 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Imitation Learning Under Measurement Error and Distribution Shift
Jan 29, 2026We study offline imitation learning (IL) when part of the decision-relevant state is observed only through noisy measurements and the distribution may change between training and deployment. Such settings induce spurious state-action correlations, so standard behavioral cloning (BC) -- whether conditioning on raw measurements or ignoring them -- can converge to systematically biased policies under distribution shift. We propose a general framework for IL under measurement error, inspired by explicitly modeling the causal relationships among the variables, yielding a target that retains a causal interpretation and is robust to distribution shift. Building on ideas from proximal causal inference, we introduce \texttt{CausIL}, which treats noisy state observations as proxy variables, and we provide identification conditions under which the target policy is recoverable from demonstrations without rewards or interactive expert queries. We develop estimators for both discrete and continuous state spaces; for continuous settings, we use an adversarial procedure over RKHS function classes to learn the required parameters. We evaluate \texttt{CausIL} on semi-simulated longitudinal data from the PhysioNet/Computing in Cardiology Challenge 2019 cohort and demonstrate improved robustness to distribution shift compared to BC baselines.
Enhancing Mathematical Reasoning in Large Language Models with Self-Consistency-Based Hallucination Detection
Apr 13, 2025Large language models (LLMs) have demonstrated strong mathematical reasoning capabilities but remain susceptible to hallucinations producing plausible yet incorrect statements especially in theorem proving, symbolic manipulation, and numerical computation. While self-consistency (SC) has been explored as a means to improve factuality in LLMs, existing approaches primarily apply SC to final-answer selection, neglecting the logical consistency of intermediate reasoning steps. In this work, we introduce a structured self-consistency framework designed to enhance the reliability of mathematical reasoning. Our method enforces self-consistency across intermediate steps and final outputs, reducing logical inconsistencies and hallucinations. We evaluate our approach across three core mathematical tasks: theorem proving, symbolic transformation, and numerical computation. Experimental results demonstrate that SC significantly improves proof validity, symbolic reasoning accuracy, and numerical stability while maintaining computational efficiency. Further analysis reveals that structured self-consistency not only enhances problem-solving accuracy but also reduces the variance of model-generated outputs. These findings highlight self-consistency as a robust mechanism for improving mathematical reasoning in LLMs, paving the way for more reliable and interpretable AI-driven mathematics.
Bridging Context Gaps: Leveraging Coreference Resolution for Long Contextual Understanding
Oct 02, 2024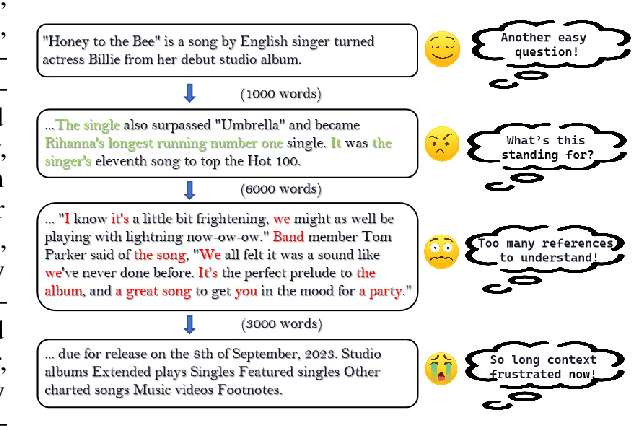
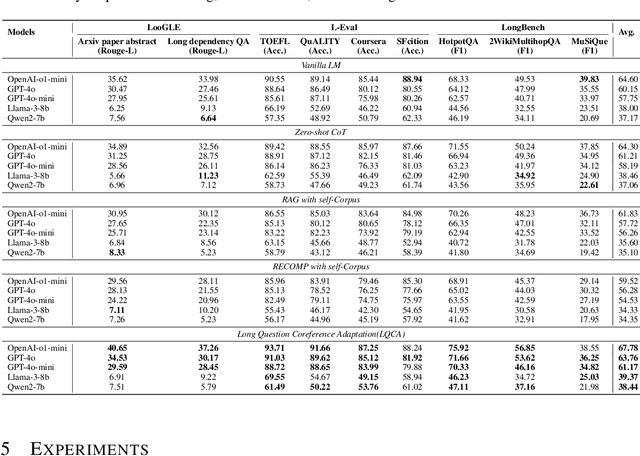
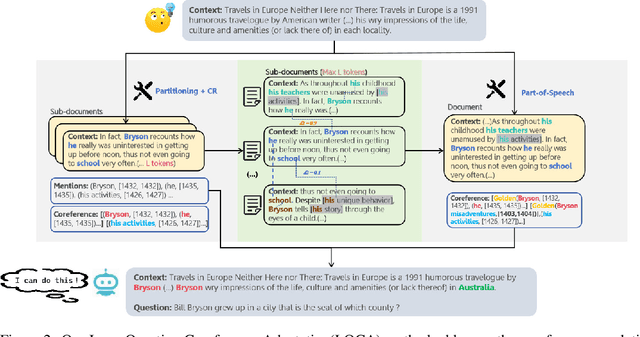
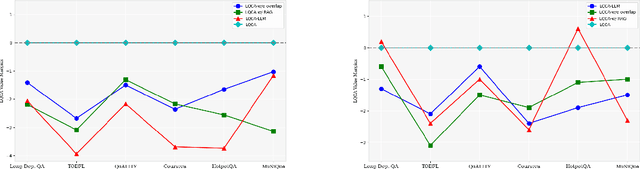
