 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaveSFNet: A Wavelet-Based Codec and Spatial--Frequency Dual-Domain Gating Network for Spatiotemporal Prediction
Mar 24, 2026Spatiotemporal predictive learning aims to forecast future frames from historical observations in an unsupervised manner, and is critical to a wide range of applications. The key challenge is to model long-range dynamics while preserving high-frequency details for sharp multi-step predictions. Existing efficient recurrent-free frameworks typically rely on strided convolutions or pooling for sampling, which tends to discard textures and boundaries, while purely spatial operators often struggle to balance local interactions with global propagation. To address these issues, we propose WaveSFNet, an efficient framework that unifies a wavelet-based codec with a spatial--frequency dual-domain gated spatiotemporal translator. The wavelet-based codec preserves high-frequency subband cues during downsampling and reconstruction. Meanwhile, the translator first injects adjacent-frame differences to explicitly enhance dynamic information, and then performs dual-domain gated fusion between large-kernel spatial local modeling and frequency-domain global modulation, together with gated channel interaction for cross-channel feature exchange. Extensive experiments demonstrate that WaveSFNet achieves competitive prediction accuracy on Moving MNIST, TaxiBJ, and WeatherBench, while maintaining low computational complexity. Our code is available at https://github.com/fhjdqaq/WaveSFNet.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
MedSAM-U: Uncertainty-Guided Auto Multi-Prompt Adaptation for Reliable MedSAM
Sep 02, 2024



The Medical Segment Anything Model (MedSAM) has shown remarkable performance in medical image segmentation, drawing significant attention in the field. However, its sensitivity to varying prompt types and locations poses challenges. This paper addresses these challenges by focusing on the development of reliable prompts that enhance MedSAM's accuracy. We introduce MedSAM-U, an uncertainty-guided framework designed to automatically refine multi-prompt inputs for more reliable and precise medical image segmentation. Specifically, we first train a Multi-Prompt Adapter integrated with MedSAM, creating MPA-MedSAM, to adapt to diverse multi-prompt inputs. We then employ uncertainty-guided multi-prompt to effectively estimate the uncertainties associated with the prompts and their initial segmentation results. In particular, a novel uncertainty-guided prompts adaptation technique is then applied automatically to derive reliable prompts and their corresponding segmentation outcomes. We validate MedSAM-U using datasets from multiple modalities to train a universal image segmentation model. Compared to MedSAM, experimental results on five distinct modal datasets demonstrate that the proposed MedSAM-U achieves an average performance improvement of 1.7\% to 20.5\% across uncertainty-guided prompts.
Textual Inversion and Self-supervised Refinement for Radiology Report Generation
May 31, 2024Existing mainstream approaches follow the encoder-decoder paradigm for generating radiology reports. They focus on improving the network structure of encoders and decoders, which leads to two shortcomings: overlooking the modality gap and ignoring report content constraints. In this paper, we proposed Textual Inversion and Self-supervised Refinement (TISR) to address the above two issues. Specifically, textual inversion can project text and image into the same space by representing images as pseudo words to eliminate the cross-modeling gap. Subsequently, self-supervised refinement refines these pseudo words through contrastive loss computation between images and texts, enhancing the fidelity of generated reports to images. Notably, TISR is orthogonal to most existing methods, plug-and-play. We conduct experiments on two widely-used public datasets and achieve significant improvements on various baselines, which demonstrates the effectiveness and generalization of TISR. The code will be available soon.
Diffusion Posterior Proximal Sampling for Image Restoration
Feb 25, 2024



Diffusion models have demonstrated remarkable efficacy in generating high-quality samples. Existing diffusion-based image restoration algorithms exploit pre-trained diffusion models to leverage data priors, yet they still preserve elements inherited from the unconditional generation paradigm. These strategies initiate the denoising process with pure white noise and incorporate random noise at each generative step, leading to over-smoothed results. In this paper, we introduce a refined paradigm for diffusion-based image restoration. Specifically, we opt for a sample consistent with the measurement identity at each generative step, exploiting the sampling selection as an avenue for output stability and enhancement. Besides, we start the restoration process with an initialization combined with the measurement signal, providing supplementary information to better align the generative process. Extensive experimental results and analyses validate the effectiveness of our proposed approach across diverse image restoration tasks.
Iterative Reconstruction Based on Latent Diffusion Model for Sparse Data Reconstruction
Jul 22, 2023



