 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent-INR: A Flexible Framework for Implicit Representations of Videos with Discriminative Semantics
Aug 05, 2024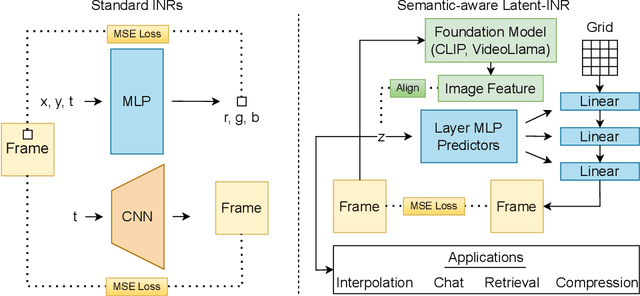
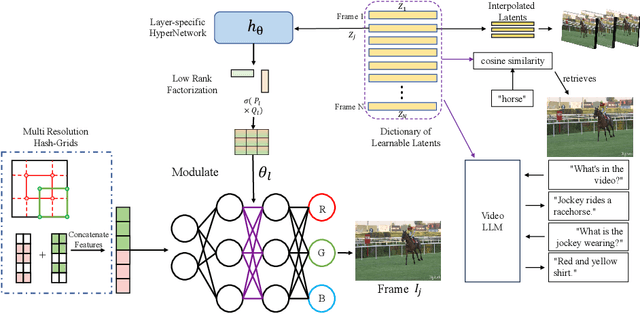
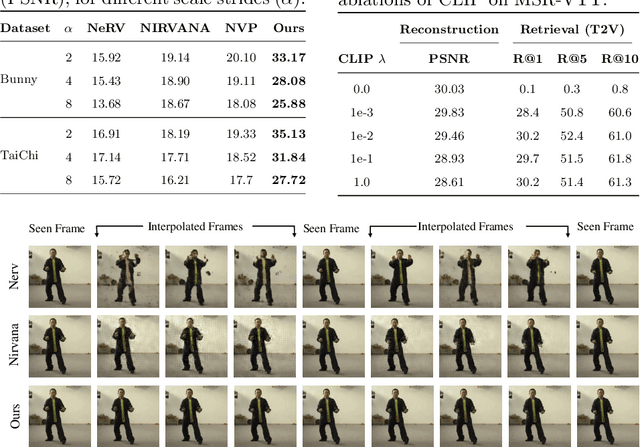
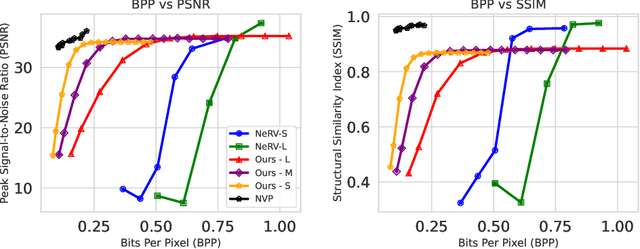
Implicit Neural Networks (INRs) have emerged as powerful representations to encode all forms of data, including images, videos, audios, and scenes. With video, many INRs for video have been proposed for the compression task, and recent methods feature significant improvements with respect to encoding time, storage, and reconstruction quality. However, these encoded representations lack semantic meaning, so they cannot be used for any downstream tasks that require such properties, such as retrieval. This can act as a barrier for adoption of video INRs over traditional codecs as they do not offer any significant edge apart from compression. To alleviate this, we propose a flexible framework that decouples the spatial and temporal aspects of the video INR. We accomplish this with a dictionary of per-frame latents that are learned jointly with a set of video specific hypernetworks, such that given a latent, these hypernetworks can predict the INR weights to reconstruct the given frame. This framework not only retains the compression efficiency, but the learned latents can be aligned with features from large vision models, which grants them discriminative properties. We align these latents with CLIP and show good performance for both compression and video retrieval tasks. By aligning with VideoLlama, we are able to perform open-ended chat with our learned latents as the visual inputs. Additionally, the learned latents serve as a proxy for the underlying weights, allowing us perform tasks like video interpolation. These semantic properties and applications, existing simultaneously with ability to perform compression, interpolation, and superresolution properties, are a first in this field of work.
