 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNARVis: Neural Accelerated Rendering for Real-Time Scientific Point Cloud Visualization
Jul 26, 2024Exploring scientific datasets with billions of samples in real-time visualization presents a challenge - balancing high-fidelity rendering with speed. This work introduces a novel renderer - Neural Accelerated Renderer (NAR), that uses the neural deferred rendering framework to visualize large-scale scientific point cloud data. NAR augments a real-time point cloud rendering pipeline with high-quality neural post-processing, making the approach ideal for interactive visualization at scale. Specifically, we train a neural network to learn the point cloud geometry from a high-performance multi-stream rasterizer and capture the desired postprocessing effects from a conventional high-quality renderer. We demonstrate the effectiveness of NAR by visualizing complex multidimensional Lagrangian flow fields and photometric scans of a large terrain and compare the renderings against the state-of-the-art high-quality renderers. Through extensive evaluation, we demonstrate that NAR prioritizes speed and scalability while retaining high visual fidelity. We achieve competitive frame rates of $>$ 126 fps for interactive rendering of $>$ 350M points (i.e., an effective throughput of $>$ 44 billion points per second) using $\sim$12 GB of memory on RTX 2080 Ti GPU. Furthermore, we show that NAR is generalizable across different point clouds with similar visualization needs and the desired post-processing effects could be obtained with substantial high quality even at lower resolutions of the original point cloud, further reducing the memory requirements.
Diffusion Models Beat GANs on Image Classification
Jul 17, 2023



While many unsupervised learning models focus on one family of tasks, either generative or discriminative, we explore the possibility of a unified representation learner: a model which uses a single pre-training stage to address both families of tasks simultaneously. We identify diffusion models as a prime candidate. Diffusion models have risen to prominence as a state-of-the-art method for image generation, denoising, inpainting, super-resolution, manipulation, etc. Such models involve training a U-Net to