Reconstructing Computed tomography (CT) images from sparse measurement is a well-known ill-posed inverse problem. The Iterative Reconstruction (IR) algorithm is a solution to inverse problems. However, recent IR methods require paired data and the approximation of the inverse projection matrix. To address those problems, we present Latent Diffusion Iterative Reconstruction (LDIR), a pioneering zero-shot method that extends IR with a pre-trained Latent Diffusion Model (LDM) as a accurate and efficient data prior. By approximating the prior distribution with an unconditional latent diffusion model, LDIR is the first method to successfully integrate iterative reconstruction and LDM in an unsupervised manner. LDIR makes the reconstruction of high-resolution images more efficient. Moreover, LDIR utilizes the gradient from the data-fidelity term to guide the sampling process of the LDM, therefore, LDIR does not need the approximation of the inverse projection matrix and can solve various CT reconstruction tasks with a single model. Additionally, for enhancing the sample consistency of the reconstruction, we introduce a novel approach that uses historical gradient information to guide the gradient. Our experiments on extremely sparse CT data reconstruction tasks show that LDIR outperforms other state-of-the-art unsupervised and even exceeds supervised methods, establishing it as a leading technique in terms of both quantity and quality. Furthermore, LDIR also achieves competitive performance on nature image tasks. It is worth noting that LDIR also exhibits significantly faster execution times and lower memory consumption compared to methods with similar network settings. Our code will be publicly available.
Hierarchical Disentangled Representation for Invertible Image Denoising and Beyond
Jan 31, 2023
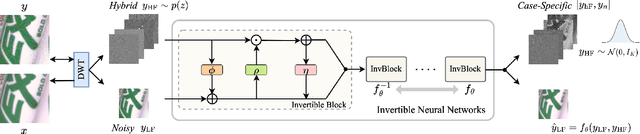
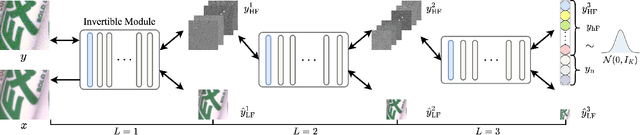
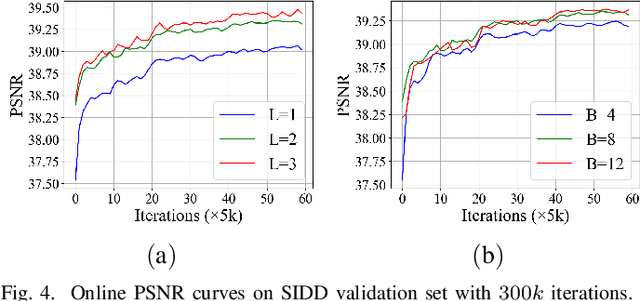
Image denoising is a typical ill-posed problem due to complex degradation. Leading methods based on normalizing flows have tried to solve this problem with an invertible transformation instead of a deterministic mapping. However, the implicit bijective mapping is not explored well. Inspired by a latent observation that noise tends to appear in the high-frequency part of the image, we propose a fully invertible denoising method that injects the idea of disentangled learning into a general invertible neural network to split noise from the high-frequency part. More specifically, we decompose the noisy image into clean low-frequency and hybrid high-frequency parts with an invertible transformation and then disentangle case-specific noise and high-frequency components in the latent space. In this way, denoising is made tractable by inversely merging noiseless low and high-frequency parts. Furthermore, we construct a flexible hierarchical disentangling framework, which aims to decompose most of the low-frequency image information while disentangling noise from the high-frequency part in a coarse-to-fine manner. Extensive experiments on real image denoising, JPEG compressed artifact removal, and medical low-dose CT image restoration have demonstrated that the proposed method achieves competing performance on both quantitative metrics and visual quality, with significantly less computational cost.
Low-resource Personal Attribute Prediction from Conversation
Nov 28, 2022



Personal knowledge bases (PKBs) are crucial for a broad range of applications such as personalized recommendation and Web-based chatbots. A critical challenge to build PKBs is extracting personal attribute knowledge from users' conversation data. Given some users of a conversational system, a personal attribute and these users' utterances, our goal is to predict the ranking of the given personal attribute values for each user. Previous studies often rely on a relative number of resources such as labeled utterances and external data, yet the attribute knowledge embedded in unlabeled utterances is underutilized and their performance of predicting some difficult personal attributes is still unsatisfactory. In addition, it is found that some text classification methods could be employed to resolve this task directly. However, they also perform not well over those difficult personal attributes. In this paper, we propose a novel framework PEARL to predict personal attributes from conversations by leveraging the abundant personal attribute knowledge from utterances under a low-resource setting in which no labeled utterances or external data are utilized. PEARL combines the biterm semantic information with the word co-occurrence information seamlessly via employing the updated prior attribute knowledge to refine the biterm topic model's Gibbs sampling process in an iterative manner. The extensive experimental results show that PEARL outperforms all the baseline methods not only on the task of personal attribute prediction from conversations over two data sets, but also on the more general weakly supervised text classification task over one data set.
Unsupervised Denoising of Optical Coherence Tomography Images with Dual_Merged CycleWGAN
May 02, 2022


