 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCR: Counterfactual Attractor Guidance for Rare Compositional Generation
May 07, 2026Diffusion models generate realistic visual content, yet often fail to produce rare but plausible compositions. When prompted with combinations that are valid but underrepresented in training data, such as a snowy beach or a rainbow at night, the generation process frequently collapses toward more common alternatives. We identify this failure mode as default completion bias, where denoising trajectories are implicitly attracted toward high-frequency semantic configurations. Existing guidance mechanisms do not explicitly model this competing tendency and therefore struggle to prevent such collapse. We introduce Default Completion Repulsion (DCR), a training-free framework that explicitly models and suppresses default completion behavior. DCR constructs a counterfactual attractor by relaxing the rare compositional factor while preserving surrounding semantics, inducing an alternative denoising trajectory reflecting the model's preferred completion. We define the discrepancy between target and attractor trajectories as a counterfactual drift, and propose a projection-based repulsion mechanism that removes guidance components aligned with this drift direction. This suppresses undesired frequent completions while preserving other semantic components. DCR operates entirely within the standard diffusion sampling process without retraining or architectural modification. Experiments on rare compositional prompts show that DCR improves compositional fidelity while maintaining visual quality. Our analysis further shows that the framework exposes and counteracts intrinsic model biases, offering a new perspective on controllable generation beyond explicit constraint enforcement.
SceneOrchestra: Efficient Agentic 3D Scene Synthesis via Full Tool-Call Trajectory Generation
Apr 21, 2026Recent agentic frameworks for 3D scene synthesis have advanced realism and diversity by integrating heterogeneous generation and editing tools. These tools are organized into workflows orchestrated by an off-the-shelf LLM. Current approaches typically adopt an execute-review-reflect loop: at each step, the orchestrator executes a tool, renders intermediate results for review, and then decides on the tool and its parameters for the next step. However, this design has two key limitations. First, next-step tool selection and parameter configuration are driven by heuristic rules, which can lead to suboptimal execution flows, unnecessary tool invocations, degraded output quality, and increased runtime. Second, rendering and reviewing intermediate results after each step introduces additional latency. To address these issues, we propose SceneOrchestra, a trainable orchestration framework that optimizes the tool-call execution flow and eliminates the step-by-step review loop, improving both efficiency and output quality. SceneOrchestra consists of an orchestrator and a discriminator, which we fine-tune with a two-phase training strategy. In the first phase, the orchestrator learns context-aware tool selection and complete tool-call trajectory generation, while the discriminator is trained to assess the quality of full trajectories, enabling it to select the best trajectory from multiple candidates. In the second phase, we perform interleaved training, where the discriminator adapts to the orchestrator's evolving trajectory distribution and distills its discriminative capability back into the orchestrator. At inference, we only use the orchestrator to generate and execute full tool-call trajectories from instructions, without requiring the discriminator. Extensive experiments show that our method achieves state-of-the-art scene quality while reducing runtime compared to previous work.
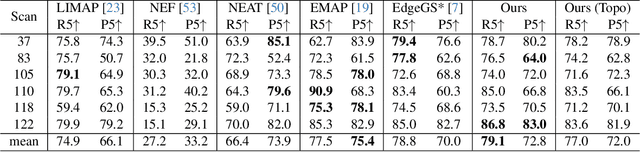
Rotated Lights for Consistent and Efficient 2D Gaussians Inverse Rendering
Feb 09, 2026Inverse rendering aims to decompose a scene into its geometry, material properties and light conditions under a certain rendering model. It has wide applications like view synthesis, relighting, and scene editing. In recent years, inverse rendering methods have been inspired by view synthesis approaches like neural radiance fields and Gaussian splatting, which are capable of efficiently decomposing a scene into its geometry and radiance. They then further estimate the material and lighting that lead to the observed scene radiance. However, the latter step is highly ambiguous and prior works suffer from inaccurate color and baked shadows in their albedo estimation albeit their regularization. To this end, we propose RotLight, a simple capturing setup, to address the ambiguity. Compared to a usual capture, RotLight only requires the object to be rotated several times during the process. We show that as few as two rotations is effective in reducing artifacts. To further improve 2DGS-based inverse rendering, we additionally introduce a proxy mesh that not only allows accurate incident light tracing, but also enables a residual constraint and improves global illumination handling. We demonstrate with both synthetic and real world datasets that our method achieves superior albedo estimation while keeping efficient computation.