iteratively predict and remove noise, and the resulting model can synthesize high fidelity, diverse, novel images. The U-Net architecture, as a convolution-based architecture, generates a diverse set of feature representations in the form of intermediate feature maps. We present our findings that these embeddings are useful beyond the noise prediction task, as they contain discriminative information and can also be leveraged for classification. We explore optimal methods for extracting and using these embeddings for classification tasks, demonstrating promising results on the ImageNet classification task. We find that with careful feature selection and pooling, diffusion models outperform comparable generative-discriminative methods such as BigBiGAN for classification tasks. We investigate diffusion models in the transfer learning regime, examining their performance on several fine-grained visual classification datasets. We compare these embeddings to those generated by competing architectures and pre-trainings for classification tasks.
Rethinking Common Assumptions to Mitigate Racial Bias in Face Recognition Datasets
Sep 08, 2021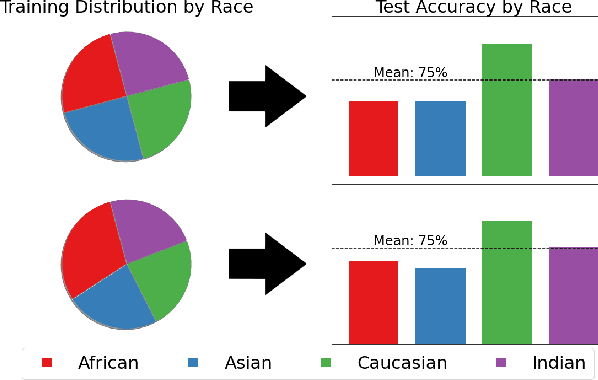
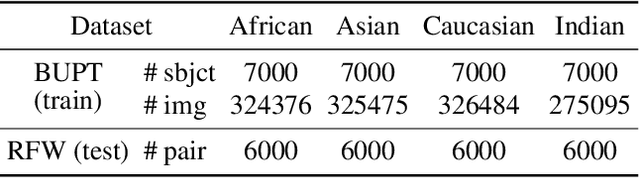
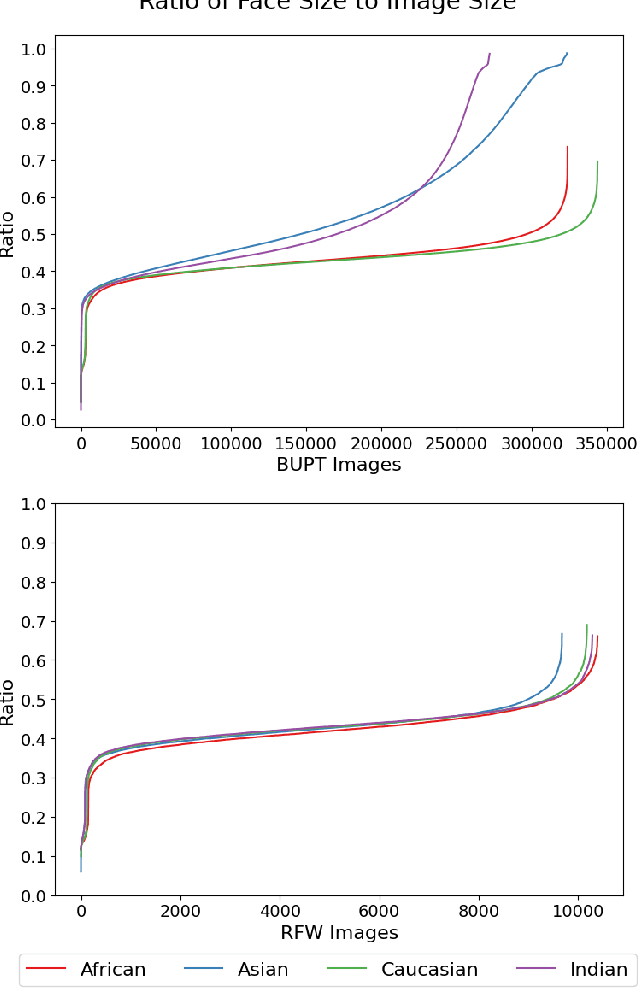
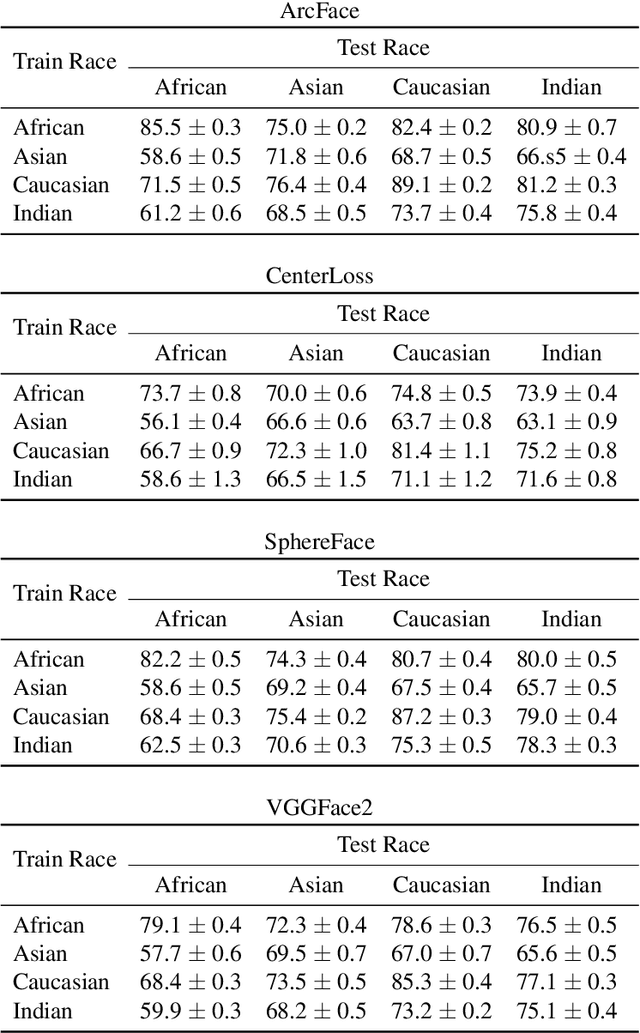
Many existing works have made great strides towards reducing racial bias in face recognition. However, most of these methods attempt to rectify bias that manifests in models during training instead of directly addressing a major source of the bias, the dataset itself. Exceptions to this are BUPT-Balancedface/RFW and Fairface, but these works assume that primarily training on a single race or not racially balancing the dataset are inherently disadvantageous. We demonstrate that these assumptions are not necessarily valid. In our experiments, training on only African faces induced less bias than training on a balanced distribution of faces and distributions skewed to include more African faces produced more equitable models. We additionally notice that adding more images of existing identities to a dataset in place of adding new identities can lead to accuracy boosts across racial categories. Our code is available at https://github.com/j-alex-hanson/rethinking-race-face-datasets.
