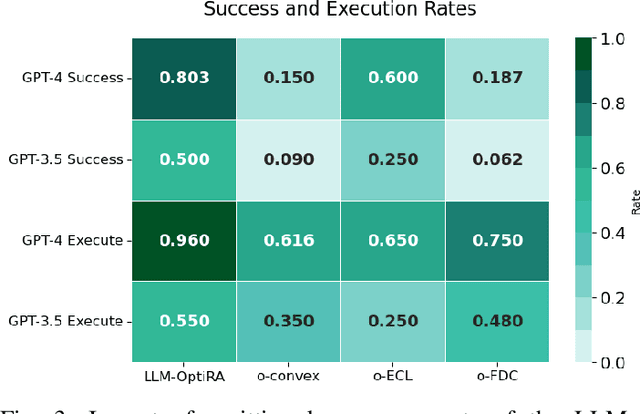
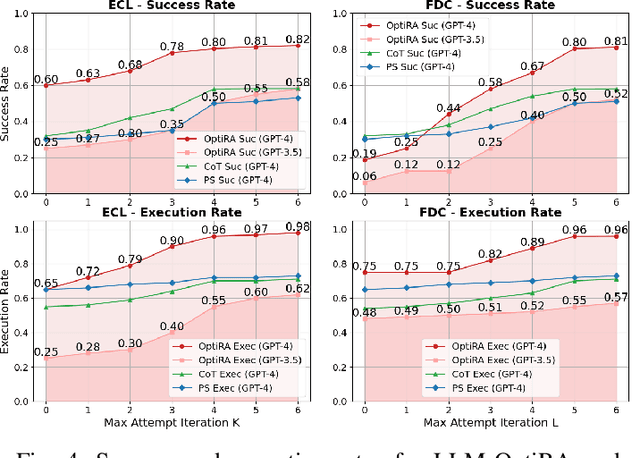
Solving non-convex resource allocation problems poses significant challenges in wireless communication systems, often beyond the capability of traditional optimization techniques. To address this issue, we propose LLM-OptiRA, the first framework that leverages large language models (LLMs) to automatically detect and transform non-convex components into solvable forms, enabling fully automated resolution of non-convex resource allocation problems in wireless communication systems. LLM-OptiRA not only simplifies problem-solving by reducing reliance on expert knowledge, but also integrates error correction and feasibility validation mechanisms to ensure robustness. Experimental results show that LLM-OptiRA achieves an execution rate of 96% and a success rate of 80% on GPT-4, significantly outperforming baseline approaches in complex optimization tasks across diverse scenarios.
ASMA-Tune: Unlocking LLMs' Assembly Code Comprehension via Structural-Semantic Instruction Tuning
Mar 14, 2025Analysis and comprehension of assembly code are crucial in various applications, such as reverse engineering. However, the low information density and lack of explicit syntactic structures in assembly code pose significant challenges. Pioneering approaches with masked language modeling (MLM)-based methods have been limited by facilitating natural language interaction. While recent methods based on decoder-focused large language models (LLMs) have significantly enhanced semantic representation, they still struggle to capture the nuanced and sparse semantics in assembly code. In this paper, we propose Assembly Augmented Tuning (ASMA-Tune), an end-to-end structural-semantic instruction-tuning framework. Our approach synergizes encoder architectures with decoder-based LLMs through projector modules to enable comprehensive code understanding. Experiments show that ASMA-Tune outperforms existing benchmarks, significantly enhancing assembly code comprehension and instruction-following abilities. Our model and dataset are public at https://github.com/wxy3596/ASMA-Tune.
