 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Fraud Detection: Integrating Reinforcement Learning into Graph Neural Networks
Sep 15, 2024
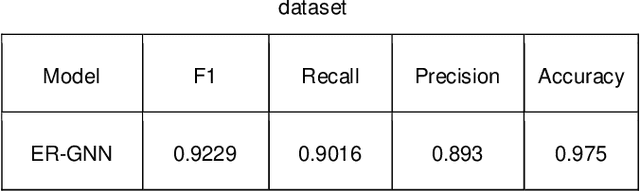
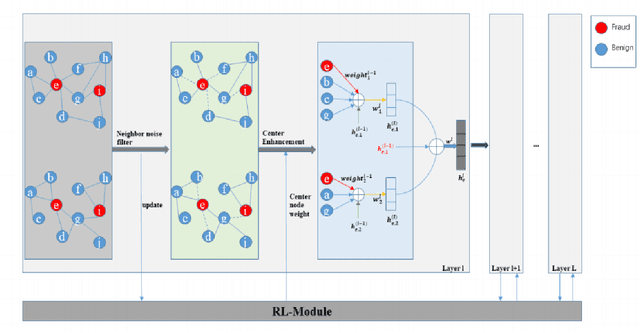
Financial fraud refers to the act of obtaining financial benefits through dishonest means. Such behavior not only disrupts the order of the financial market but also harms economic and social development and breeds other illegal and criminal activities. With the popularization of the internet and online payment methods, many fraudulent activities and money laundering behaviors in life have shifted from offline to online, posing a great challenge to regulatory authorities. How to efficiently detect these financial fraud activities has become an urgent issue that needs to be resolved. Graph neural networks are a type of deep learning model that can utilize the interactive relationships within graph structures, and they have been widely applied in the field of fraud detection. However, there are still some issues. First, fraudulent activities only account for a very small part of transaction transfers, leading to an inevitable problem of label imbalance in fraud detection. At the same time, fraudsters often disguise their behavior, which can have a negative impact on the final prediction results. In addition, existing research has overlooked the importance of balancing neighbor information and central node information. For example, when the central node has too many neighbors, the features of the central node itself are often neglected. Finally, fraud activities and patterns are constantly changing over time, so considering the dynamic evolution of graph edge relationships is also very important.
Electroencephalogram Emotion Recognition via AUC Maximization
Aug 16, 2024



Imbalanced datasets pose significant challenges in areas including neuroscience, cognitive science, and medical diagnostics, where accurately detecting minority classes is essential for robust model performance. This study addresses the issue of class imbalance, using the `Liking' label in the DEAP dataset as an example. Such imbalances are often overlooked by prior research, which typically focuses on the more balanced arousal and valence labels and predominantly uses accuracy metrics to measure model performance. To tackle this issue, we adopt numerical optimization techniques aimed at maximizing the area under the curve (AUC), thus enhancing the detection of underrepresented classes. Our approach, which begins with a linear classifier, is compared against traditional linear classifiers, including logistic regression and support vector machines (SVM). Our method significantly outperforms these models, increasing recall from 41.6\% to 79.7\% and improving the F1-score from 0.506 to 0.632. These results highlight the efficacy of AUC maximization via numerical optimization in managing imbalanced datasets, providing an effective solution for enhancing predictive accuracy in detecting minority but crucial classes in out-of-sample datasets.
Root Cause Attribution of Delivery Risks via Causal Discovery with Reinforcement Learning
Aug 11, 2024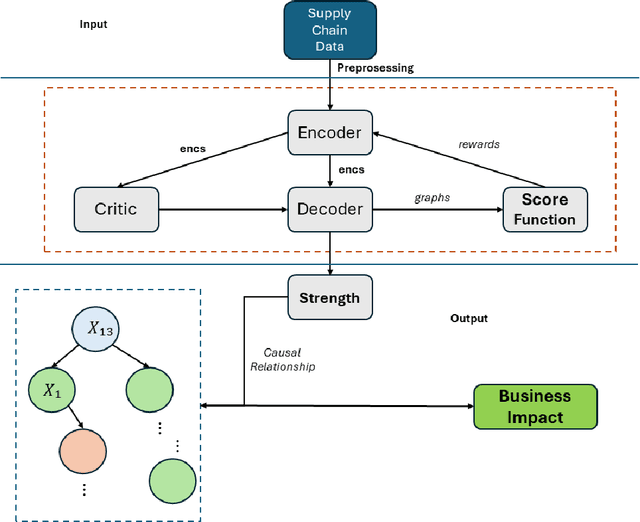
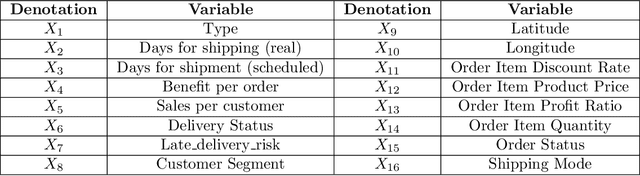


