 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Data Influence with Differential Approximation
Aug 20, 2025Data plays a pivotal role in the groundbreaking advancements in artificial intelligence. The quantitative analysis of data significantly contributes to model training, enhancing both the efficiency and quality of data utilization. However, existing data analysis tools often lag in accuracy. For instance, many of these tools even assume that the loss function of neural networks is convex. These limitations make it challenging to implement current methods effectively. In this paper, we introduce a new formulation to approximate a sample's influence by accumulating the differences in influence between consecutive learning steps, which we term Diff-In. Specifically, we formulate the sample-wise influence as the cumulative sum of its changes/differences across successive training iterations. By employing second-order approximations, we approximate these difference terms with high accuracy while eliminating the need for model convexity required by existing methods. Despite being a second-order method, Diff-In maintains computational complexity comparable to that of first-order methods and remains scalable. This efficiency is achieved by computing the product of the Hessian and gradient, which can be efficiently approximated using finite differences of first-order gradients. We assess the approximation accuracy of Diff-In both theoretically and empirically. Our theoretical analysis demonstrates that Diff-In achieves significantly lower approximation error compared to existing influence estimators. Extensive experiments further confirm its superior performance across multiple benchmark datasets in three data-centric tasks: data cleaning, data deletion, and coreset selection. Notably, our experiments on data pruning for large-scale vision-language pre-training show that Diff-In can scale to millions of data points and outperforms strong baselines.
Structure-Aware Radar-Camera Depth Estimation
Jun 05, 2025Monocular depth estimation aims to determine the depth of each pixel from an RGB image captured by a monocular camera. The development of deep learning has significantly advanced this field by facilitating the learning of depth features from some well-annotated datasets \cite{Geiger_Lenz_Stiller_Urtasun_2013,silberman2012indoor}. Eigen \textit{et al.} \cite{eigen2014depth} first introduce a multi-scale fusion network for depth regression. Following this, subsequent improvements have come from reinterpreting the regression task as a classification problem \cite{bhat2021adabins,Li_Wang_Liu_Jiang_2022}, incorporating additional priors \cite{shao2023nddepth,yang2023gedepth}, and developing more effective objective function \cite{xian2020structure,Yin_Liu_Shen_Yan_2019}. Despite these advances, generalizing to unseen domains remains a challenge. Recently, several methods have employed affine-invariant loss to enable multi-dataset joint training \cite{MiDaS,ZeroDepth,guizilini2023towards,Dany}. Among them, Depth Anything \cite{Dany} has shown leading performance in zero-shot monocular depth estimation. While it struggles to estimate accurate metric depth due to the lack of explicit depth cues, it excels at extracting structural information from unseen images, producing structure-detailed monocular depth.
Iterative Reconstruction Based on Latent Diffusion Model for Sparse Data Reconstruction
Jul 22, 2023



Reconstructing Computed tomography (CT) images from sparse measurement is a well-known ill-posed inverse problem. The Iterative Reconstruction (IR) algorithm is a solution to inverse problems. However, recent IR methods require paired data and the approximation of the inverse projection matrix. To address those problems, we present Latent Diffusion Iterative Reconstruction (LDIR), a pioneering zero-shot method that extends IR with a pre-trained Latent Diffusion Model (LDM) as a accurate and efficient data prior. By approximating the prior distribution with an unconditional latent diffusion model, LDIR is the first method to successfully integrate iterative reconstruction and LDM in an unsupervised manner. LDIR makes the reconstruction of high-resolution images more efficient. Moreover, LDIR utilizes the gradient from the data-fidelity term to guide the sampling process of the LDM, therefore, LDIR does not need the approximation of the inverse projection matrix and can solve various CT reconstruction tasks with a single model. Additionally, for enhancing the sample consistency of the reconstruction, we introduce a novel approach that uses historical gradient information to guide the gradient. Our experiments on extremely sparse CT data reconstruction tasks show that LDIR outperforms other state-of-the-art unsupervised and even exceeds supervised methods, establishing it as a leading technique in terms of both quantity and quality. Furthermore, LDIR also achieves competitive performance on nature image tasks. It is worth noting that LDIR also exhibits significantly faster execution times and lower memory consumption compared to methods with similar network settings. Our code will be publicly available.
AccUDNN: A GPU Memory Efficient Accelerator for Training Ultra-deep Deep Neural Networks
Jan 21, 2019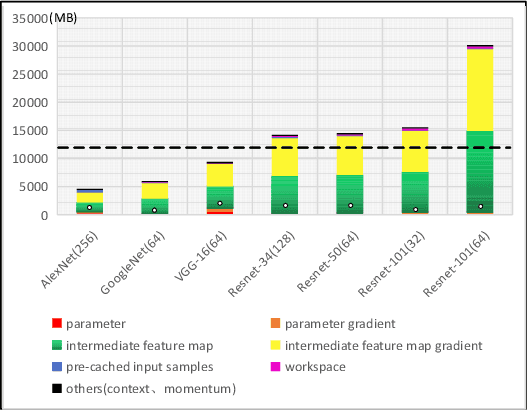
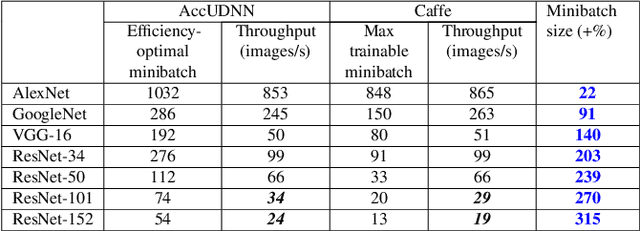
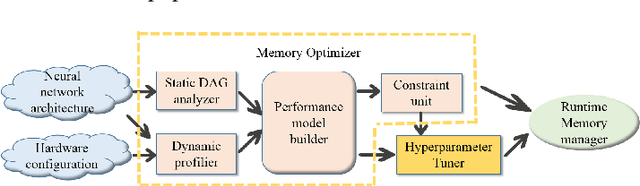
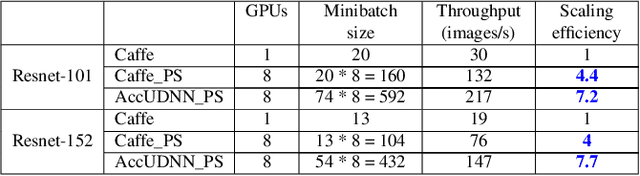
Typically, Ultra-deep neural network(UDNN) tends to yield high-quality model, but its training process is usually resource intensive and time-consuming. Modern GPU's scarce DRAM capacity is the primary bottleneck that hinders the trainability and the training efficiency of UDNN. In this paper, we present "AccUDNN", an accelerator that aims to make the utmost use of finite GPU memory resources to speed up the training process of UDNN. AccUDNN mainly includes two modules: memory optimizer and hyperparameter tuner. Memory optimizer develops a performance-model guided dynamic swap out/in strategy, by offloading appropriate data to host memory, GPU memory footprint can be significantly slashed to overcome the restriction of trainability of UDNN. After applying the memory optimization strategy, hyperparameter tuner is designed to explore the efficiency-optimal minibatch size and the matched learning rate. Evaluations demonstrate that AccUDNN cuts down the GPU memory requirement of ResNet-152 from more than 24GB to 8GB. In turn, given 12GB GPU memory budget, the efficiency-optimal minibatch size can reach 4.2x larger than original Caffe. Benefiting from better utilization of single GPU's computing resources and fewer parameter synchronization of large minibatch size, 7.7x speed-up is achieved by 8 GPUs' cluster without any communication optimization and no accuracy losses.