 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMAE: A Massive Multitask Audio Editing Benchmark
Jun 05, 2026We introduce MMAE, a Massive Multitask Audio Editing benchmark, serving as the first comprehensive evaluation testbed designed for general-purpose instruction-based audio editing. Spurred by the shift toward intelligent creation, interactive editing has rapidly expanded from visual domains, pioneered by models like Nano-banana 2 for images and Gemini-Omni for video, into audio. However, the current evaluation infrastructure lags severely, remaining highly fragmented and restricted to specific subdomains or basic operations. Unlike existing benchmarks that are limited in scope, MMAE extends to a broad spectrum of real-world scenarios, encompassing 7 distinct audio modalities, including sound, speech, music, and their mixtures. Furthermore, we establish a comprehensive taxonomy spanning 6 levels of task complexity, from basic modifications to multi-hop reasoning and multi-round editing, 2 levels of granularity, and 8 distinct operation types. Meticulously curated through human-agent collaboration, MMAE comprises 2,000 high-fidelity samples paired with a pioneering rubric-based evaluation framework. By decomposing free-form tasks into 17,741 verifiable criteria, this robust rubric-based paradigm enables a precise, multi-dimensional assessment of both instruction following and context consistency. Our extensive evaluation of leading models reveals that current systems remain far from achieving reliable edits. Strikingly, the Exact Match Rate (EMR) consistently falls below 5% and plummets to an absolute 0% in complex, mixed-modality tasks, exposing critical bottlenecks in precise execution and structural robustness. We hope MMAE will serve as a catalyst for future advances in the intelligent creation community, providing a clear diagnostic roadmap and establishing a standardized, long-lasting evaluation paradigm for next-generation audio editing systems.
Multi-Agent Systems: From Classical Paradigms to Large Foundation Model-Enabled Futures
Apr 20, 2026With the rapid advancement of artificial intelligence, multi-agent systems (MASs) are evolving from classical paradigms toward architectures built upon large foundation models (LFMs). This survey provides a systematic review and comparative analysis of classical MASs (CMASs) and LFM-based MASs (LMASs). First, within a closed-loop coordination framework, CMASs are reviewed across four fundamental dimensions: perception, communication, decision-making, and control. Beyond this framework, LMASs integrate LFMs to lift collaboration from low-level state exchanges to semantic-level reasoning, enabling more flexible coordination and improved adaptability across diverse scenarios. Then, a comparative analysis is conducted to contrast CMASs and LMASs across architecture, operating mechanism, adaptability, and application. Finally, future perspectives on MASs are presented, summarizing open challenges and potential research opportunities.
The Evolution of Tool Use in LLM Agents: From Single-Tool Call to Multi-Tool Orchestration
Mar 24, 2026Tool use enables large language models (LLMs) to access external information, invoke software systems, and act in digital environments beyond what can be solved from model parameters alone. Early research mainly studied whether a model could select and execute a correct single tool call. As agent systems evolve, however, the central problem has shifted from isolated invocation to multi-tool orchestration over long trajectories with intermediate state, execution feedback, changing environments, and practical constraints such as safety, cost, and verifiability. We comprehensively review recent progress in multi-tool LLM agents and analyzes the state of the art in this rapidly developing area. First, we unify task formulations and distinguish single-call tool use from long-horizon orchestration. Then, we organize the literature around six core dimensions: inference-time planning and execution, training and trajectory construction, safety and control, efficiency under resource constraints, capability completeness in open environments, and benchmark design and evaluation. We further summarize representative applications in software engineering, enterprise workflows, graphical user interfaces, and mobile systems. Finally, we discuss major challenges and outline future directions for building reliable, scalable, and verifiable multi-tool agents.
Augmenting Clinical Decision-Making with an Interactive and Interpretable AI Copilot: A Real-World User Study with Clinicians in Nephrology and Obstetrics
Jan 31, 2026Clinician skepticism toward opaque AI hinders adoption in high-stakes healthcare. We present AICare, an interactive and interpretable AI copilot for collaborative clinical decision-making. By analyzing longitudinal electronic health records, AICare grounds dynamic risk predictions in scrutable visualizations and LLM-driven diagnostic recommendations. Through a within-subjects counterbalanced study with 16 clinicians across nephrology and obstetrics, we comprehensively evaluated AICare using objective measures (task completion time and error rate), subjective assessments (NASA-TLX, SUS, and confidence ratings), and semi-structured interviews. Our findings indicate AICare's reduced cognitive workload. Beyond performance metrics, qualitative analysis reveals that trust is actively constructed through verification, with interaction strategies diverging by expertise: junior clinicians used the system as cognitive scaffolding to structure their analysis, while experts engaged in adversarial verification to challenge the AI's logic. This work offers design implications for creating AI systems that function as transparent partners, accommodating diverse reasoning styles to augment rather than replace clinical judgment.