Explaining the Implicit Neural Canvas: Connecting Pixels to Neurons by Tracing their Contributions
Jan 18, 2024The many variations of Implicit Neural Representations (INRs), where a neural network is trained as a continuous representation of a signal, have tremendous practical utility for downstream tasks including novel view synthesis, video compression, and image superresolution. Unfortunately, the inner workings of these networks are seriously under-studied. Our work, eXplaining the Implicit Neural Canvas (XINC), is a unified framework for explaining properties of INRs by examining the strength of each neuron's contribution to each output pixel. We call the aggregate of these contribution maps the Implicit Neural Canvas and we use this concept to demonstrate that the INRs which we study learn to ''see'' the frames they represent in surprising ways. For example, INRs tend to have highly distributed representations. While lacking high-level object semantics, they have a significant bias for color and edges, and are almost entirely space-agnostic. We arrive at our conclusions by examining how objects are represented across time in video INRs, using clustering to visualize similar neurons across layers and architectures, and show that this is dominated by motion. These insights demonstrate the general usefulness of our analysis framework. Our project page is available at https://namithap10.github.io/xinc.
NIRVANA: Neural Implicit Representations of Videos with Adaptive Networks and Autoregressive Patch-wise Modeling
Dec 30, 2022Implicit Neural Representations (INR) have recently shown to be powerful tool for high-quality video compression. However, existing works are limiting as they do not explicitly exploit the temporal redundancy in videos, leading to a long encoding time. Additionally, these methods have fixed architectures which do not scale to longer videos or higher resolutions. To address these issues, we propose NIRVANA, which treats videos as groups of frames and fits separate networks to each group performing patch-wise prediction. This design shares computation within each group, in the spatial and temporal dimensions, resulting in reduced encoding time of the video. The video representation is modeled autoregressively, with networks fit on a current group initialized using weights from the previous group's model. To further enhance efficiency, we perform quantization of the network parameters during training, requiring no post-hoc pruning or quantization. When compared with previous works on the benchmark UVG dataset, NIRVANA improves encoding quality from 37.36 to 37.70 (in terms of PSNR) and the encoding speed by 12X, while maintaining the same compression rate. In contrast to prior video INR works which struggle with larger resolution and longer videos, we show that our algorithm is highly flexible and scales naturally due to its patch-wise and autoregressive designs. Moreover, our method achieves variable bitrate compression by adapting to videos with varying inter-frame motion. NIRVANA achieves 6X decoding speed and scales well with more GPUs, making it practical for various deployment scenarios.
A Frequency Perspective of Adversarial Robustness
Oct 26, 2021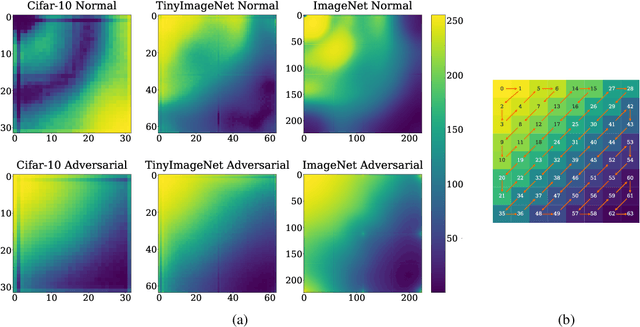
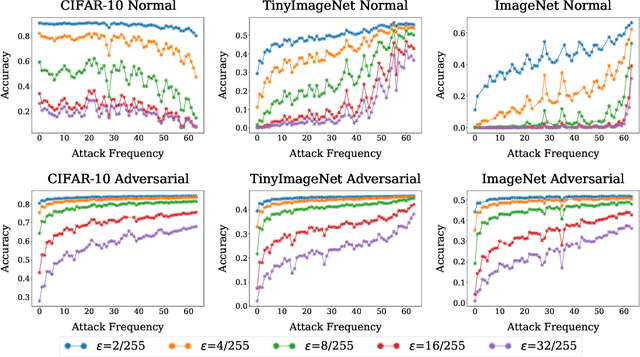

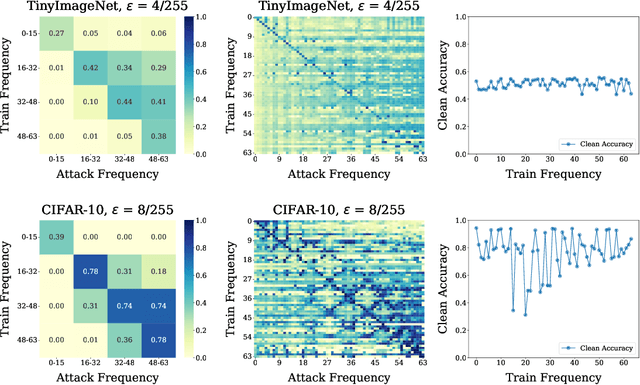
Adversarial examples pose a unique challenge for deep learning systems. Despite recent advances in both attacks and defenses, there is still a lack of clarity and consensus in the community about the true nature and underlying properties of adversarial examples. A deep understanding of these examples can provide new insights towards the development of more effective attacks and defenses. Driven by the common misconception that adversarial examples are high-frequency noise, we present a frequency-based understanding of adversarial examples, supported by theoretical and empirical findings. Our analysis shows that adversarial examples are neither in high-frequency nor in low-frequency components, but are simply dataset dependent. Particularly, we highlight the glaring disparities between models trained on CIFAR-10 and ImageNet-derived datasets. Utilizing this framework, we analyze many intriguing properties of training robust models with frequency constraints, and propose a frequency-based explanation for the commonly observed accuracy vs. robustness trade-off.
