 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Denoising of Optical Coherence Tomography Images with Dual_Merged CycleWGAN
May 02, 2022


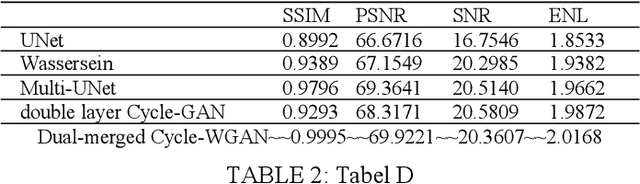
Nosie is an important cause of low quality Optical coherence tomography (OCT) image. The neural network model based on Convolutional neural networks(CNNs) has demonstrated its excellent performance in image denoising. However, OCT image denoising still faces great challenges because many previous neural network algorithms required a large number of labeled data, which might cost much time or is expensive. Besides, these CNN-based algorithms need numerous parameters and good tuning techniques, which is hardware resources consuming. To solved above problems, We proposed a new Cycle-Consistent Generative Adversarial Nets called Dual-Merged Cycle-WGAN for retinal OCT image denoiseing, which has remarkable performance with less unlabeled traning data. Our model consists of two Cycle-GAN networks with imporved generator, descriminator and wasserstein loss to achieve good training stability and better performance. Using image merge technique between two Cycle-GAN networks, our model could obtain more detailed information and hence better training effect. The effectiveness and generality of our proposed network has been proved via ablation experiments and comparative experiments. Compared with other state-of-the-art methods, our unsupervised method obtains best subjective visual effect and higher evaluation objective indicators.
Make A Long Image Short: Adaptive Token Length for Vision Transformers
Dec 06, 2021The vision transformer splits each image into a sequence of tokens with fixed length and processes the tokens in the same way as words in natural language processing. More tokens normally lead to better performance but considerably increased computational cost. Motivated by the proverb "A picture is worth a thousand words" we aim to accelerate the ViT model by making a long image short. To this end, we propose a novel approach to assign token length adaptively during inference. Specifically, we first train a ViT model, called Resizable-ViT (ReViT), that can process any given input with diverse token lengths. Then, we retrieve the "token-length label" from ReViT and use it to train a lightweight Token-Length Assigner (TLA). The token-length labels are the smallest number of tokens to split an image that the ReViT can make the correct prediction, and TLA is learned to allocate the optimal token length based on these labels. The TLA enables the ReViT to process the image with the minimum sufficient number of tokens during inference. Thus, the inference speed is boosted by reducing the token numbers in the ViT model. Our approach is general and compatible with modern vision transformer architectures and can significantly reduce computational expanse. We verified the effectiveness of our methods on multiple representative ViT models (DeiT, LV-ViT, and TimesFormer) across two tasks (image classification and action recognition).
Training BatchNorm Only in Neural Architecture Search and Beyond
Dec 01, 2021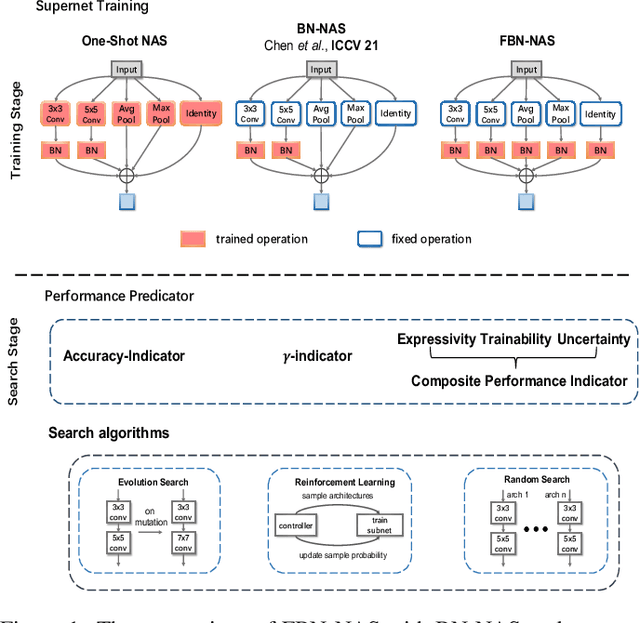

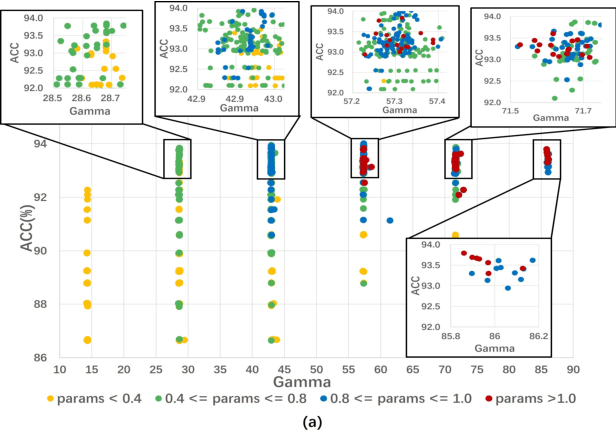

This work investigates the usage of batch normalization in neural architecture search (NAS). Specifically, Frankle et al. find that training BatchNorm only can achieve nontrivial performance. Furthermore, Chen et al. claim that training BatchNorm only can speed up the training of the one-shot NAS supernet over ten times. Critically, there is no effort to understand 1) why training BatchNorm only can find the perform-well architectures with the reduced supernet-training time, and 2) what is the difference between the train-BN-only supernet and the standard-train supernet. We begin by showing that the train-BN-only networks converge to the neural tangent kernel regime, obtain the same training dynamics as train all parameters theoretically. Our proof supports the claim to train BatchNorm only on supernet with less training time. Then, we empirically disclose that train-BN-only supernet provides an advantage on convolutions over other operators, cause unfair competition between architectures. This is due to only the convolution operator being attached with BatchNorm. Through experiments, we show that such unfairness makes the search algorithm prone to select models with convolutions. To solve this issue, we introduce fairness in the search space by placing a BatchNorm layer on every operator. However, we observe that the performance predictor in Chen et al. is inapplicable on the new search space. To this end, we propose a novel composite performance indicator to evaluate networks from three perspectives: expressivity, trainability, and uncertainty, derived from the theoretical property of BatchNorm. We demonstrate the effectiveness of our approach on multiple NAS-benchmarks (NAS-Bench101, NAS-Bench-201) and search spaces (DARTS search space and MobileNet search space).
Sparse Bayesian Learning with Diagonal Quasi-Newton Method For Large Scale Classification
Jul 17, 2021



Sparse Bayesian Learning (SBL) constructs an extremely sparse probabilistic model with very competitive generalization. However, SBL needs to invert a big covariance matrix with complexity O(M^3 ) (M: feature size) for updating the regularization priors, making it difficult for practical use. There are three issues in SBL: 1) Inverting the covariance matrix may obtain singular solutions in some cases, which hinders SBL from convergence; 2) Poor scalability to problems with high dimensional feature space or large data size; 3) SBL easily suffers from memory overflow for large-scale data. This paper addresses these issues with a newly proposed diagonal Quasi-Newton (DQN) method for SBL called DQN-SBL where the inversion of big covariance matrix is ignored so that the complexity and memory storage are reduced to O(M). The DQN-SBL is thoroughly evaluated on non-linear classifiers and linear feature selection using various benchmark datasets of different sizes. Experimental results verify that DQN-SBL receives competitive generalization with a very sparse model and scales well to large-scale problems.