This paper presents a novel approach to root cause attribution of delivery risks within supply chains by integrating causal discovery with reinforcement learning. As supply chains become increasingly complex, traditional methods of root cause analysis struggle to capture the intricate interrelationships between various factors, often leading to spurious correlations and suboptimal decision-making. Our approach addresses these challenges by leveraging causal discovery to identify the true causal relationships between operational variables, and reinforcement learning to iteratively refine the causal graph. This method enables the accurate identification of key drivers of late deliveries, such as shipping mode and delivery status, and provides actionable insights for optimizing supply chain performance. We apply our approach to a real-world supply chain dataset, demonstrating its effectiveness in uncovering the underlying causes of delivery delays and offering strategies for mitigating these risks. The findings have significant implications for improving operational efficiency, customer satisfaction, and overall profitability within supply chains.
Adaptive Friction in Deep Learning: Enhancing Optimizers with Sigmoid and Tanh Function
Aug 07, 2024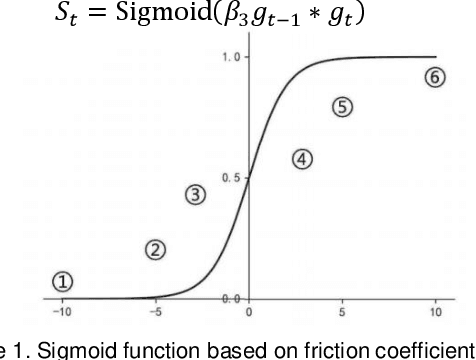
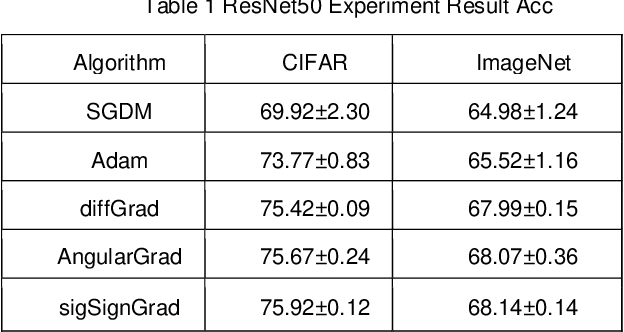

Adaptive optimizers are pivotal in guiding the weight updates of deep neural networks, yet they often face challenges such as poor generalization and oscillation issues. To counter these, we introduce sigSignGrad and tanhSignGrad, two novel optimizers that integrate adaptive friction coefficients based on the Sigmoid and Tanh functions, respectively. These algorithms leverage short-term gradient information, a feature overlooked in traditional Adam variants like diffGrad and AngularGrad, to enhance parameter updates and convergence.Our theoretical analysis demonstrates the wide-ranging adjustment capability of the friction coefficient S, which aligns with targeted parameter update strategies and outperforms existing methods in both optimization trajectory smoothness and convergence rate. Extensive experiments on CIFAR-10, CIFAR-100, and Mini-ImageNet datasets using ResNet50 and ViT architectures confirm the superior performance of our proposed optimizers, showcasing improved accuracy and reduced training time. The innovative approach of integrating adaptive friction coefficients as plug-ins into existing optimizers, exemplified by the sigSignAdamW and sigSignAdamP variants, presents a promising strategy for boosting the optimization performance of established algorithms. The findings of this study contribute to the advancement of optimizer design in deep learning.
Research on Autonomous Driving Decision-making Strategies based Deep Reinforcement Learning
Aug 06, 2024