Variational Student: Learning Compact and Sparser Networks in Knowledge Distillation Framework
Oct 26, 2019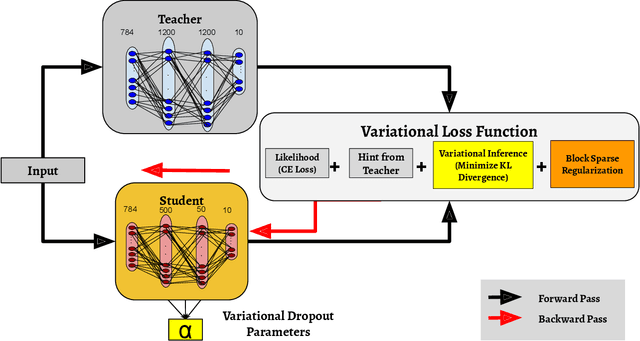
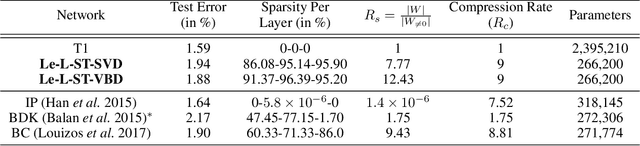
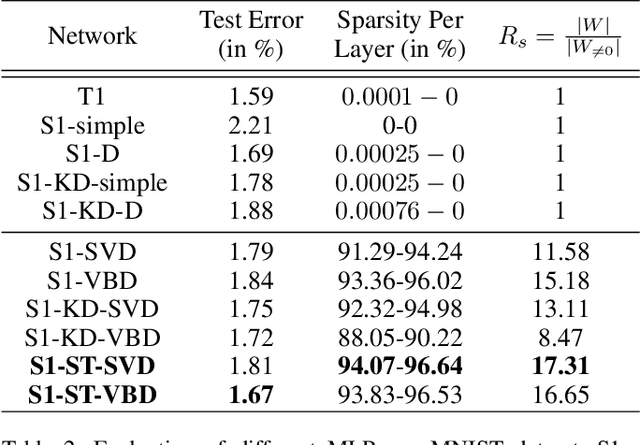
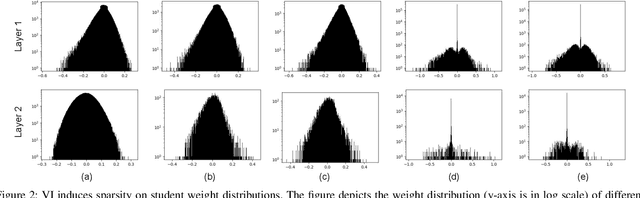
The holy grail in deep neural network research is porting the memory- and computation-intensive network models on embedded platforms with a minimal compromise in model accuracy. To this end, we propose a novel approach, termed as Variational Student, where we reap the benefits of compressibility of the knowledge distillation (KD) framework, and sparsity inducing abilities of variational inference (VI) techniques. Essentially, we build a sparse student network, whose sparsity is induced by the variational parameters found via optimizing a loss function based on VI, leveraging the knowledge learnt by an accurate but complex pre-trained teacher network. Further, for sparsity enhancement, we also employ a Block Sparse Regularizer on a concatenated tensor of teacher and student network weights. We demonstrate that the marriage of KD and the VI techniques inherits compression properties from the KD framework, and enhances levels of sparsity from the VI approach, with minimal compromise in the model accuracy. We benchmark our results on LeNet MLP and VGGNet (CNN) and illustrate a memory footprint reduction of 64x and 213x on these MLP and CNN variants, respectively, without a need to retrain the teacher network. Furthermore, in the low data regime, we observed that our method outperforms state-of-the-art Bayesian techniques in terms of accuracy.