 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepInflation: an AI agent for research and model discovery of inflation
Jan 14, 2026We present \textbf{DeepInflation}, an AI agent designed for research and model discovery in inflationary cosmology. Built upon a multi-agent architecture, \textbf{DeepInflation} integrates Large Language Models (LLMs) with a symbolic regression (SR) engine and a retrieval-augmented generation (RAG) knowledge base. This framework enables the agent to automatically explore and verify the vast landscape of inflationary potentials while grounding its outputs in established theoretical literature. We demonstrate that \textbf{DeepInflation} can successfully discover simple and viable single-field slow-roll inflationary potentials consistent with the latest observations (here ACT DR6 results as example) or any given $n_s$ and $r$, and provide accurate theoretical context for obscure inflationary scenarios. \textbf{DeepInflation} serves as a prototype for a new generation of autonomous scientific discovery engines in cosmology, which enables researchers and non-experts alike to explore the inflationary landscape using natural language. This agent is available at https://github.com/pengzy-cosmo/DeepInflation.
A Lightweight Multi-Scale Attention Framework for Real-Time Spinal Endoscopic Instance Segmentation
Dec 26, 2025Real-time instance segmentation for spinal endoscopy is important for identifying and protecting critical anatomy during surgery, but it is difficult because of the narrow field of view, specular highlights, smoke/bleeding, unclear boundaries, and large scale changes. Deployment is also constrained by limited surgical hardware, so the model must balance accuracy and speed and remain stable under small-batch (even batch-1) training. We propose LMSF-A, a lightweight multi-scale attention framework co-designed across backbone, neck, and head. The backbone uses a C2f-Pro module that combines RepViT-style re-parameterized convolution (RVB) with efficient multi-scale attention (EMA), enabling multi-branch training while collapsing into a single fast path for inference. The neck improves cross-scale consistency and boundary detail using Scale-Sequence Feature Fusion (SSFF) and Triple Feature Encoding (TFE), which strengthens high-resolution features. The head adopts a Lightweight Multi-task Shared Head (LMSH) with shared convolutions and GroupNorm to reduce parameters and support batch-1 stability. We also release the clinically reviewed PELD dataset (61 patients, 610 images) with instance masks for adipose tissue, bone, ligamentum flavum, and nerve. Experiments show that LMSF-A is highly competitive (or even better than) in all evaluation metrics and much lighter than most instance segmentation methods requiring only 1.8M parameters and 8.8 GFLOPs, and it generalizes well to a public teeth benchmark. Code and dataset: https://github.com/hhwmortal/PELD-Instance-segmentation.
Boosting Few-Shot Semantic Segmentation Via Segment Anything Model
Jan 20, 2024In semantic segmentation, accurate prediction masks are crucial for downstream tasks such as medical image analysis and image editing. Due to the lack of annotated data, few-shot semantic segmentation (FSS) performs poorly in predicting masks with precise contours. Recently, we have noticed that the large foundation model segment anything model (SAM) performs well in processing detailed features. Inspired by SAM, we propose FSS-SAM to boost FSS methods by addressing the issue of inaccurate contour. The FSS-SAM is training-free. It works as a post-processing tool for any FSS methods and can improve the accuracy of predicted masks. Specifically, we use predicted masks from FSS methods to generate prompts and then use SAM to predict new masks. To avoid predicting wrong masks with SAM, we propose a prediction result selection (PRS) algorithm. The algorithm can remarkably decrease wrong predictions. Experiment results on public datasets show that our method is superior to base FSS methods in both quantitative and qualitative aspects.
Towards Precise Weakly Supervised Object Detection via Interactive Contrastive Learning of Context Information
May 05, 2023



Weakly supervised object detection (WSOD) aims at learning precise object detectors with only image-level tags. In spite of intensive research on deep learning (DL) approaches over the past few years, there is still a significant performance gap between WSOD and fully supervised object detection. In fact, most existing WSOD methods only consider the visual appearance of each region proposal but ignore employing the useful context information in the image. To this end, this paper proposes an interactive end-to-end WSDO framework called JLWSOD with two innovations: i) two types of WSOD-specific context information (i.e., instance-wise correlation andsemantic-wise correlation) are proposed and introduced into WSOD framework; ii) an interactive graph contrastive learning (iGCL) mechanism is designed to jointly optimize the visual appearance and context information for better WSOD performance. Specifically, the iGCL mechanism takes full advantage of the complementary interpretations of the WSOD, namely instance-wise detection and semantic-wise prediction tasks, forming a more comprehensive solution. Extensive experiments on the widely used PASCAL VOC and MS COCO benchmarks verify the superiority of JLWSOD over alternative state-of-the-art approaches and baseline models (improvement of 3.6%~23.3% on mAP and 3.4%~19.7% on CorLoc, respectively).
