 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearchGym: Bootstrapping Real-World Search Agents via Cost-Effective and High-Fidelity Environment Simulation
Jan 21, 2026Search agents have emerged as a pivotal paradigm for solving open-ended, knowledge-intensive reasoning tasks. However, training these agents via Reinforcement Learning (RL) faces a critical dilemma: interacting with live commercial Web APIs is prohibitively expensive, while relying on static data snapshots often introduces noise due to data misalignment. This misalignment generates corrupted reward signals that destabilize training by penalizing correct reasoning or rewarding hallucination. To address this, we propose SearchGym, a simulation environment designed to bootstrap robust search agents. SearchGym employs a rigorous generative pipeline to construct a verifiable knowledge graph and an aligned document corpus, ensuring that every reasoning task is factually grounded and strictly solvable. Building on this controllable environment, we introduce SearchGym-RL, a curriculum learning methodology that progressively optimizes agent policies through purified feedback, evolving from basic interactions to complex, long-horizon planning. Extensive experiments across the Llama and Qwen families demonstrate strong Sim-to-Real generalization. Notably, our Qwen2.5-7B-Base model trained within SearchGym surpasses the web-enhanced ASearcher baseline across nine diverse benchmarks by an average relative margin of 10.6%. Our results validate that high-fidelity simulation serves as a scalable and highly cost-effective methodology for developing capable search agents.
Repulsor: Accelerating Generative Modeling with a Contrastive Memory Bank
Dec 13, 2025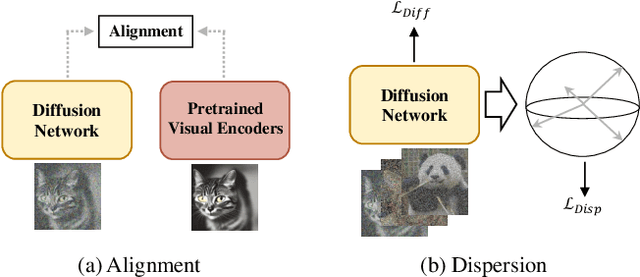
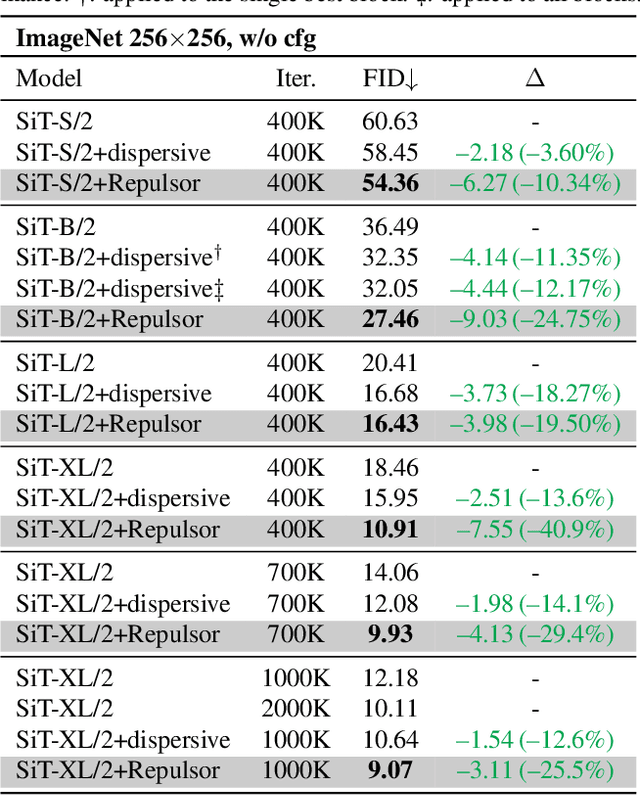
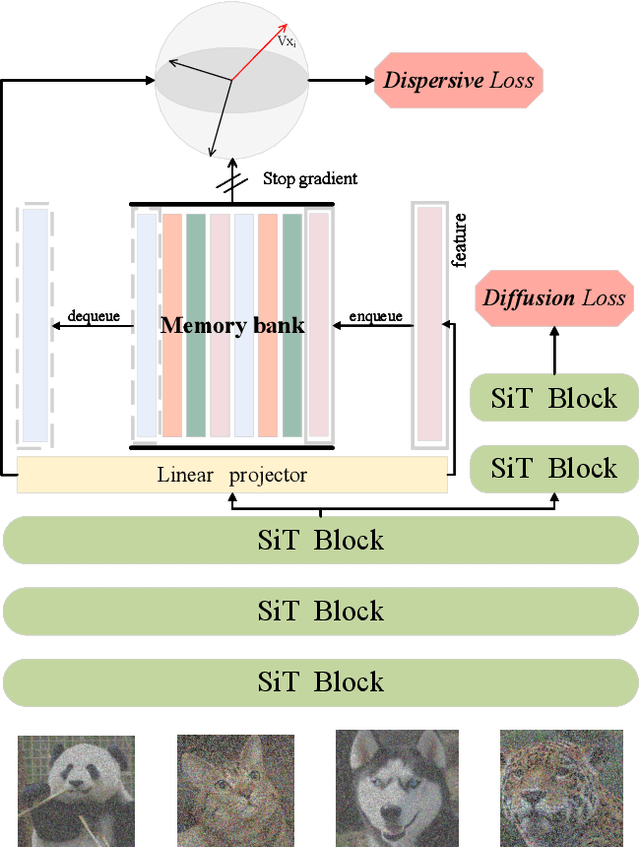

The dominance of denoising generative models (e.g., diffusion, flow-matching) in visual synthesis is tempered by their substantial training costs and inefficiencies in representation learning. While injecting discriminative representations via auxiliary alignment has proven effective, this approach still faces key limitations: the reliance on external, pre-trained encoders introduces overhead and domain shift. A dispersed-based strategy that encourages strong separation among in-batch latent representations alleviates this specific dependency. To assess the effect of the number of negative samples in generative modeling, we propose {\mname}, a plug-and-play training framework that