Movable-Antenna Aided Secure Transmission for RIS-ISAC Systems
Oct 04, 2024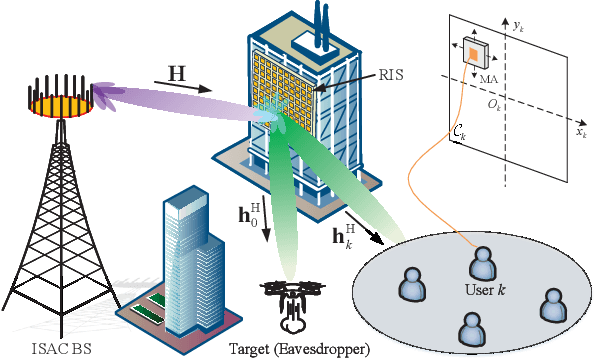
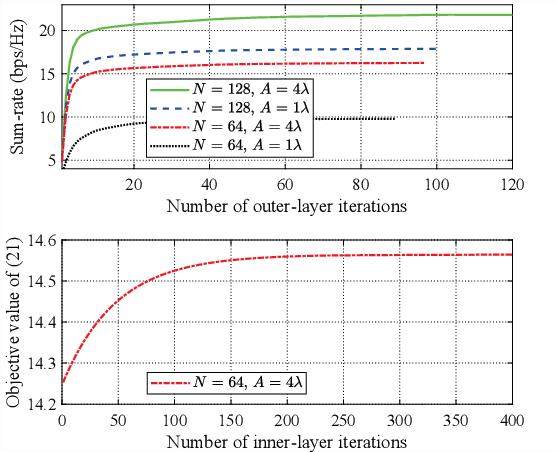
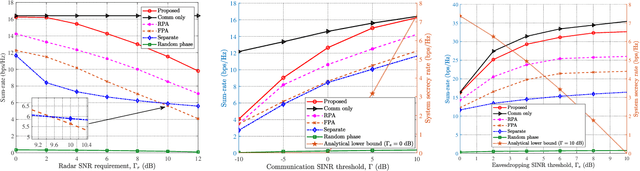

Integrated sensing and communication (ISAC) systems have the issue of secrecy leakage when using the ISAC waveforms for sensing, thus posing a potential risk for eavesdropping. To address this problem, we propose to employ movable antennas (MAs) and reconfigurable intelligent surface (RIS) to enhance the physical layer security (PLS) performance of ISAC systems, where an eavesdropping target potentially wiretaps the signals transmitted by the base station (BS). To evaluate the synergistic performance gain provided by MAs and RIS, we formulate an optimization problem for maximizing the sum-rate of the users by jointly optimizing the transmit/receive beamformers of the BS, the reflection coefficients of the RIS, and the positions of MAs at communication users, subject to a minimum communication rate requirement for each user, a minimum radar sensing requirement, and a maximum secrecy leakage to the eavesdropping target. To solve this non-convex problem with highly coupled variables, a two-layer penalty-based algorithm is developed by updating the penalty parameter in the outer-layer iterations to achieve a trade-off between the optimality and feasibility of the solution. In the inner-layer iterations, the auxiliary variables are first obtained with semi-closed-form solutions using Lagrange duality. Then, the receive beamformer filter at the BS is optimized by solving a Rayleigh-quotient subproblem. Subsequently, the transmit beamformer matrix is obtained by solving a convex subproblem. Finally, the majorization-minimization (MM) algorithm is employed to optimize the RIS reflection coefficients and the positions of MAs. Extensive simulation results validate the considerable benefits of the proposed MAs-aided RIS-ISAC systems in enhancing security performance compared to traditional fixed position antenna (FPA)-based systems.