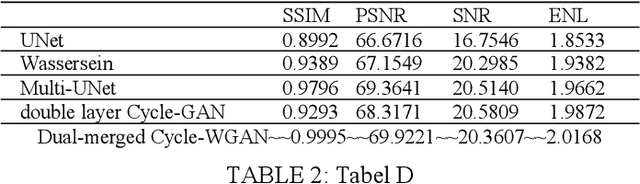
Nosie is an important cause of low quality Optical coherence tomography (OCT) image. The neural network model based on Convolutional neural networks(CNNs) has demonstrated its excellent performance in image denoising. However, OCT image denoising still faces great challenges because many previous neural network algorithms required a large number of labeled data, which might cost much time or is expensive. Besides, these CNN-based algorithms need numerous parameters and good tuning techniques, which is hardware resources consuming. To solved above problems, We proposed a new Cycle-Consistent Generative Adversarial Nets called Dual-Merged Cycle-WGAN for retinal OCT image denoiseing, which has remarkable performance with less unlabeled traning data. Our model consists of two Cycle-GAN networks with imporved generator, descriminator and wasserstein loss to achieve good training stability and better performance. Using image merge technique between two Cycle-GAN networks, our model could obtain more detailed information and hence better training effect. The effectiveness and generality of our proposed network has been proved via ablation experiments and comparative experiments. Compared with other state-of-the-art methods, our unsupervised method obtains best subjective visual effect and higher evaluation objective indicators.
Depth Completion using Geometry-Aware Embedding
Mar 21, 2022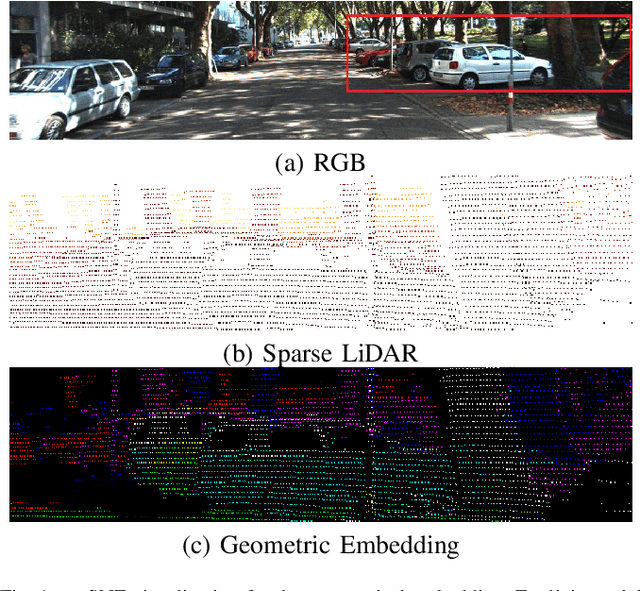

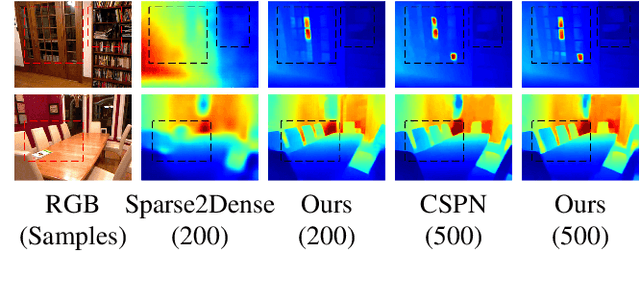
Exploiting internal spatial geometric constraints of sparse LiDARs is beneficial to depth completion, however, has been not explored well. This paper proposes an efficient method to learn geometry-aware embedding, which encodes the local and global geometric structure information from 3D points, e.g., scene layout, object's sizes and shapes, to guide dense depth estimation. Specifically, we utilize the dynamic graph representation to model generalized geometric relationship from irregular point clouds in a flexible and efficient manner. Further, we joint this embedding and corresponded RGB appearance information to infer missing depths of the scene with well structure-preserved details. The key to our method is to integrate implicit 3D geometric representation into a 2D learning architecture, which leads to a better trade-off between the performance and efficiency. Extensive experiments demonstrate that the proposed method outperforms previous works and could reconstruct fine depths with crisp boundaries in regions that are over-smoothed by them. The ablation study gives more insights into our method that could achieve significant gains with a simple design, while having better generalization capability and stability. The code is available at https://github.com/Wenchao-Du/GAENet.