 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory-aligned Space-time Tokens for Few-shot Action Recognition
Jul 25, 2024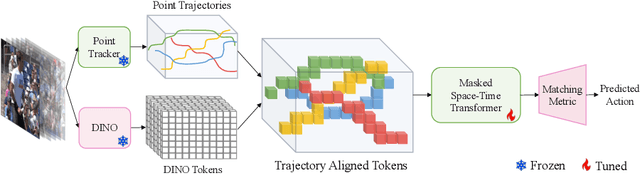
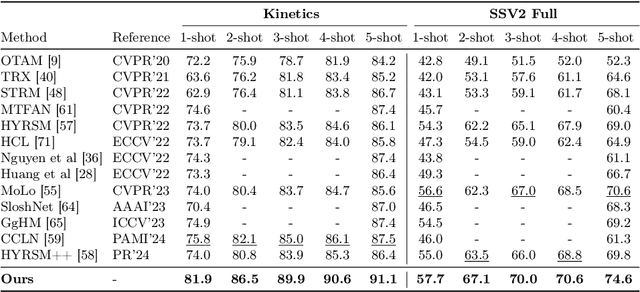
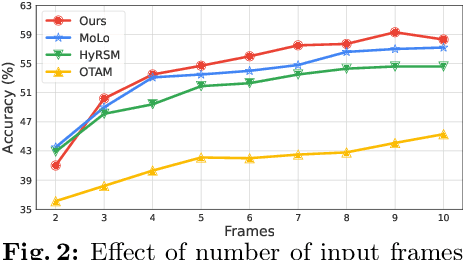
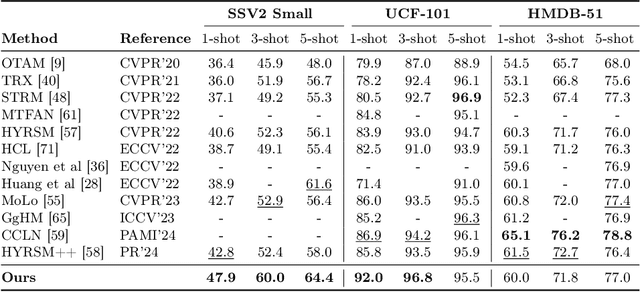
We propose a simple yet effective approach for few-shot action recognition, emphasizing the disentanglement of motion and appearance representations. By harnessing recent progress in tracking, specifically point trajectories and self-supervised representation learning, we build trajectory-aligned tokens (TATs) that capture motion and appearance information. This approach significantly reduces the data requirements while retaining essential information. To process these representations, we use a Masked Space-time Transformer that effectively learns to aggregate information to facilitate few-shot action recognition. We demonstrate state-of-the-art results on few-shot action recognition across multiple datasets. Our project page is available at https://www.cs.umd.edu/~pulkit/tats
Explaining the Implicit Neural Canvas: Connecting Pixels to Neurons by Tracing their Contributions
Jan 18, 2024The many variations of Implicit Neural Representations (INRs), where a neural network is trained as a continuous representation of a signal, have tremendous practical utility for downstream tasks including novel view synthesis, video compression, and image superresolution. Unfortunately, the inner workings of these networks are seriously under-studied. Our work, eXplaining the Implicit Neural Canvas (XINC), is a unified framework for explaining properties of INRs by examining the strength of each neuron's contribution to each output pixel. We call the aggregate of these contribution maps the Implicit Neural Canvas and we use this concept to demonstrate that the INRs which we study learn to ''see'' the frames they represent in surprising ways. For example, INRs tend to have highly distributed representations. While lacking high-level object semantics, they have a significant bias for color and edges, and are almost entirely space-agnostic. We arrive at our conclusions by examining how objects are represented across time in video INRs, using clustering to visualize similar neurons across layers and architectures, and show that this is dominated by motion. These insights demonstrate the general usefulness of our analysis framework. Our project page is available at https://namithap10.github.io/xinc.
Do text-free diffusion models learn discriminative visual representations?
Nov 30, 2023



While many unsupervised learning models focus on one family of tasks, either generative or discriminative, we explore the possibility of a unified representation learner: a model which addresses both families of tasks simultaneously. We identify diffusion models, a state-of-the-art method for generative tasks, as a prime candidate. Such models involve training a U-Net to iteratively predict and remove noise, and the resulting model can synthesize high-fidelity, diverse, novel images. We find that the intermediate feature maps of the U-Net are diverse, discriminative feature representations. We propose a novel attention mechanism for pooling feature maps and further leverage this mechanism as DifFormer, a transformer feature fusion of features from different diffusion U-Net blocks and noise steps. We also develop DifFeed, a novel feedback mechanism tailored to diffusion. We find that diffusion models are better than GANs, and, with our fusion and feedback mechanisms, can compete with state-of-the-art unsupervised image representation learning methods for discriminative tasks - image classification with full and semi-supervision, transfer for fine-grained classification, object detection and segmentation, and semantic segmentation. Our project website (https://mgwillia.github.io/diffssl/) and code (https://github.com/soumik-kanad/diffssl) are available publicly.
Diffusion Models Beat GANs on Image Classification
Jul 17, 2023



While many unsupervised learning models focus on one family of tasks, either generative or discriminative, we explore the possibility of a unified representation learner: a model which uses a single pre-training stage to address both families of tasks simultaneously. We identify diffusion models as a prime candidate. Diffusion models have risen to prominence as a state-of-the-art method for image generation, denoising, inpainting, super-resolution, manipulation, etc. Such models involve training a U-Net to iteratively predict and remove noise, and the resulting model can synthesize high fidelity, diverse, novel images. The U-Net architecture, as a convolution-based architecture, generates a diverse set of feature representations in the form of intermediate feature maps. We present our findings that these embeddings are useful beyond the noise prediction task, as they contain discriminative information and can also be leveraged for classification. We explore optimal methods for extracting and using these embeddings for classification tasks, demonstrating promising results on the ImageNet classification task. We find that with careful feature selection and pooling, diffusion models outperform comparable generative-discriminative methods such as BigBiGAN for classification tasks. We investigate diffusion models in the transfer learning regime, examining their performance on several fine-grained visual classification datasets. We compare these embeddings to those generated by competing architectures and pre-trainings for classification tasks.
Leveraging Bitstream Metadata for Fast and Accurate Video Compression Correction
Jan 31, 2022Video compression is a central feature of the modern internet powering technologies from social media to video conferencing. While video compression continues to mature, for many, and particularly for extreme, compression settings, quality loss is still noticeable. These extreme settings nevertheless have important applications to the efficient transmission of videos over bandwidth constrained or otherwise unstable connections. In this work, we develop a deep learning architecture capable of restoring detail to compressed videos which leverages the underlying structure and motion information embedded in the video bitstream. We show that this improves restoration accuracy compared to prior compression correction methods and is competitive when compared with recent deep-learning-based video compression methods on rate-distortion while achieving higher throughput.