Large language models (LLMs) have shown remarkable capabilities in natural language processing; however, they still face difficulties when tasked with understanding lengthy contexts and executing effective question answering. These challenges often arise due to the complexity and ambiguity present in longer texts. To enhance the performance of LLMs in such scenarios, we introduce the Long Question Coreference Adaptation (LQCA) method. This innovative framework focuses on coreference resolution tailored to long contexts, allowing the model to identify and manage references effectively. The LQCA method encompasses four key steps: resolving coreferences within sub-documents, computing the distances between mentions, defining a representative mention for coreference, and answering questions through mention replacement. By processing information systematically, the framework provides easier-to-handle partitions for LLMs, promoting better understanding. Experimental evaluations on a range of LLMs and datasets have yielded positive results, with a notable improvements on OpenAI-o1-mini and GPT-4o models, highlighting the effectiveness of leveraging coreference resolution to bridge context gaps in question answering.
Electroencephalogram Emotion Recognition via AUC Maximization
Aug 16, 2024



Imbalanced datasets pose significant challenges in areas including neuroscience, cognitive science, and medical diagnostics, where accurately detecting minority classes is essential for robust model performance. This study addresses the issue of class imbalance, using the `Liking' label in the DEAP dataset as an example. Such imbalances are often overlooked by prior research, which typically focuses on the more balanced arousal and valence labels and predominantly uses accuracy metrics to measure model performance. To tackle this issue, we adopt numerical optimization techniques aimed at maximizing the area under the curve (AUC), thus enhancing the detection of underrepresented classes. Our approach, which begins with a linear classifier, is compared against traditional linear classifiers, including logistic regression and support vector machines (SVM). Our method significantly outperforms these models, increasing recall from 41.6\% to 79.7\% and improving the F1-score from 0.506 to 0.632. These results highlight the efficacy of AUC maximization via numerical optimization in managing imbalanced datasets, providing an effective solution for enhancing predictive accuracy in detecting minority but crucial classes in out-of-sample datasets.
Root Cause Attribution of Delivery Risks via Causal Discovery with Reinforcement Learning
Aug 11, 2024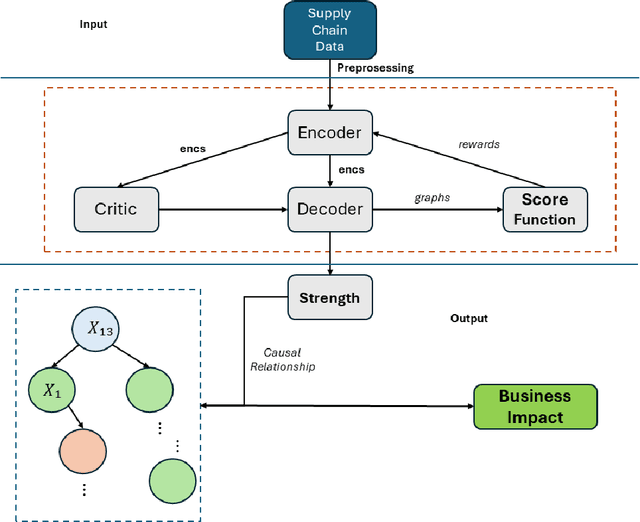
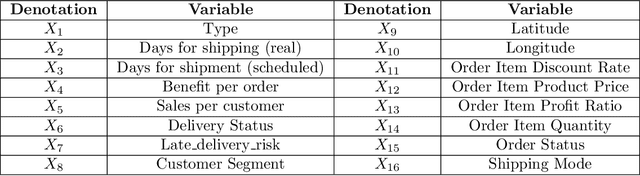


This paper presents a novel approach to root cause attribution of delivery risks within supply chains by integrating causal discovery with reinforcement learning. As supply chains become increasingly complex, traditional methods of root cause analysis struggle to capture the intricate interrelationships between various factors, often leading to spurious correlations and suboptimal decision-making. Our approach addresses these challenges by leveraging causal discovery to identify the true causal relationships between operational variables, and reinforcement learning to iteratively refine the causal graph. This method enables the accurate identification of key drivers of late deliveries, such as shipping mode and delivery status, and provides actionable insights for optimizing supply chain performance. We apply our approach to a real-world supply chain dataset, demonstrating its effectiveness in uncovering the underlying causes of delivery delays and offering strategies for mitigating these risks. The findings have significant implications for improving operational efficiency, customer satisfaction, and overall profitability within supply chains.