LangDriveCTRL: Natural Language Controllable Driving Scene Editing with Multi-modal Agents
Dec 19, 2025

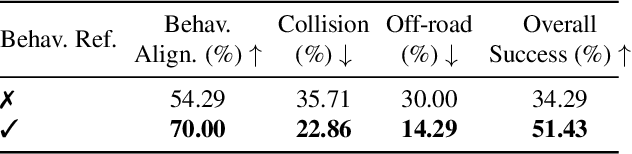

LangDriveCTRL is a natural-language-controllable framework for editing real-world driving videos to synthesize diverse traffic scenarios. It leverages explicit 3D scene decomposition to represent driving videos as a scene graph, containing static background and dynamic objects. To enable fine-grained editing and realism, it incorporates an agentic pipeline in which an Orchestrator transforms user instructions into execution graphs that coordinate specialized agents and tools. Specifically, an Object Grounding Agent establishes correspondence between free-form text descriptions and target object nodes in the scene graph; a Behavior Editing Agent generates multi-object trajectories from language instructions; and a Behavior Reviewer Agent iteratively reviews and refines the generated trajectories. The edited scene graph is rendered and then refined using a video diffusion tool to address artifacts introduced by object insertion and significant view changes. LangDriveCTRL supports both object node editing (removal, insertion and replacement) and multi-object behavior editing from a single natural-language instruction. Quantitatively, it achieves nearly $2\times$ higher instruction alignment than the previous SoTA, with superior structural preservation, photorealism, and traffic realism. Project page is available at: https://yunhe24.github.io/langdrivectrl/.
Speedy Deformable 3D Gaussian Splatting: Fast Rendering and Compression of Dynamic Scenes
Jun 09, 2025Recent extensions of 3D Gaussian Splatting (3DGS) to dynamic scenes achieve high-quality novel view synthesis by using neural networks to predict the time-varying deformation of each Gaussian. However, performing per-Gaussian neural inference at every frame poses a significant bottleneck, limiting rendering speed and increasing memory and compute requirements. In this paper, we present Speedy Deformable 3D Gaussian Splatting (SpeeDe3DGS), a general pipeline for accelerating the rendering speed of dynamic 3DGS and 4DGS representations by reducing neural inference through two complementary techniques. First, we propose a temporal sensitivity pruning score that identifies and removes Gaussians with low contribution to the dynamic scene reconstruction. We also introduce an annealing smooth pruning mechanism that improves pruning robustness in real-world scenes with imprecise camera poses. Second, we propose GroupFlow, a motion analysis technique that clusters Gaussians by trajectory similarity and predicts a single rigid transformation per group instead of separate deformations for each Gaussian. Together, our techniques accelerate rendering by $10.37\times$, reduce model size by $7.71\times$, and shorten training time by $2.71\times$ on the NeRF-DS dataset. SpeeDe3DGS also improves rendering speed by $4.20\times$ and $58.23\times$ on the D-NeRF and HyperNeRF vrig datasets. Our methods are modular and can be integrated into any deformable 3DGS or 4DGS framework.
How Learnable Grids Recover Fine Detail in Low Dimensions: A Neural Tangent Kernel Analysis of Multigrid Parametric Encodings
Apr 18, 2025Neural networks that map between low dimensional spaces are ubiquitous in computer graphics and scientific computing; however, in their naive implementation, they are unable to learn high frequency information. We present a comprehensive analysis comparing the two most common techniques for mitigating this spectral bias: Fourier feature encodings (FFE) and multigrid parametric encodings (MPE). FFEs are seen as the standard for low dimensional mappings, but MPEs often outperform them and learn representations with higher resolution and finer detail. FFE's roots in the Fourier transform, make it susceptible to aliasing if pushed too far, while MPEs, which use a learned grid structure, have no such limitation. To understand the difference in performance, we use the neural tangent kernel (NTK) to evaluate these encodings through the lens of an analogous kernel regression. By finding a lower bound on the smallest eigenvalue of the NTK, we prove that MPEs improve a network's performance through the structure of their grid and not their learnable embedding. This mechanism is fundamentally different from FFEs, which rely solely on their embedding space to improve performance. Results are empirically validated on a 2D image regression task using images taken from 100 synonym sets of ImageNet and 3D implicit surface regression on objects from the Stanford graphics dataset. Using peak signal-to-noise ratio (PSNR) and multiscale structural similarity (MS-SSIM) to evaluate how well fine details are learned, we show that the MPE increases the minimum eigenvalue by 8 orders of magnitude over the baseline and 2 orders of magnitude over the FFE. The increase in spectrum corresponds to a 15 dB (PSNR) / 0.65 (MS-SSIM) increase over baseline and a 12 dB (PSNR) / 0.33 (MS-SSIM) increase over the FFE.
