 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearchGym: Bootstrapping Real-World Search Agents via Cost-Effective and High-Fidelity Environment Simulation
Jan 21, 2026Search agents have emerged as a pivotal paradigm for solving open-ended, knowledge-intensive reasoning tasks. However, training these agents via Reinforcement Learning (RL) faces a critical dilemma: interacting with live commercial Web APIs is prohibitively expensive, while relying on static data snapshots often introduces noise due to data misalignment. This misalignment generates corrupted reward signals that destabilize training by penalizing correct reasoning or rewarding hallucination. To address this, we propose SearchGym, a simulation environment designed to bootstrap robust search agents. SearchGym employs a rigorous generative pipeline to construct a verifiable knowledge graph and an aligned document corpus, ensuring that every reasoning task is factually grounded and strictly solvable. Building on this controllable environment, we introduce SearchGym-RL, a curriculum learning methodology that progressively optimizes agent policies through purified feedback, evolving from basic interactions to complex, long-horizon planning. Extensive experiments across the Llama and Qwen families demonstrate strong Sim-to-Real generalization. Notably, our Qwen2.5-7B-Base model trained within SearchGym surpasses the web-enhanced ASearcher baseline across nine diverse benchmarks by an average relative margin of 10.6%. Our results validate that high-fidelity simulation serves as a scalable and highly cost-effective methodology for developing capable search agents.
Scaf-GRPO: Scaffolded Group Relative Policy Optimization for Enhancing LLM Reasoning
Oct 22, 2025Reinforcement learning from verifiable rewards has emerged as a powerful technique for enhancing the complex reasoning abilities of Large Language Models (LLMs). However, these methods are fundamentally constrained by the ''learning cliff'' phenomenon: when faced with problems far beyond their current capabilities, models consistently fail, yielding a persistent zero-reward signal. In policy optimization algorithms like GRPO, this collapses the advantage calculation to zero, rendering these difficult problems invisible to the learning gradient and stalling progress. To overcome this, we introduce Scaf-GRPO (Scaffolded Group Relative Policy Optimization), a progressive training framework that strategically provides minimal guidance only when a model's independent learning has plateaued. The framework first diagnoses learning stagnation and then intervenes by injecting tiered in-prompt hints, ranging from abstract concepts to concrete steps, enabling the model to construct a valid solution by itself. Extensive experiments on challenging mathematics benchmarks demonstrate Scaf-GRPO's effectiveness, boosting the pass@1 score of the Qwen2.5-Math-7B model on the AIME24 benchmark by a relative 44.3% over a vanilla GRPO baseline. This result demonstrates our framework provides a robust and effective methodology for unlocking a model's ability to solve problems previously beyond its reach, a critical step towards extending the frontier of autonomous reasoning in LLM.
MedAgentBoard: Benchmarking Multi-Agent Collaboration with Conventional Methods for Diverse Medical Tasks
May 18, 2025The rapid advancement of Large Language Models (LLMs) has stimulated interest in multi-agent collaboration for addressing complex medical tasks. However, the practical advantages of multi-agent collaboration approaches remain insufficiently understood. Existing evaluations often lack generalizability, failing to cover diverse tasks reflective of real-world clinical practice, and frequently omit rigorous comparisons against both single-LLM-based and established conventional methods. To address this critical gap, we introduce MedAgentBoard, a comprehensive benchmark for the systematic evaluation of multi-agent collaboration, single-LLM, and conventional approaches. MedAgentBoard encompasses four diverse medical task categories: (1) medical (visual) question answering, (2) lay summary generation, (3) structured Electronic Health Record (EHR) predictive modeling, and (4) clinical workflow automation, across text, medical images, and structured EHR data. Our extensive experiments reveal a nuanced landscape: while multi-agent collaboration demonstrates benefits in specific scenarios, such as enhancing task completeness in clinical workflow automation, it does not consistently outperform advanced single LLMs (e.g., in textual medical QA) or, critically, specialized conventional methods that generally maintain better performance in tasks like medical VQA and EHR-based prediction. MedAgentBoard offers a vital resource and actionable insights, emphasizing the necessity of a task-specific, evidence-based approach to selecting and developing AI solutions in medicine. It underscores that the inherent complexity and overhead of multi-agent collaboration must be carefully weighed against tangible performance gains. All code, datasets, detailed prompts, and experimental results are open-sourced at https://medagentboard.netlify.app/.
