 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Few-Shot Learning for Talking Face System with TTS Data Augmentation
Mar 09, 2023Audio-driven talking face has attracted broad interest from academia and industry recently. However, data acquisition and labeling in audio-driven talking face are labor-intensive and costly. The lack of data resource results in poor synthesis effect. To alleviate this issue, we propose to use TTS (Text-To-Speech) for data augmentation to improve few-shot ability of the talking face system. The misalignment problem brought by the TTS audio is solved with the introduction of soft-DTW, which is first adopted in the talking face task. Moreover, features extracted by HuBERT are explored to utilize underlying information of audio, and found to be superior over other features. The proposed method achieves 17%, 14%, 38% dominance on MSE score, DTW score and user study preference repectively over the baseline model, which shows the effectiveness of improving few-shot learning for talking face system with TTS augmentation.
AccUDNN: A GPU Memory Efficient Accelerator for Training Ultra-deep Deep Neural Networks
Jan 21, 2019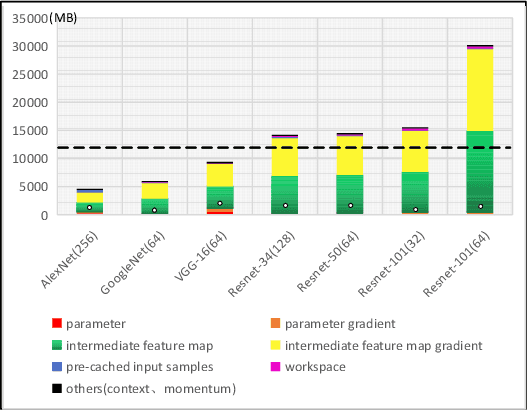
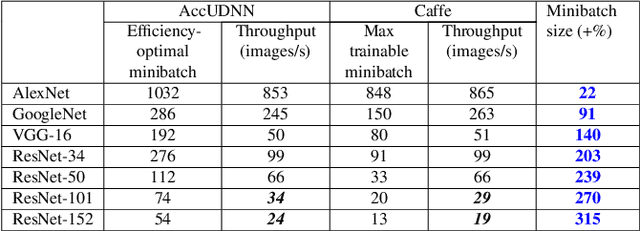
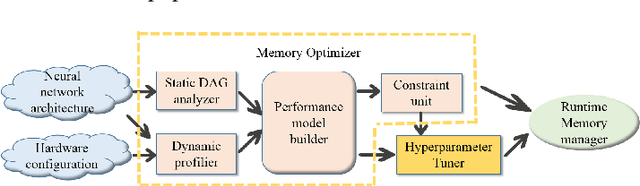
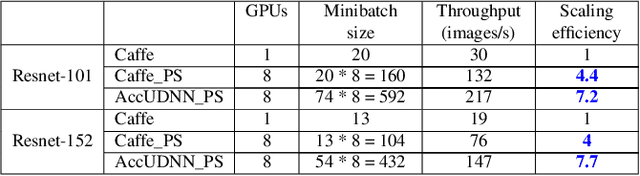
Typically, Ultra-deep neural network(UDNN) tends to yield high-quality model, but its training process is usually resource intensive and time-consuming. Modern GPU's scarce DRAM capacity is the primary bottleneck that hinders the trainability and the training efficiency of UDNN. In this paper, we present "AccUDNN", an accelerator that aims to make the utmost use of finite GPU memory resources to speed up the training process of UDNN. AccUDNN mainly includes two modules: memory optimizer and hyperparameter tuner. Memory optimizer develops a performance-model guided dynamic swap out/in strategy, by offloading appropriate data to host memory, GPU memory footprint can be significantly slashed to overcome the restriction of trainability of UDNN. After applying the memory optimization strategy, hyperparameter tuner is designed to explore the efficiency-optimal minibatch size and the matched learning rate. Evaluations demonstrate that AccUDNN cuts down the GPU memory requirement of ResNet-152 from more than 24GB to 8GB. In turn, given 12GB GPU memory budget, the efficiency-optimal minibatch size can reach 4.2x larger than original Caffe. Benefiting from better utilization of single GPU's computing resources and fewer parameter synchronization of large minibatch size, 7.7x speed-up is achieved by 8 GPUs' cluster without any communication optimization and no accuracy losses.