requires no external encoders. Our method integrates a memory bank mechanism that maintains a large, dynamically updated queue of negative samples across training iterations. This decouples the number of negatives from the mini-batch size, providing abundant and high-quality negatives for a contrastive objective without a multiplicative increase in computational cost. A low-dimensional projection head is used to further minimize memory and bandwidth overhead. {\mname} offers three principal advantages: (1) it is self-contained, eliminating dependency on pretrained vision foundation models and their associated forward-pass overhead; (2) it introduces no additional parameters or computational cost during inference; and (3) it enables substantially faster convergence, achieving superior generative quality more efficiently. On ImageNet-256, {\mname} achieves a state-of-the-art FID of \textbf{2.40} within 400k steps, significantly outperforming comparable methods.
Scaf-GRPO: Scaffolded Group Relative Policy Optimization for Enhancing LLM Reasoning
Oct 22, 2025Reinforcement learning from verifiable rewards has emerged as a powerful technique for enhancing the complex reasoning abilities of Large Language Models (LLMs). However, these methods are fundamentally constrained by the ''learning cliff'' phenomenon: when faced with problems far beyond their current capabilities, models consistently fail, yielding a persistent zero-reward signal. In policy optimization algorithms like GRPO, this collapses the advantage calculation to zero, rendering these difficult problems invisible to the learning gradient and stalling progress. To overcome this, we introduce Scaf-GRPO (Scaffolded Group Relative Policy Optimization), a progressive training framework that strategically provides minimal guidance only when a model's independent learning has plateaued. The framework first diagnoses learning stagnation and then intervenes by injecting tiered in-prompt hints, ranging from abstract concepts to concrete steps, enabling the model to construct a valid solution by itself. Extensive experiments on challenging mathematics benchmarks demonstrate Scaf-GRPO's effectiveness, boosting the pass@1 score of the Qwen2.5-Math-7B model on the AIME24 benchmark by a relative 44.3% over a vanilla GRPO baseline. This result demonstrates our framework provides a robust and effective methodology for unlocking a model's ability to solve problems previously beyond its reach, a critical step towards extending the frontier of autonomous reasoning in LLM.