Membership Inference Attacks on Lottery Ticket Networks
Aug 07, 2021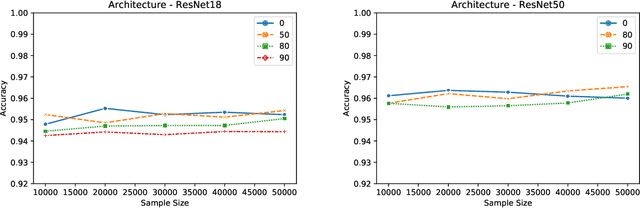
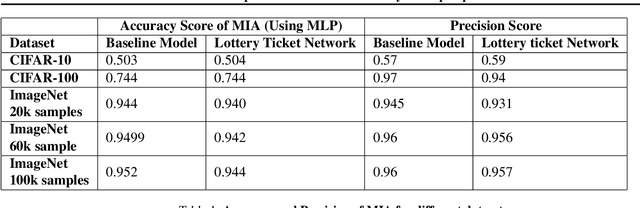
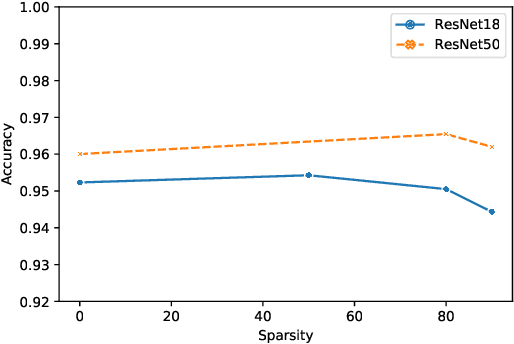
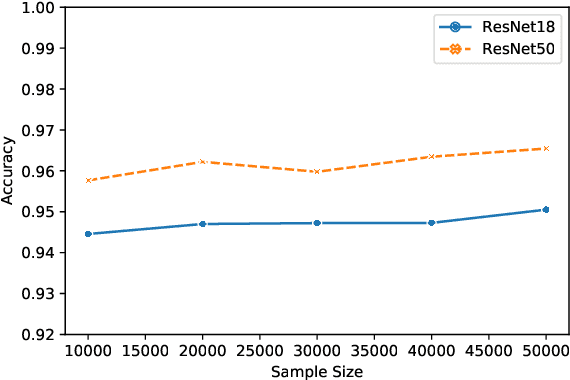
The vulnerability of the Lottery Ticket Hypothesis has not been studied from the purview of Membership Inference Attacks. Through this work, we are the first to empirically show that the lottery ticket networks are equally vulnerable to membership inference attacks. A Membership Inference Attack (MIA) is the process of determining whether a data sample belongs to a training set of a trained model or not. Membership Inference Attacks could leak critical information about the training data that can be used for targeted attacks. Recent deep learning models often have very large memory footprints and a high computational cost associated with training and drawing inferences. Lottery Ticket Hypothesis is used to prune the networks to find smaller sub-networks that at least match the performance of the original model in terms of test accuracy in a similar number of iterations. We used CIFAR-10, CIFAR-100, and ImageNet datasets to perform image classification tasks and observe that the attack accuracies are similar. We also see that the attack accuracy varies directly according to the number of classes in the dataset and the sparsity of the network. We demonstrate that these attacks are transferable across models with high accuracy.