SketchSplat: 3D Edge Reconstruction via Differentiable Multi-view Sketch Splatting
Mar 18, 2025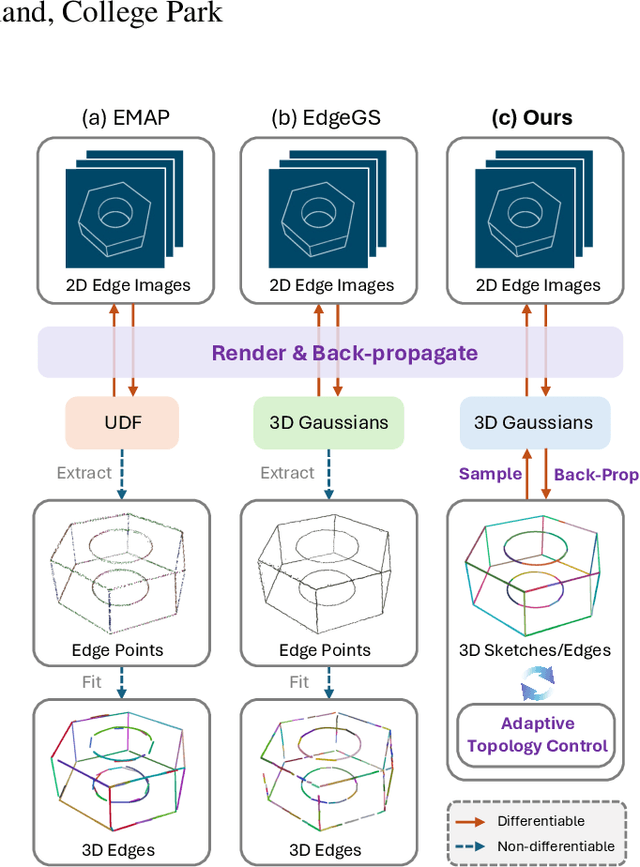
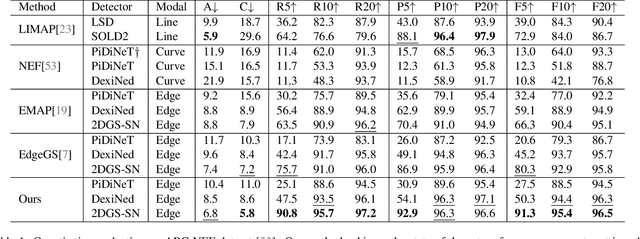
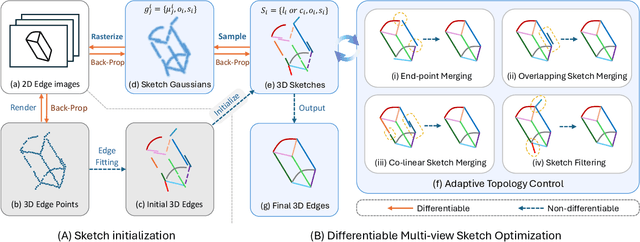
Edges are one of the most basic parametric primitives to describe structural information in 3D. In this paper, we study parametric 3D edge reconstruction from calibrated multi-view images. Previous methods usually reconstruct a 3D edge point set from multi-view 2D edge images, and then fit 3D edges to the point set. However, noise in the point set may cause gaps among fitted edges, and the recovered edges may not align with input multi-view images since the edge fitting depends only on the reconstructed 3D point set. To mitigate these problems, we propose SketchSplat, a method to reconstruct accurate, complete, and compact 3D edges via differentiable multi-view sketch splatting. We represent 3D edges as sketches, which are parametric lines and curves defined by attributes including control points, scales, and opacity. During edge reconstruction, we iteratively sample Gaussian points from a set of sketches and rasterize the Gaussians onto 2D edge images. Then the gradient of the image error with respect to the input 2D edge images can be back-propagated to optimize the sketch attributes. Our method bridges 2D edge images and 3D edges in a differentiable manner, which ensures that 3D edges align well with 2D images and leads to accurate and complete results. We also propose a series of adaptive topological operations and apply them along with the sketch optimization. The topological operations help reduce the number of sketches required while ensuring high accuracy, yielding a more compact reconstruction. Finally, we contribute an accurate 2D edge detector that improves the performance of both ours and existing methods. Experiments show that our method achieves state-of-the-art accuracy, completeness, and compactness on a benchmark CAD dataset.