ConfAgents: A Conformal-Guided Multi-Agent Framework for Cost-Efficient Medical Diagnosis
Aug 06, 2025



The efficacy of AI agents in healthcare research is hindered by their reliance on static, predefined strategies. This creates a critical limitation: agents can become better tool-users but cannot learn to become better strategic planners, a crucial skill for complex domains like healthcare. We introduce HealthFlow, a self-evolving AI agent that overcomes this limitation through a novel meta-level evolution mechanism. HealthFlow autonomously refines its own high-level problem-solving policies by distilling procedural successes and failures into a durable, strategic knowledge base. To anchor our research and facilitate reproducible evaluation, we introduce EHRFlowBench, a new benchmark featuring complex, realistic health data analysis tasks derived from peer-reviewed clinical research. Our comprehensive experiments demonstrate that HealthFlow's self-evolving approach significantly outperforms state-of-the-art agent frameworks. This work marks a necessary shift from building better tool-users to designing smarter, self-evolving task-managers, paving the way for more autonomous and effective AI for scientific discovery.
MedAgentBoard: Benchmarking Multi-Agent Collaboration with Conventional Methods for Diverse Medical Tasks
May 18, 2025The rapid advancement of Large Language Models (LLMs) has stimulated interest in multi-agent collaboration for addressing complex medical tasks. However, the practical advantages of multi-agent collaboration approaches remain insufficiently understood. Existing evaluations often lack generalizability, failing to cover diverse tasks reflective of real-world clinical practice, and frequently omit rigorous comparisons against both single-LLM-based and established conventional methods. To address this critical gap, we introduce MedAgentBoard, a comprehensive benchmark for the systematic evaluation of multi-agent collaboration, single-LLM, and conventional approaches. MedAgentBoard encompasses four diverse medical task categories: (1) medical (visual) question answering, (2) lay summary generation, (3) structured Electronic Health Record (EHR) predictive modeling, and (4) clinical workflow automation, across text, medical images, and structured EHR data. Our extensive experiments reveal a nuanced landscape: while multi-agent collaboration demonstrates benefits in specific scenarios, such as enhancing task completeness in clinical workflow automation, it does not consistently outperform advanced single LLMs (e.g., in textual medical QA) or, critically, specialized conventional methods that generally maintain better performance in tasks like medical VQA and EHR-based prediction. MedAgentBoard offers a vital resource and actionable insights, emphasizing the necessity of a task-specific, evidence-based approach to selecting and developing AI solutions in medicine. It underscores that the inherent complexity and overhead of multi-agent collaboration must be carefully weighed against tangible performance gains. All code, datasets, detailed prompts, and experimental results are open-sourced at https://medagentboard.netlify.app/.
ColaCare: Enhancing Electronic Health Record Modeling through Large Language Model-Driven Multi-Agent Collaboration
Oct 03, 2024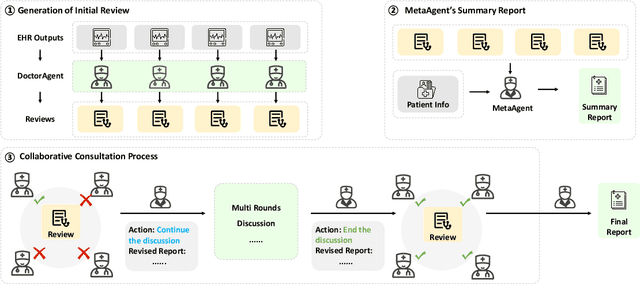
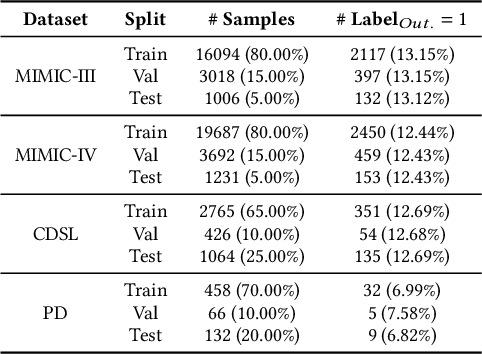
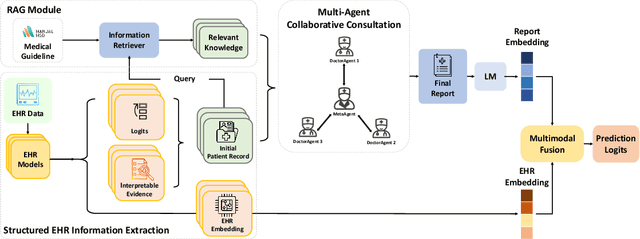

We introduce ColaCare, a framework that enhances Electronic Health Record (EHR) modeling through multi-agent collaboration driven by Large Language Models (LLMs). Our approach seamlessly integrates domain-specific expert models with LLMs to bridge the gap between structured EHR data and text-based reasoning. Inspired by clinical consultations, ColaCare employs two types of agents: DoctorAgent and MetaAgent, which collaboratively analyze patient data. Expert models process and generate predictions from numerical EHR data, while LLM agents produce reasoning references and decision-making reports within the collaborative consultation framework. We additionally incorporate the Merck Manual of Diagnosis and Therapy (MSD) medical guideline within a retrieval-augmented generation (RAG) module for authoritative evidence support. Extensive experiments conducted on four distinct EHR datasets demonstrate ColaCare's superior performance in mortality prediction tasks, underscoring its potential to revolutionize clinical decision support systems and advance personalized precision medicine. The code, complete prompt templates, more case studies, etc. are publicly available at the anonymous link: https://colacare.netlify.app.