Understanding Data Influence with Differential Approximation
Aug 20, 2025Data plays a pivotal role in the groundbreaking advancements in artificial intelligence. The quantitative analysis of data significantly contributes to model training, enhancing both the efficiency and quality of data utilization. However, existing data analysis tools often lag in accuracy. For instance, many of these tools even assume that the loss function of neural networks is convex. These limitations make it challenging to implement current methods effectively. In this paper, we introduce a new formulation to approximate a sample's influence by accumulating the differences in influence between consecutive learning steps, which we term Diff-In. Specifically, we formulate the sample-wise influence as the cumulative sum of its changes/differences across successive training iterations. By employing second-order approximations, we approximate these difference terms with high accuracy while eliminating the need for model convexity required by existing methods. Despite being a second-order method, Diff-In maintains computational complexity comparable to that of first-order methods and remains scalable. This efficiency is achieved by computing the product of the Hessian and gradient, which can be efficiently approximated using finite differences of first-order gradients. We assess the approximation accuracy of Diff-In both theoretically and empirically. Our theoretical analysis demonstrates that Diff-In achieves significantly lower approximation error compared to existing influence estimators. Extensive experiments further confirm its superior performance across multiple benchmark datasets in three data-centric tasks: data cleaning, data deletion, and coreset selection. Notably, our experiments on data pruning for large-scale vision-language pre-training show that Diff-In can scale to millions of data points and outperforms strong baselines.
MC-MoE: Mixture Compressor for Mixture-of-Experts LLMs Gains More
Oct 08, 2024



Mixture-of-Experts large language models (MoE-LLMs) marks a significant step forward of language models, however, they encounter two critical challenges in practice: 1) expert parameters lead to considerable memory consumption and loading latency; and 2) the current activated experts are redundant, as many tokens may only require a single expert. Motivated by these issues, we investigate the MoE-LLMs and make two key observations: a) different experts exhibit varying behaviors on activation reconstruction error, routing scores, and activated frequencies, highlighting their differing importance, and b) not all tokens are equally important -- only a small subset is critical. Building on these insights, we propose MC-MoE, a training-free Mixture-Compressor for MoE-LLMs, which leverages the significance of both experts and tokens to achieve an extreme compression. First, to mitigate storage and loading overheads, we introduce Pre-Loading Mixed-Precision Quantization, which formulates the adaptive bit-width allocation as a Linear Programming problem, where the objective function balances multi-factors reflecting the importance of each expert. Additionally, we develop Online Dynamic Pruning, which identifies important tokens to retain and dynamically select activated experts for other tokens during inference to optimize efficiency while maintaining performance. Our MC-MoE integrates static quantization and dynamic pruning to collaboratively achieve extreme compression for MoE-LLMs with less accuracy loss, ensuring an optimal trade-off between performance and efficiency. Extensive experiments confirm the effectiveness of our approach. For instance, at 2.54 bits, MC-MoE compresses 76.6% of the model, with only a 3.8% average accuracy loss. During dynamic inference, we further reduce activated parameters by 15%, with a performance drop of less than 0.6%.
Differentiable Proximal Graph Matching
May 26, 2024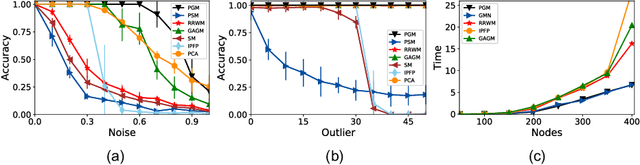

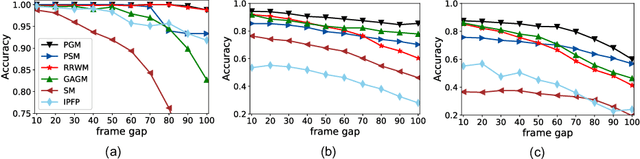
Graph matching is a fundamental tool in computer vision and pattern recognition. In this paper, we introduce an algorithm for graph matching based on the proximal operator, referred to as differentiable proximal graph matching (DPGM). Specifically, we relax and decompose the quadratic assignment problem for the graph matching into a sequence of convex optimization problems. The whole algorithm can be considered as a differentiable map from the graph affinity matrix to the prediction of node correspondence. Therefore, the proposed method can be organically integrated into an end-to-end deep learning framework to jointly learn both the deep feature representation and the graph affinity matrix. In addition, we provide a theoretical guarantee to ensure the proposed method converges to a stable point with a reasonable number of iterations. Numerical experiments show that PGM outperforms existing graph matching algorithms on diverse datasets such as synthetic data, and CMU House. Meanwhile, PGM can fully harness the capability of deep feature extractors and achieve state-of-art performance on PASCAL VOC keypoints.