Relation Networks for Optic Disc and Fovea Localization in Retinal Images
Nov 23, 2018

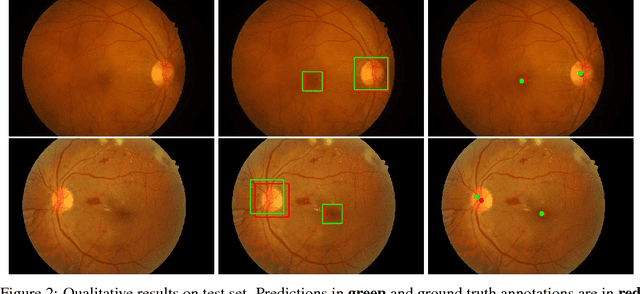
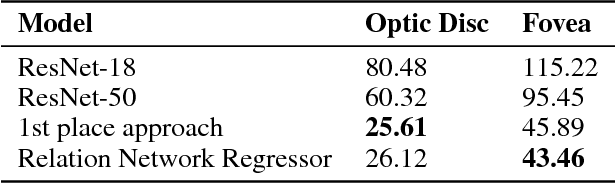
Diabetic Retinopathy is the leading cause of blindness in the world. At least 90\% of new cases can be reduced with proper treatment and monitoring of the eyes. However, scanning the entire population of patients is a difficult endeavor. Computer-aided diagnosis tools in retinal image analysis can make the process scalable and efficient. In this work, we focus on the problem of localizing the centers of the Optic disc and Fovea, a task crucial to the analysis of retinal scans. Current systems recognize the Optic disc and Fovea individually, without exploiting their relations during learning. We propose a novel approach to localizing the centers of the Optic disc and Fovea by simultaneously processing them and modeling their relative geometry and appearance. We show that our approach improves localization and recognition by incorporating object-object relations efficiently, and achieves highly competitive results.
Slum Segmentation and Change Detection : A Deep Learning Approach
Nov 19, 2018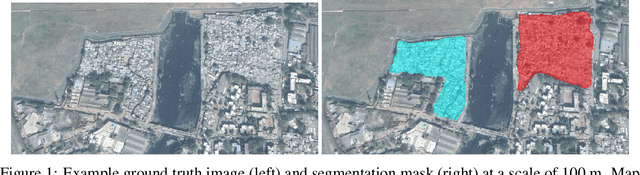
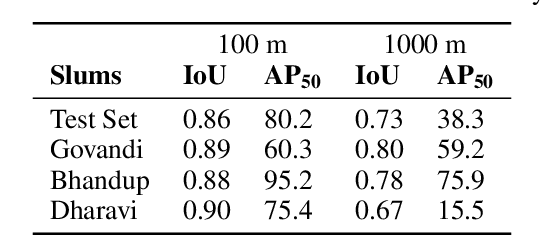
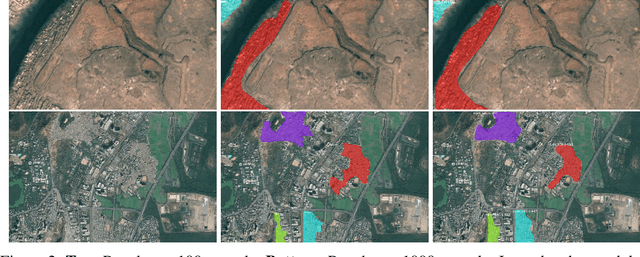

More than one billion people live in slums around the world. In some developing countries, slum residents make up for more than half of the population and lack reliable sanitation services, clean water, electricity, other basic services. Thus, slum rehabilitation and improvement is an important global challenge, and a significant amount of effort and resources have been put into this endeavor. These initiatives rely heavily on slum mapping and monitoring, and it is essential to have robust and efficient methods for mapping and monitoring existing slum settlements. In this work, we introduce an approach to segment and map individual slums from satellite imagery, leveraging regional convolutional neural networks for instance segmentation using transfer learning. In addition, we also introduce a method to perform change detection and monitor slum change over time. We show that our approach effectively learns slum shape and appearance, and demonstrates strong quantitative results, resulting in a maximum AP of 80.0.