Dynamic Hypergraph-Enhanced Prediction of Sequential Medical Visits
Aug 08, 2024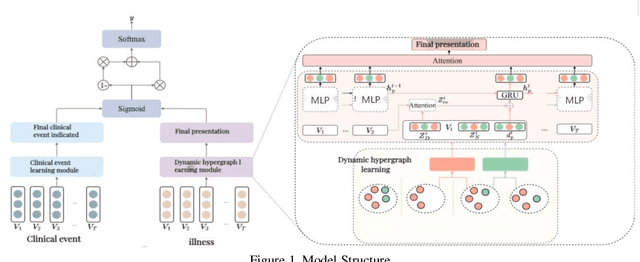
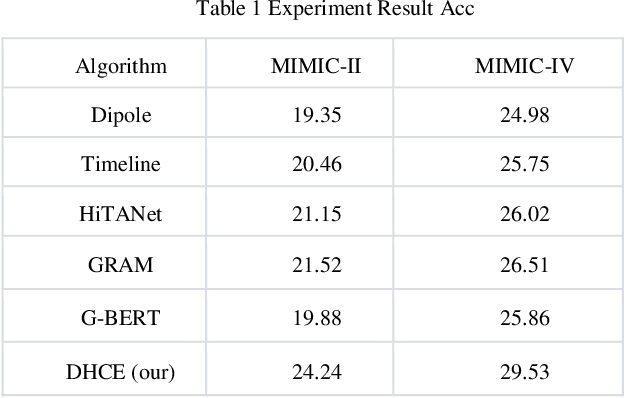
This study introduces a pioneering Dynamic Hypergraph Networks (DHCE) model designed to predict future medical diagnoses from electronic health records with enhanced accuracy. The DHCE model innovates by identifying and differentiating acute and chronic diseases within a patient's visit history, constructing dynamic hypergraphs that capture the complex, high-order interactions between diseases. It surpasses traditional recurrent neural networks and graph neural networks by effectively integrating clinical event data, reflected through medical language model-assisted encoding, into a robust patient representation. Through extensive experiments on two benchmark datasets, MIMIC-III and MIMIC-IV, the DHCE model exhibits superior performance, significantly outpacing established baseline models in the precision of sequential diagnosis prediction.
Attention Mechanism and Context Modeling System for Text Mining Machine Translation
Aug 08, 2024



This paper advances a novel architectural schema anchored upon the Transformer paradigm and innovatively amalgamates the K-means categorization algorithm to augment the contextual apprehension capabilities of the schema. The transformer model performs well in machine translation tasks due to its parallel computing power and multi-head attention mechanism. However, it may encounter contextual ambiguity or ignore local features when dealing with highly complex language structures. To circumvent this constraint, this exposition incorporates the K-Means algorithm, which is used to stratify the lexis and idioms of the input textual matter, thereby facilitating superior identification and preservation of the local structure and contextual intelligence of the language. The advantage of this combination is that K-Means can automatically discover the topic or concept regions in the text, which may be directly related to translation quality. Consequently, the schema contrived herein enlists K-Means as a preparatory phase antecedent to the Transformer and recalibrates the multi-head attention weights to assist in the discrimination of lexis and idioms bearing analogous semantics or functionalities. This ensures the schema accords heightened regard to the contextual intelligence embodied by these clusters during the training phase, rather than merely focusing on locational intelligence.