Ensemble Quadratic Assignment Network for Graph Matching
Mar 11, 2024Graph matching is a commonly used technique in computer vision and pattern recognition. Recent data-driven approaches have improved the graph matching accuracy remarkably, whereas some traditional algorithm-based methods are more robust to feature noises, outlier nodes, and global transformation (e.g.~rotation). In this paper, we propose a graph neural network (GNN) based approach to combine the advantages of data-driven and traditional methods. In the GNN framework, we transform traditional graph-matching solvers as single-channel GNNs on the association graph and extend the single-channel architecture to the multi-channel network. The proposed model can be seen as an ensemble method that fuses multiple algorithms at every iteration. Instead of averaging the estimates at the end of the ensemble, in our approach, the independent iterations of the ensembled algorithms exchange their information after each iteration via a 1x1 channel-wise convolution layer. Experiments show that our model improves the performance of traditional algorithms significantly. In addition, we propose a random sampling strategy to reduce the computational complexity and GPU memory usage, so the model applies to matching graphs with thousands of nodes. We evaluate the performance of our method on three tasks: geometric graph matching, semantic feature matching, and few-shot 3D shape classification. The proposed model performs comparably or outperforms the best existing GNN-based methods.
Debiasing Text-to-Image Diffusion Models
Feb 22, 2024Learning-based Text-to-Image (TTI) models like Stable Diffusion have revolutionized the way visual content is generated in various domains. However, recent research has shown that nonnegligible social bias exists in current state-of-the-art TTI systems, which raises important concerns. In this work, we target resolving the social bias in TTI diffusion models. We begin by formalizing the problem setting and use the text descriptions of bias groups to establish an unsafe direction for guiding the diffusion process. Next, we simplify the problem into a weight optimization problem and attempt a Reinforcement solver, Policy Gradient, which shows sub-optimal performance with slow convergence. Further, to overcome limitations, we propose an iterative distribution alignment (IDA) method. Despite its simplicity, we show that IDA shows efficiency and fast convergence in resolving the social bias in TTI diffusion models. Our code will be released.
Data Pruning via Moving-one-Sample-out
Oct 25, 2023In this paper, we propose a novel data-pruning approach called moving-one-sample-out (MoSo), which aims to identify and remove the least informative samples from the training set. The core insight behind MoSo is to determine the importance of each sample by assessing its impact on the optimal empirical risk. This is achieved by measuring the extent to which the empirical risk changes when a particular sample is excluded from the training set. Instead of using the computationally expensive leaving-one-out-retraining procedure, we propose an efficient first-order approximator that only requires gradient information from different training stages. The key idea behind our approximation is that samples with gradients that are consistently aligned with the average gradient of the training set are more informative and should receive higher scores, which could be intuitively understood as follows: if the gradient from a specific sample is consistent with the average gradient vector, it implies that optimizing the network using the sample will yield a similar effect on all remaining samples. Experimental results demonstrate that MoSo effectively mitigates severe performance degradation at high pruning ratios and achieves satisfactory performance across various settings.
Semantic Diffusion Network for Semantic Segmentation
Feb 04, 2023Precise and accurate predictions over boundary areas are essential for semantic segmentation. However, the commonly-used convolutional operators tend to smooth and blur local detail cues, making it difficult for deep models to generate accurate boundary predictions. In this paper, we introduce an operator-level approach to enhance semantic boundary awareness, so as to improve the prediction of the deep semantic segmentation model. Specifically, we first formulate the boundary feature enhancement as an anisotropic diffusion process. We then propose a novel learnable approach called semantic diffusion network (SDN) to approximate the diffusion process, which contains a parameterized semantic difference convolution operator followed by a feature fusion module. Our SDN aims to construct a differentiable mapping from the original feature to the inter-class boundary-enhanced feature. The proposed SDN is an efficient and flexible module that can be easily plugged into existing encoder-decoder segmentation models. Extensive experiments show that our approach can achieve consistent improvements over several typical and state-of-the-art segmentation baseline models on challenging public benchmarks. The code will be released soon.