 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemanticStitch: Enhancing Image Coherence through Foreground-Aware Seam Carving
Nov 15, 2025Image stitching often faces challenges due to varying capture angles, positional differences, and object movements, leading to misalignments and visual discrepancies. Traditional seam carving methods neglect semantic information, causing disruptions in foreground continuity. We introduce SemanticStitch, a deep learning-based framework that incorporates semantic priors of foreground objects to preserve their integrity and enhance visual coherence. Our approach includes a novel loss function that emphasizes the semantic integrity of salient objects, significantly improving stitching quality. We also present two specialized real-world datasets to evaluate our method's effectiveness. Experimental results demonstrate substantial improvements over traditional techniques, providing robust support for practical applications.
Cross-View UAV Geo-Localization with Precision-Focused Efficient Design: A Hierarchical Distillation Approach with Multi-view Refinement
Oct 26, 2025Cross-view geo-localization (CVGL) enables UAV localization by matching aerial images to geo-tagged satellite databases, which is critical for autonomous navigation in GNSS-denied environments. However, existing methods rely on resource-intensive fine-grained feature extraction and alignment, where multiple branches and modules significantly increase inference costs, limiting their deployment on edge devices. We propose Precision-Focused Efficient Design (PFED), a resource-efficient framework combining hierarchical knowledge transfer and multi-view representation refinement. This innovative method comprises two key components: 1) During training, Hierarchical Distillation paradigm for fast and accurate CVGL (HD-CVGL), coupled with Uncertainty-Aware Prediction Alignment (UAPA) to distill essential information and mitigate the data imbalance without incurring additional inference overhead. 2) During inference, an efficient Multi-view Refinement Module (MRM) leverages mutual information to filter redundant samples and effectively utilize the multi-view data. Extensive experiments show that PFED achieves state-of-the-art performance in both accuracy and efficiency, reaching 97.15\% Recall@1 on University-1652 while being over $5 \times$ more efficient in FLOPs and $3 \times$ faster than previous top methods. Furthermore, PFED runs at 251.5 FPS on the AGX Orin edge device, demonstrating its practical viability for real-time UAV applications. The project is available at https://github.com/SkyEyeLoc/PFED
3D Hand Mesh-Guided AI-Generated Malformed Hand Refinement with Hand Pose Transformation via Diffusion Model
Jun 15, 2025The malformed hands in the AI-generated images seriously affect the authenticity of the images. To refine malformed hands, existing depth-based approaches use a hand depth estimator to guide the refinement of malformed hands. Due to the performance limitations of the hand depth estimator, many hand details cannot be represented, resulting in errors in the generated hands, such as confusing the palm and the back of the hand. To solve this problem, we propose a 3D mesh-guided refinement framework using a diffusion pipeline. We use a state-of-the-art 3D hand mesh estimator, which provides more details of the hands. For training, we collect and reannotate a dataset consisting of RGB images and 3D hand mesh. Then we design a diffusion inpainting model to generate refined outputs guided by 3D hand meshes. For inference, we propose a double check algorithm to facilitate the 3D hand mesh estimator to obtain robust hand mesh guidance to obtain our refined results. Beyond malformed hand refinement, we propose a novel hand pose transformation method. It increases the flexibility and diversity of the malformed hand refinement task. We made the restored images mimic the hand poses of the reference images. The pose transformation requires no additional training. Extensive experimental results demonstrate the superior performance of our proposed method.
Exploiting the Potential Supervision Information of Clean Samples in Partial Label Learning
May 14, 2025Diminishing the impact of false-positive labels is critical for conducting disambiguation in partial label learning. However, the existing disambiguation strategies mainly focus on exploiting the characteristics of individual partial label instances while neglecting the strong supervision information of clean samples randomly lying in the datasets. In this work, we show that clean samples can be collected to offer guidance and enhance the confidence of the most possible candidates. Motivated by the manner of the differentiable count loss strat- egy and the K-Nearest-Neighbor algorithm, we proposed a new calibration strategy called CleanSE. Specifically, we attribute the most reliable candidates with higher significance under the assumption that for each clean sample, if its label is one of the candidates of its nearest neighbor in the representation space, it is more likely to be the ground truth of its neighbor. Moreover, clean samples offer help in characterizing the sample distributions by restricting the label counts of each label to a specific interval. Extensive experiments on 3 synthetic benchmarks and 5 real-world PLL datasets showed this calibration strategy can be applied to most of the state-of-the-art PLL methods as well as enhance their performance.