U2AD: Uncertainty-based Unsupervised Anomaly Detection Framework for Detecting T2 Hyperintensity in MRI Spinal Cord
Mar 17, 2025T2 hyperintensities in spinal cord MR images are crucial biomarkers for conditions such as degenerative cervical myelopathy. However, current clinical diagnoses primarily rely on manual evaluation. Deep learning methods have shown promise in lesion detection, but most supervised approaches are heavily dependent on large, annotated datasets. Unsupervised anomaly detection (UAD) offers a compelling alternative by eliminating the need for abnormal data annotations. However, existing UAD methods rely on curated normal datasets and their performance frequently deteriorates when applied to clinical datasets due to domain shifts. We propose an Uncertainty-based Unsupervised Anomaly Detection framework, termed U2AD, to address these limitations. Unlike traditional methods, U2AD is designed to be trained and tested within the same clinical dataset, following a "mask-and-reconstruction" paradigm built on a Vision Transformer-based architecture. We introduce an uncertainty-guided masking strategy to resolve task conflicts between normal reconstruction and anomaly detection to achieve an optimal balance. Specifically, we employ a Monte-Carlo sampling technique to estimate reconstruction uncertainty mappings during training. By iteratively optimizing reconstruction training under the guidance of both epistemic and aleatoric uncertainty, U2AD reduces overall reconstruction variance while emphasizing regions. Experimental results demonstrate that U2AD outperforms existing supervised and unsupervised methods in patient-level identification and segment-level localization tasks. This framework establishes a new benchmark for incorporating uncertainty guidance into UAD, highlighting its clinical utility in addressing domain shifts and task conflicts in medical image anomaly detection. Our code is available: https://github.com/zhibaishouheilab/U2AD
Pathology-Guided AI System for Accurate Segmentation and Diagnosis of Cervical Spondylosis
Mar 08, 2025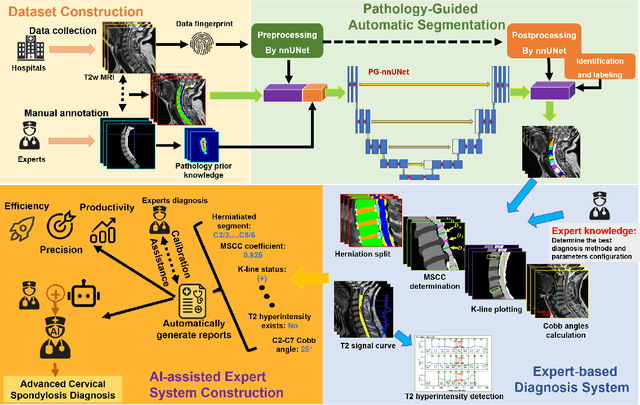
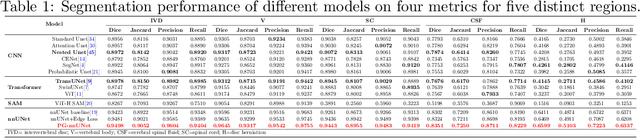
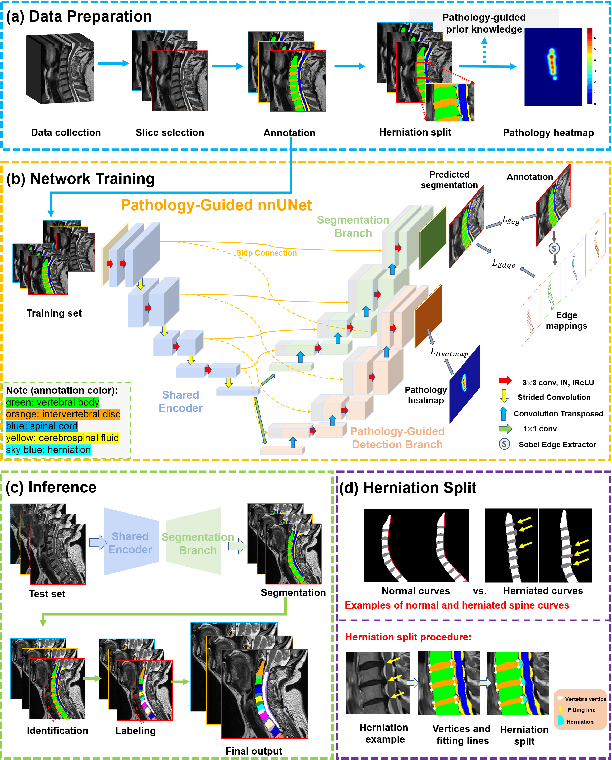
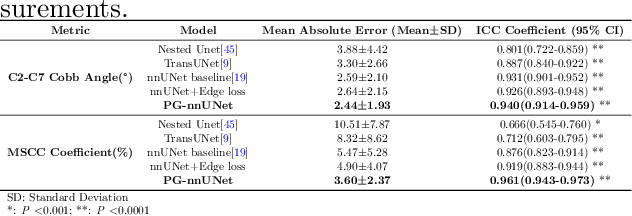