Generative Detail Enhancement for Physically Based Materials
Feb 19, 2025We present a tool for enhancing the detail of physically based materials using an off-the-shelf diffusion model and inverse rendering. Our goal is to enhance the visual fidelity of materials with detail that is often tedious to author, by adding signs of wear, aging, weathering, etc. As these appearance details are often rooted in real-world processes, we leverage a generative image model trained on a large dataset of natural images with corresponding visuals in context. Starting with a given geometry, UV mapping, and basic appearance, we render multiple views of the object. We use these views, together with an appearance-defining text prompt, to condition a diffusion model. The details it generates are then backpropagated from the enhanced images to the material parameters via inverse differentiable rendering. For inverse rendering to be successful, the generated appearance has to be consistent across all the images. We propose two priors to address the multi-view consistency of the diffusion model. First, we ensure that the initial noise that seeds the diffusion process is itself consistent across views by integrating it from a view-independent UV space. Second, we enforce geometric consistency by biasing the attention mechanism via a projective constraint so that pixels attend strongly to their corresponding pixel locations in other views. Our approach does not require any training or finetuning of the diffusion model, is agnostic of the material model used, and the enhanced material properties, i.e., 2D PBR textures, can be further edited by artists.
Speedy-Splat: Fast 3D Gaussian Splatting with Sparse Pixels and Sparse Primitives
Nov 30, 20243D Gaussian Splatting (3D-GS) is a recent 3D scene reconstruction technique that enables real-time rendering of novel views by modeling scenes as parametric point clouds of differentiable 3D Gaussians. However, its rendering speed and model size still present bottlenecks, especially in resource-constrained settings. In this paper, we identify and address two key inefficiencies in 3D-GS, achieving substantial improvements in rendering speed, model size, and training time. First, we optimize the rendering pipeline to precisely localize Gaussians in the scene, boosting rendering speed without altering visual fidelity. Second, we introduce a novel pruning technique and integrate it into the training pipeline, significantly reducing model size and training time while further raising rendering speed. Our Speedy-Splat approach combines these techniques to accelerate average rendering speed by a drastic $6.71\times$ across scenes from the Mip-NeRF 360, Tanks & Temples, and Deep Blending datasets with $10.6\times$ fewer primitives than 3D-GS.
NARVis: Neural Accelerated Rendering for Real-Time Scientific Point Cloud Visualization
Jul 26, 2024Exploring scientific datasets with billions of samples in real-time visualization presents a challenge - balancing high-fidelity rendering with speed. This work introduces a novel renderer - Neural Accelerated Renderer (NAR), that uses the neural deferred rendering framework to visualize large-scale scientific point cloud data. NAR augments a real-time point cloud rendering pipeline with high-quality neural post-processing, making the approach ideal for interactive visualization at scale. Specifically, we train a neural network to learn the point cloud geometry from a high-performance multi-stream rasterizer and capture the desired postprocessing effects from a conventional high-quality renderer. We demonstrate the effectiveness of NAR by visualizing complex multidimensional Lagrangian flow fields and photometric scans of a large terrain and compare the renderings against the state-of-the-art high-quality renderers. Through extensive evaluation, we demonstrate that NAR prioritizes speed and scalability while retaining high visual fidelity. We achieve competitive frame rates of $>$ 126 fps for interactive rendering of $>$ 350M points (i.e., an effective throughput of $>$ 44 billion points per second) using $\sim$12 GB of memory on RTX 2080 Ti GPU. Furthermore, we show that NAR is generalizable across different point clouds with similar visualization needs and the desired post-processing effects could be obtained with substantial high quality even at lower resolutions of the original point cloud, further reducing the memory requirements.