Single-Stage Broad Multi-Instance Multi-Label Learning with Diverse Inter-Correlations and its application to medical image classification
Sep 06, 2022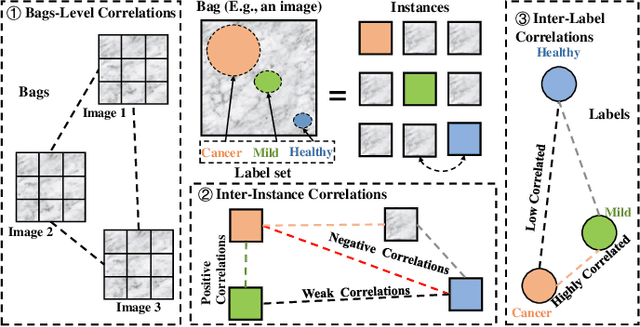
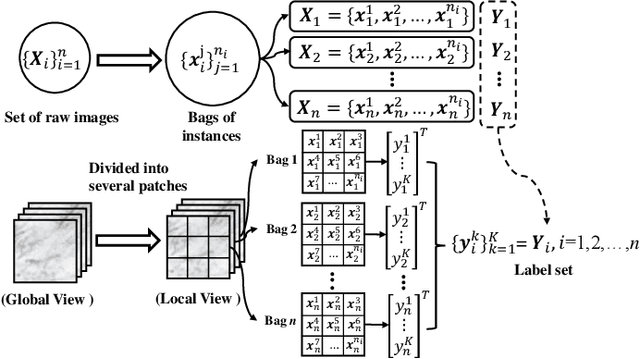
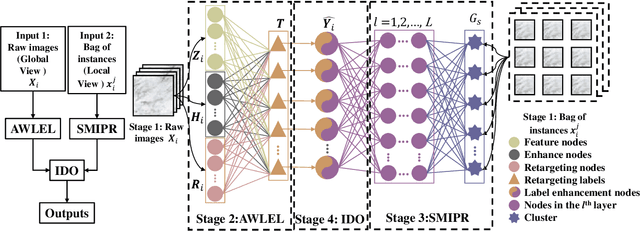
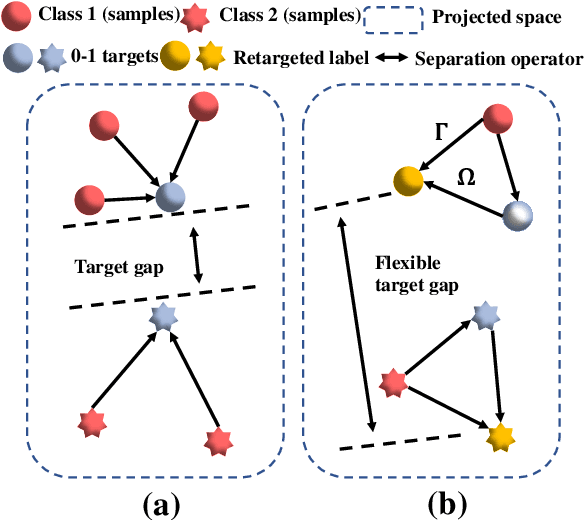
In many real-world applications, one object (e.g., image) can be represented or described by multiple instances (e.g., image patches) and simultaneously associated with multiple labels. Such applications can be formulated as multi-instance multi-label learning (MIML) problems and have been extensively studied during the past few years. Existing MIML methods are useful in many applications but most of which suffer from relatively low accuracy and training efficiency due to several issues: i) the inter-label correlations (i.e., the probabilistic correlations between the multiple labels corresponding to an object) are neglected; ii) the inter-instance correlations cannot be learned directly (or jointly) with other types of correlations due to the missing instance labels; iii) diverse inter-correlations (e.g., inter-label correlations, inter-instance correlations) can only be learned in multiple stages. To resolve these issues, a new single-stage framework called broad multi-instance multi-label learning (BMIML) is proposed. In BMIML, there are three innovative modules: i) an auto-weighted label enhancement learning (AWLEL) based on broad learning system (BLS); ii) A specific MIML neural network called scalable multi-instance probabilistic regression (SMIPR); iii) Finally, an interactive decision optimization (IDO). As a result, BMIML can achieve simultaneous learning of diverse inter-correlations between whole images, instances, and labels in single stage for higher classification accuracy and much faster training time. Experiments show that BMIML is highly competitive to (or even better than) existing methods in accuracy and much faster than most MIML methods even for large medical image data sets (> 90K images).