The behavior decision-making subsystem is a key component of the autonomous driving system, which reflects the decision-making ability of the vehicle and the driver, and is an important symbol of the high-level intelligence of the vehicle. However, the existing rule-based decision-making schemes are limited by the prior knowledge of designers, and it is difficult to cope with complex and changeable traffic scenarios. In this work, an advanced deep reinforcement learning model is adopted, which can autonomously learn and optimize driving strategies in a complex and changeable traffic environment by modeling the driving decision-making process as a reinforcement learning problem. Specifically, we used Deep Q-Network (DQN) and Proximal Policy Optimization (PPO) for comparative experiments. DQN guides the agent to choose the best action by approximating the state-action value function, while PPO improves the decision-making quality by optimizing the policy function. We also introduce improvements in the design of the reward function to promote the robustness and adaptability of the model in real-world driving situations. Experimental results show that the decision-making strategy based on deep reinforcement learning has better performance than the traditional rule-based method in a variety of driving tasks.
Multiple Greedy Quasi-Newton Methods for Saddle Point Problems
Aug 01, 2024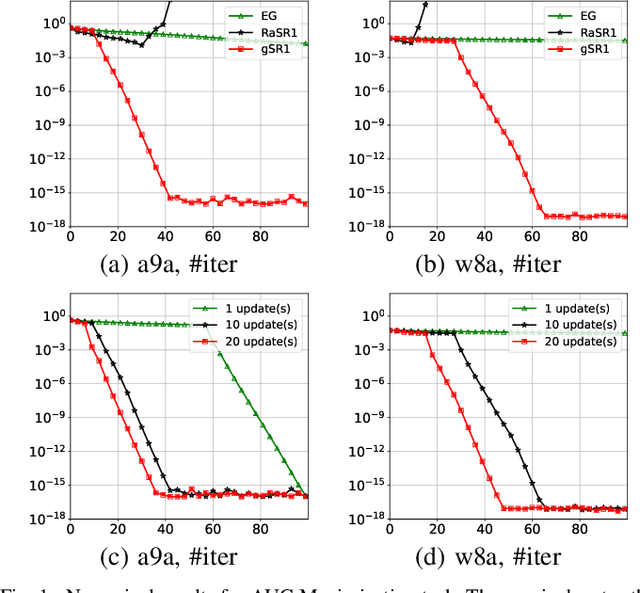
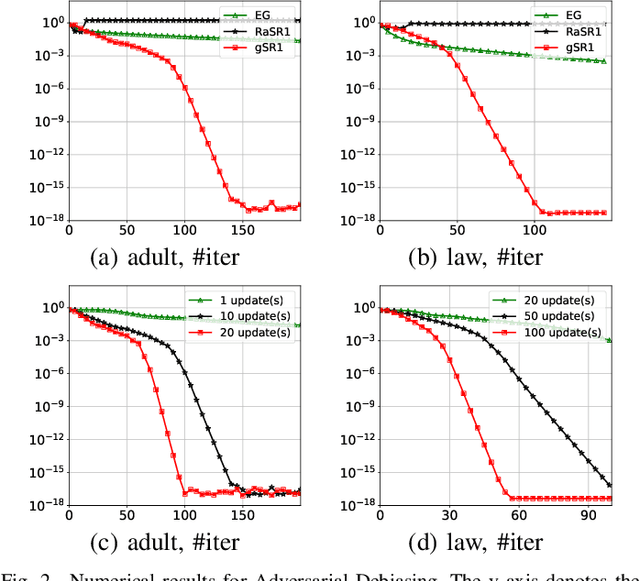
This paper introduces the Multiple Greedy Quasi-Newton (MGSR1-SP) method, a novel approach to solving strongly-convex-strongly-concave (SCSC) saddle point problems. Our method enhances the approximation of the squared indefinite Hessian matrix inherent in these problems, significantly improving both stability and efficiency through iterative greedy updates. We provide a thorough theoretical analysis of MGSR1-SP, demonstrating its linear-quadratic convergence rate. Numerical experiments conducted on AUC maximization and adversarial debiasing problems, compared with state-of-the-art algorithms, underscore our method's enhanced convergence rate. These results affirm the potential of MGSR1-SP to improve performance across a broad spectrum of machine learning applications where efficient and accurate Hessian approximations are crucial.
Policy Gradient Methods for Risk-Sensitive Distributional Reinforcement Learning with Provable Convergence
May 23, 2024



Risk-sensitive reinforcement learning (RL) is crucial for maintaining reliable performance in many high-stakes applications. While most RL methods aim to learn a point estimate of the random cumulative cost, distributional RL (DRL) seeks to estimate the entire distribution of it. The distribution provides all necessary information about the cost and leads to a unified framework for handling various risk measures in a risk-sensitive setting. However, developing policy gradient methods for risk-sensitive DRL is inherently more complex as it pertains to finding the gradient of a probability measure. This paper introduces a policy gradient method for risk-sensitive DRL with general coherent risk measures, where we provide an analytical form of the probability measure's gradient. We further prove the local convergence of the proposed algorithm under mild smoothness assumptions. For practical use, we also design a categorical distributional policy gradient algorithm (CDPG) based on categorical distributional policy evaluation and trajectory-based gradient estimation. Through experiments on a stochastic cliff-walking environment, we illustrate the benefits of considering a risk-sensitive setting in DRL.