C-Adapter: Adapting Deep Classifiers for Efficient Conformal Prediction Sets
Oct 12, 2024Conformal prediction, as an emerging uncertainty quantification technique, typically functions as post-hoc processing for the outputs of trained classifiers. To optimize the classifier for maximum predictive efficiency, Conformal Training rectifies the training objective with a regularization that minimizes the average prediction set size at a specific error rate. However, the regularization term inevitably deteriorates the classification accuracy and leads to suboptimal efficiency of conformal predictors. To address this issue, we introduce \textbf{Conformal Adapter} (C-Adapter), an adapter-based tuning method to enhance the efficiency of conformal predictors without sacrificing accuracy. In particular, we implement the adapter as a class of intra order-preserving functions and tune it with our proposed loss that maximizes the discriminability of non-conformity scores between correctly and randomly matched data-label pairs. Using C-Adapter, the model tends to produce extremely high non-conformity scores for incorrect labels, thereby enhancing the efficiency of prediction sets across different coverage rates. Extensive experiments demonstrate that C-Adapter can effectively adapt various classifiers for efficient prediction sets, as well as enhance the conformal training method.
Spatial-Aware Conformal Prediction for Trustworthy Hyperspectral Image Classification
Sep 02, 2024Hyperspectral image (HSI) classification involves assigning specific labels to each pixel to identify various land cover categories. Although deep classifiers have shown high predictive accuracy in this field, quantifying their uncertainty remains a significant challenge, which hinders their application in critical contexts. This study first theoretically evaluates the applicability of \textit{Conformal Prediction} (CP), an emerging technique for uncertainty quantification, in the context of HSI classification. We then propose a conformal procedure that provides HSI classifiers with trustworthy prediction sets, offering coverage guarantees that ensure these sets contain the true labels with a user-specified probability. Building on this foundation, we introduce \textit{Spatial-Aware Conformal Prediction} (\texttt{SACP}), which incorporates essential spatial information inherent in HSIs by aggregating non-conformity scores of pixels with high spatial correlation. Both theoretical and empirical results demonstrate that \texttt{SACP} outperforms standard CP in HSI classification. The source code is accessible at \url{https://github.com/J4ckLiu/SACP}.
OE-BevSeg: An Object Informed and Environment Aware Multimodal Framework for Bird's-eye-view Vehicle Semantic Segmentation
Jul 18, 2024Bird's-eye-view (BEV) semantic segmentation is becoming crucial in autonomous driving systems. It realizes ego-vehicle surrounding environment perception by projecting 2D multi-view images into 3D world space. Recently, BEV segmentation has made notable progress, attributed to better view transformation modules, larger image encoders, or more temporal information. However, there are still two issues: 1) a lack of effective understanding and enhancement of BEV space features, particularly in accurately capturing long-distance environmental features and 2) recognizing fine details of target objects. To address these issues, we propose OE-BevSeg, an end-to-end multimodal framework that enhances BEV segmentation performance through global environment-aware perception and local target object enhancement. OE-BevSeg employs an environment-aware BEV compressor. Based on prior knowledge about the main composition of the BEV surrounding environment varying with the increase of distance intervals, long-sequence global modeling is utilized to improve the model's understanding and perception of the environment. From the perspective of enriching target object information in segmentation results, we introduce the center-informed object enhancement module, using centerness information to supervise and guide the segmentation head, thereby enhancing segmentation performance from a local enhancement perspective. Additionally, we designed a multimodal fusion branch that integrates multi-view RGB image features with radar/LiDAR features, achieving significant performance improvements. Extensive experiments show that, whether in camera-only or multimodal fusion BEV segmentation tasks, our approach achieves state-of-the-art results by a large margin on the nuScenes dataset for vehicle segmentation, demonstrating superior applicability in the field of autonomous driving.
Boosting Few-Shot Semantic Segmentation Via Segment Anything Model
Jan 20, 2024In semantic segmentation, accurate prediction masks are crucial for downstream tasks such as medical image analysis and image editing. Due to the lack of annotated data, few-shot semantic segmentation (FSS) performs poorly in predicting masks with precise contours. Recently, we have noticed that the large foundation model segment anything model (SAM) performs well in processing detailed features. Inspired by SAM, we propose FSS-SAM to boost FSS methods by addressing the issue of inaccurate contour. The FSS-SAM is training-free. It works as a post-processing tool for any FSS methods and can improve the accuracy of predicted masks. Specifically, we use predicted masks from FSS methods to generate prompts and then use SAM to predict new masks. To avoid predicting wrong masks with SAM, we propose a prediction result selection (PRS) algorithm. The algorithm can remarkably decrease wrong predictions. Experiment results on public datasets show that our method is superior to base FSS methods in both quantitative and qualitative aspects.