Cervical spondylosis, a complex and prevalent condition, demands precise and efficient diagnostic techniques for accurate assessment. While MRI offers detailed visualization of cervical spine anatomy, manual interpretation remains labor-intensive and prone to error. To address this, we developed an innovative AI-assisted Expert-based Diagnosis System that automates both segmentation and diagnosis of cervical spondylosis using MRI. Leveraging a dataset of 960 cervical MRI images from patients with cervical disc herniation, our system features a pathology-guided segmentation model capable of accurately segmenting key cervical anatomical structures. The segmentation is followed by an expert-based diagnostic framework that automates the calculation of critical clinical indicators. Our segmentation model achieved an impressive average Dice coefficient exceeding 0.90 across four cervical spinal anatomies and demonstrated enhanced accuracy in herniation areas. Diagnostic evaluation further showcased the system precision, with a mean absolute error (MAE) of 2.44 degree for the C2-C7 Cobb angle and 3.60 precentage for the Maximum Spinal Cord Compression (MSCC) coefficient. In addition, our method delivered high accuracy, precision, recall, and F1 scores in herniation localization, K-line status assessment, and T2 hyperintensity detection. Comparative analysis demonstrates that our system outperforms existing methods, establishing a new benchmark for segmentation and diagnostic tasks for cervical spondylosis.
SETGen: Scalable and Efficient Template Generation Framework for Groupwise Medical Image Registration
Nov 10, 2022



Template generation is a crucial step of groupwise image registration which deforms a group of subjects into a common space. Existing traditional and deep learning-based methods can generate high-quality template images. However, they suffer from substantial time costs or limited application scenarios like fixed group size. In this paper, we propose an efficient groupwise template generative framework based on variational autoencoder models utilizing the arithmetic property of latent representation of input images. We acquire the latent vectors of each input and use the average vector to construct the template through the decoder. Therefore, the method can be applied to groups of any scale. Secondly, we explore a siamese training scheme that feeds two images to the shared-weight twin networks and compares the distances between inputs and the generated template to prompt the template to be close to the implicit center. We conduct experiments on 3D brain MRI scans of groups of different sizes. Results show that our framework can achieve comparable and even better performance to baselines, with runtime decreased to seconds.