Research on Autonomous Driving Decision-making Strategies based Deep Reinforcement Learning
Aug 06, 2024



The behavior decision-making subsystem is a key component of the autonomous driving system, which reflects the decision-making ability of the vehicle and the driver, and is an important symbol of the high-level intelligence of the vehicle. However, the existing rule-based decision-making schemes are limited by the prior knowledge of designers, and it is difficult to cope with complex and changeable traffic scenarios. In this work, an advanced deep reinforcement learning model is adopted, which can autonomously learn and optimize driving strategies in a complex and changeable traffic environment by modeling the driving decision-making process as a reinforcement learning problem. Specifically, we used Deep Q-Network (DQN) and Proximal Policy Optimization (PPO) for comparative experiments. DQN guides the agent to choose the best action by approximating the state-action value function, while PPO improves the decision-making quality by optimizing the policy function. We also introduce improvements in the design of the reward function to promote the robustness and adaptability of the model in real-world driving situations. Experimental results show that the decision-making strategy based on deep reinforcement learning has better performance than the traditional rule-based method in a variety of driving tasks.
Is larger always better? Evaluating and prompting large language models for non-generative medical tasks
Jul 26, 2024The use of Large Language Models (LLMs) in medicine is growing, but their ability to handle both structured Electronic Health Record (EHR) data and unstructured clinical notes is not well-studied. This study benchmarks various models, including GPT-based LLMs, BERT-based models, and traditional clinical predictive models, for non-generative medical tasks utilizing renowned datasets. We assessed 14 language models (9 GPT-based and 5 BERT-based) and 7 traditional predictive models using the MIMIC dataset (ICU patient records) and the TJH dataset (early COVID-19 EHR data), focusing on tasks such as mortality and readmission prediction, disease hierarchy reconstruction, and biomedical sentence matching, comparing both zero-shot and finetuned performance. Results indicated that LLMs exhibited robust zero-shot predictive capabilities on structured EHR data when using well-designed prompting strategies, frequently surpassing traditional models. However, for unstructured medical texts, LLMs did not outperform finetuned BERT models, which excelled in both supervised and unsupervised tasks. Consequently, while LLMs are effective for zero-shot learning on structured data, finetuned BERT models are more suitable for unstructured texts, underscoring the importance of selecting models based on specific task requirements and data characteristics to optimize the application of NLP technology in healthcare.
Research on Image Super-Resolution Reconstruction Mechanism based on Convolutional Neural Network
Jul 18, 2024



Super-resolution reconstruction techniques entail the utilization of software algorithms to transform one or more sets of low-resolution images captured from the same scene into high-resolution images. In recent years, considerable advancement has been observed in the domain of single-image super-resolution algorithms, particularly those based on deep learning techniques. Nevertheless, the extraction of image features and nonlinear mapping methods in the reconstruction process remain challenging for existing algorithms. These issues result in the network architecture being unable to effectively utilize the diverse range of information at different levels. The loss of high-frequency details is significant, and the final reconstructed image features are overly smooth, with a lack of fine texture details. This negatively impacts the subjective visual quality of the image. The objective is to recover high-quality, high-resolution images from low-resolution images. In this work, an enhanced deep convolutional neural network model is employed, comprising multiple convolutional layers, each of which is configured with specific filters and activation functions to effectively capture the diverse features of the image. Furthermore, a residual learning strategy is employed to accelerate training and enhance the convergence of the network, while sub-pixel convolutional layers are utilized to refine the high-frequency details and textures of the image. The experimental analysis demonstrates the superior performance of the proposed model on multiple public datasets when compared with the traditional bicubic interpolation method and several other learning-based super-resolution methods. Furthermore, it proves the model's efficacy in maintaining image edges and textures.