Research on Autonomous Driving Decision-making Strategies based Deep Reinforcement Learning
Aug 06, 2024



The behavior decision-making subsystem is a key component of the autonomous driving system, which reflects the decision-making ability of the vehicle and the driver, and is an important symbol of the high-level intelligence of the vehicle. However, the existing rule-based decision-making schemes are limited by the prior knowledge of designers, and it is difficult to cope with complex and changeable traffic scenarios. In this work, an advanced deep reinforcement learning model is adopted, which can autonomously learn and optimize driving strategies in a complex and changeable traffic environment by modeling the driving decision-making process as a reinforcement learning problem. Specifically, we used Deep Q-Network (DQN) and Proximal Policy Optimization (PPO) for comparative experiments. DQN guides the agent to choose the best action by approximating the state-action value function, while PPO improves the decision-making quality by optimizing the policy function. We also introduce improvements in the design of the reward function to promote the robustness and adaptability of the model in real-world driving situations. Experimental results show that the decision-making strategy based on deep reinforcement learning has better performance than the traditional rule-based method in a variety of driving tasks.
Multiple Greedy Quasi-Newton Methods for Saddle Point Problems
Aug 01, 2024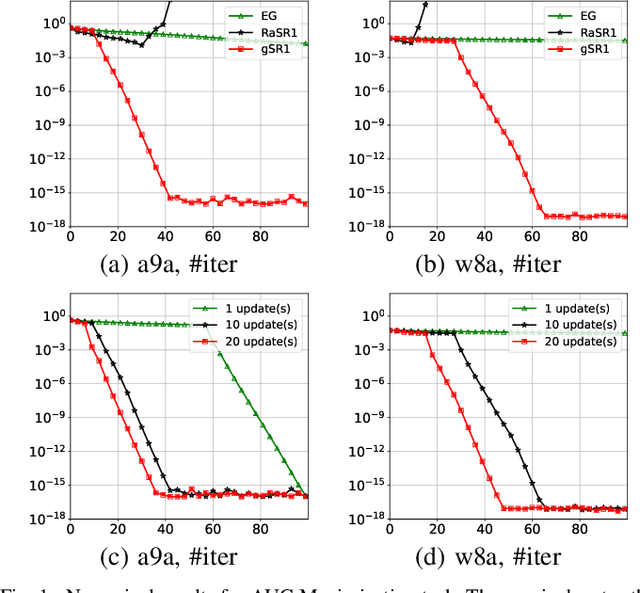
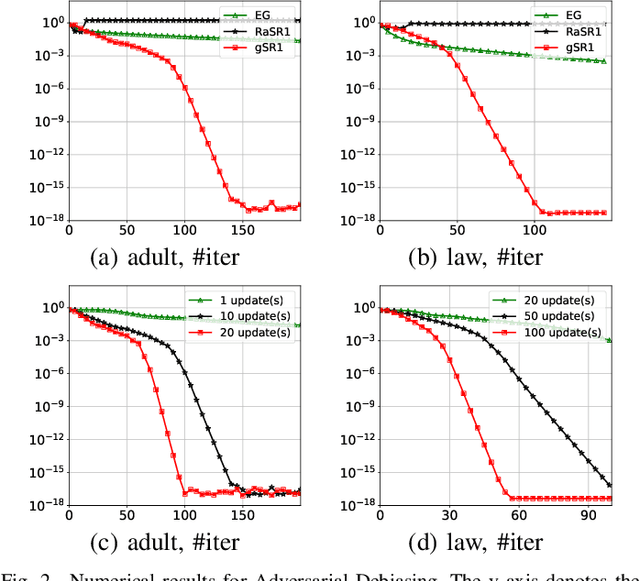
This paper introduces the Multiple Greedy Quasi-Newton (MGSR1-SP) method, a novel approach to solving strongly-convex-strongly-concave (SCSC) saddle point problems. Our method enhances the approximation of the squared indefinite Hessian matrix inherent in these problems, significantly improving both stability and efficiency through iterative greedy updates. We provide a thorough theoretical analysis of MGSR1-SP, demonstrating its linear-quadratic convergence rate. Numerical experiments conducted on AUC maximization and adversarial debiasing problems, compared with state-of-the-art algorithms, underscore our method's enhanced convergence rate. These results affirm the potential of MGSR1-SP to improve performance across a broad spectrum of machine learning applications where efficient and accurate Hessian approximations are crucial.