Bridging Context Gaps: Leveraging Coreference Resolution for Long Contextual Understanding
Oct 02, 2024
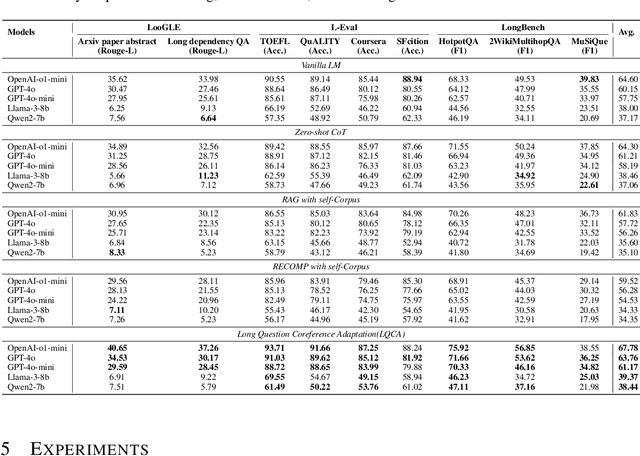
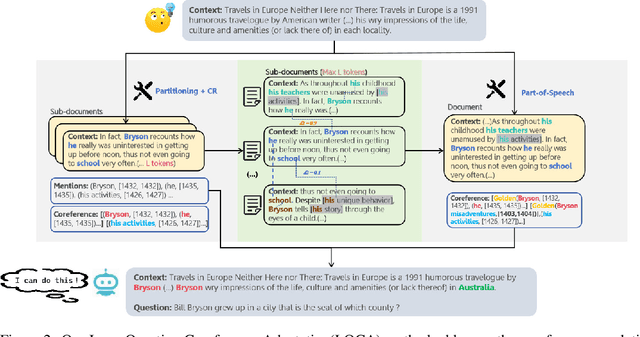
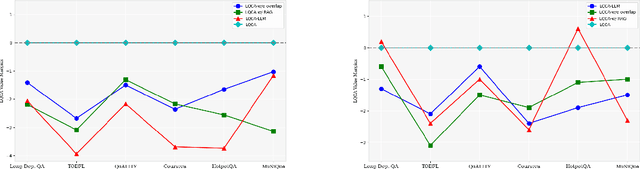
Large language models (LLMs) have shown remarkable capabilities in natural language processing; however, they still face difficulties when tasked with understanding lengthy contexts and executing effective question answering. These challenges often arise due to the complexity and ambiguity present in longer texts. To enhance the performance of LLMs in such scenarios, we introduce the Long Question Coreference Adaptation (LQCA) method. This innovative framework focuses on coreference resolution tailored to long contexts, allowing the model to identify and manage references effectively. The LQCA method encompasses four key steps: resolving coreferences within sub-documents, computing the distances between mentions, defining a representative mention for coreference, and answering questions through mention replacement. By processing information systematically, the framework provides easier-to-handle partitions for LLMs, promoting better understanding. Experimental evaluations on a range of LLMs and datasets have yielded positive results, with a notable improvements on OpenAI-o1-mini and GPT-4o models, highlighting the effectiveness of leveraging coreference resolution to bridge context gaps in question answering.
MemDPT: Differential Privacy for Memory Efficient Language Models
Jun 16, 2024
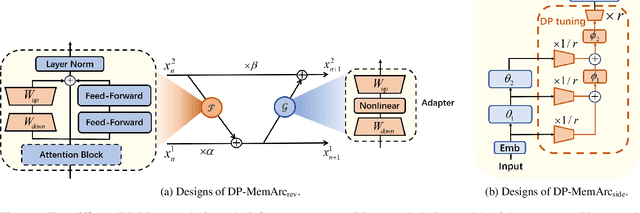
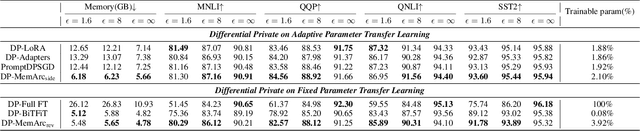
Large language models have consistently demonstrated remarkable performance across a wide spectrum of applications. Nonetheless, the deployment of these models can inadvertently expose user privacy to potential risks. The substantial memory demands of these models during training represent a significant resource consumption challenge. The sheer size of these models imposes a considerable burden on memory resources, which is a matter of significant concern in practice. In this paper, we present an innovative training framework MemDPT that not only reduces the memory cost of large language models but also places a strong emphasis on safeguarding user data privacy. MemDPT provides edge network and reverse network designs to accommodate various differential privacy memory-efficient fine-tuning schemes. Our approach not only achieves $2 \sim 3 \times$ memory optimization but also provides robust privacy protection, ensuring that user data remains secure and confidential. Extensive experiments have demonstrated that MemDPT can effectively provide differential privacy efficient fine-tuning across various task scenarios.