Single-Stage Broad Multi-Instance Multi-Label Learning with Diverse Inter-Correlations and its application to medical image classification
Sep 06, 2022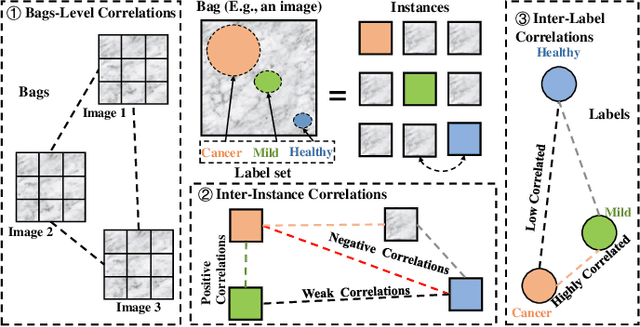
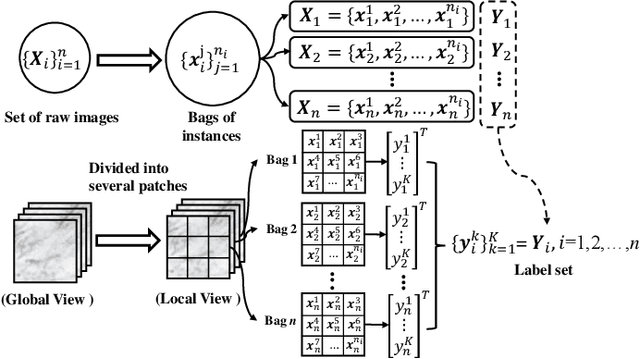
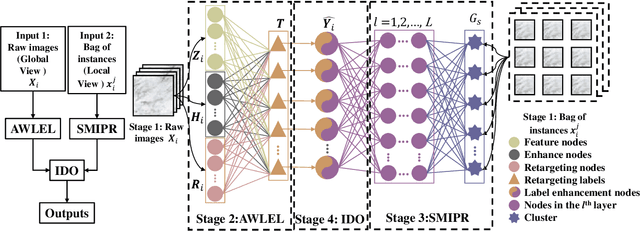
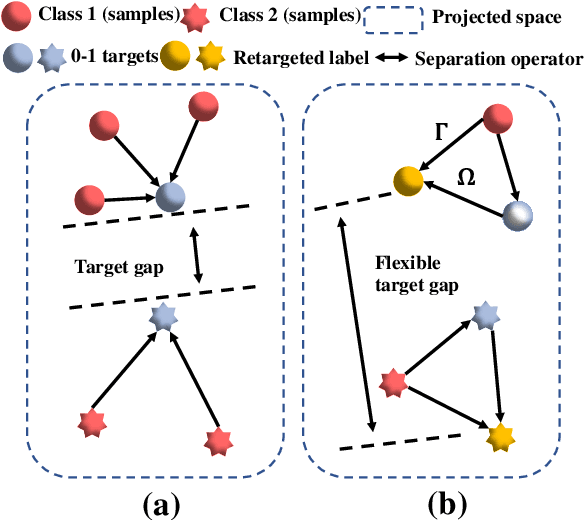
In many real-world applications, one object (e.g., image) can be represented or described by multiple instances (e.g., image patches) and simultaneously associated with multiple labels. Such applications can be formulated as multi-instance multi-label learning (MIML) problems and have been extensively studied during the past few years. Existing MIML methods are useful in many applications but most of which suffer from relatively low accuracy and training efficiency due to several issues: i) the inter-label correlations (i.e., the probabilistic correlations between the multiple labels corresponding to an object) are neglected; ii) the inter-instance correlations cannot be learned directly (or jointly) with other types of correlations due to the missing instance labels; iii) diverse inter-correlations (e.g., inter-label correlations, inter-instance correlations) can only be learned in multiple stages. To resolve these issues, a new single-stage framework called broad multi-instance multi-label learning (BMIML) is proposed. In BMIML, there are three innovative modules: i) an auto-weighted label enhancement learning (AWLEL) based on broad learning system (BLS); ii) A specific MIML neural network called scalable multi-instance probabilistic regression (SMIPR); iii) Finally, an interactive decision optimization (IDO). As a result, BMIML can achieve simultaneous learning of diverse inter-correlations between whole images, instances, and labels in single stage for higher classification accuracy and much faster training time. Experiments show that BMIML is highly competitive to (or even better than) existing methods in accuracy and much faster than most MIML methods even for large medical image data sets (> 90K images).
Sparse Bayesian Learning with Diagonal Quasi-Newton Method For Large Scale Classification
Jul 17, 2021



Sparse Bayesian Learning (SBL) constructs an extremely sparse probabilistic model with very competitive generalization. However, SBL needs to invert a big covariance matrix with complexity O(M^3 ) (M: feature size) for updating the regularization priors, making it difficult for practical use. There are three issues in SBL: 1) Inverting the covariance matrix may obtain singular solutions in some cases, which hinders SBL from convergence; 2) Poor scalability to problems with high dimensional feature space or large data size; 3) SBL easily suffers from memory overflow for large-scale data. This paper addresses these issues with a newly proposed diagonal Quasi-Newton (DQN) method for SBL called DQN-SBL where the inversion of big covariance matrix is ignored so that the complexity and memory storage are reduced to O(M). The DQN-SBL is thoroughly evaluated on non-linear classifiers and linear feature selection using various benchmark datasets of different sizes. Experimental results verify that DQN-SBL receives competitive generalization with a very sparse model and scales well to large-scale problems.