 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCineOrchestra: Unified Entity-Centric Conditioning for Cinematic Video Generation
Jun 11, 2026Cinematic video depicts multiple subjects acting or interacting at specific moments, captured with deliberate camera movement, and stitched together by shot transitions. Together, these elements demand a level of fine-grained control beyond current text-to-video models. Existing work addresses each axis in isolation: multi-subject personalization, temporal control, multi-shot synthesis, or camera control; no prior framework jointly integrates all four. We present CineOrchestra, a unified video diffusion model that controls subjects, events, cameras, and shot transitions simultaneously. Our key insight is that these heterogeneous cinematic elements share a fundamental structure: each is an entity acting over a specific temporal interval, which can therefore all be expressed through one shared structure of entity-centric conditioning primitives, augmented with reference images for visual entities. This formulation reduces the architectural challenge to a single positional encoding problem, which we solve with two parameter-free coordinated rotary embeddings: (a) an interval-sampled temporal RoPE that yields consistent attention behavior across events of dramatically varying duration, and (b) a 2D entity-temporal cross-attention RoPE that disambiguates per-entity conditions and routes each to its corresponding spatiotemporal region. On two new benchmarks, CineOrchestra outperforms six per-axis specialists on dense caption following and shot-transition timing, with consistent gains in a pairwise user study and component ablations.
AlcheMinT: Fine-grained Temporal Control for Multi-Reference Consistent Video Generation
Dec 11, 2025Recent advances in subject-driven video generation with large diffusion models have enabled personalized content synthesis conditioned on user-provided subjects. However, existing methods lack fine-grained temporal control over subject appearance and disappearance, which are essential for applications such as compositional video synthesis, storyboarding, and controllable animation. We propose AlcheMinT, a unified framework that introduces explicit timestamps conditioning for subject-driven video generation. Our approach introduces a novel positional encoding mechanism that unlocks the encoding of temporal intervals, associated in our case with subject identities, while seamlessly integrating with the pretrained video generation model positional embeddings. Additionally, we incorporate subject-descriptive text tokens to strengthen binding between visual identity and video captions, mitigating ambiguity during generation. Through token-wise concatenation, AlcheMinT avoids any additional cross-attention modules and incurs negligible parameter overhead. We establish a benchmark evaluating multiple subject identity preservation, video fidelity, and temporal adherence. Experimental results demonstrate that AlcheMinT achieves visual quality matching state-of-the-art video personalization methods, while, for the first time, enabling precise temporal control over multi-subject generation within videos. Project page is at https://snap-research.github.io/Video-AlcheMinT
OmniView: An All-Seeing Diffusion Model for 3D and 4D View Synthesis
Dec 11, 2025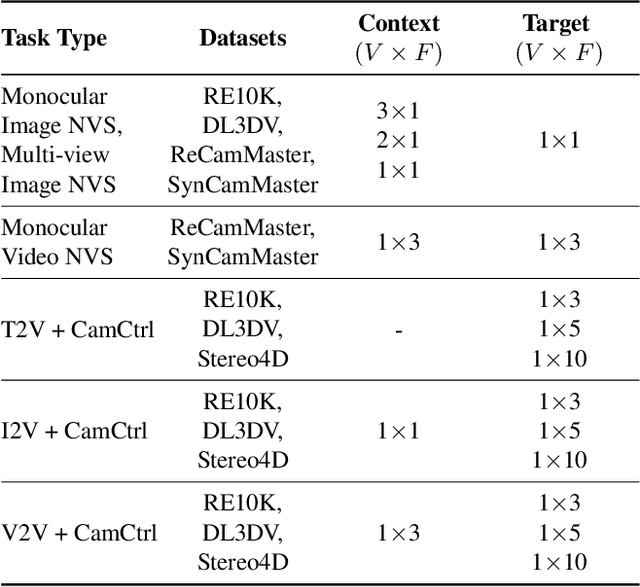
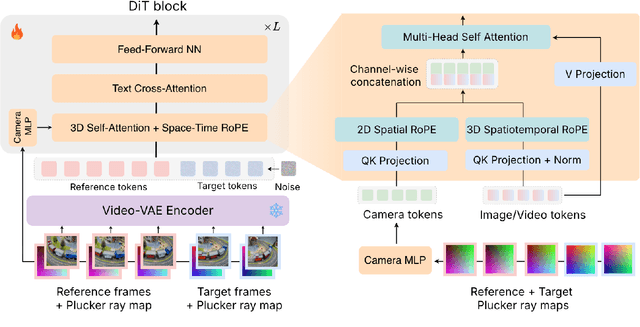
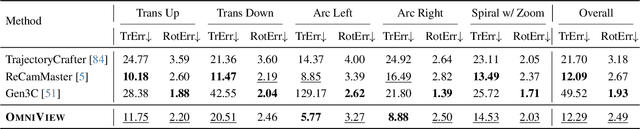

Prior approaches injecting camera control into diffusion models have focused on specific subsets of 4D consistency tasks: novel view synthesis, text-to-video with camera control, image-to-video, amongst others. Therefore, these fragmented approaches are trained on disjoint slices of available 3D/4D data. We introduce OmniView, a unified framework that generalizes across a wide range of 4D consistency tasks. Our method separately represents space, time, and view conditions, enabling flexible combinations of these inputs. For example, OmniView can synthesize novel views from static, dynamic, and multiview inputs, extrapolate trajectories forward and backward in time, and create videos from text or image prompts with full camera control. OmniView is competitive with task-specific models across diverse benchmarks and metrics, improving image quality scores among camera-conditioned diffusion models by up to 33\% in multiview NVS LLFF dataset, 60\% in dynamic NVS Neural 3D Video benchmark, 20\% in static camera control on RE-10K, and reducing camera trajectory errors by 4x in text-conditioned video generation. With strong generalizability in one model, OmniView demonstrates the feasibility of a generalist 4D video model. Project page is available at https://snap-research.github.io/OmniView/
H3AE: High Compression, High Speed, and High Quality AutoEncoder for Video Diffusion Models
Apr 14, 2025Autoencoder (AE) is the key to the success of latent diffusion models for image and video generation, reducing the denoising resolution and improving efficiency. However, the power of AE has long been underexplored in terms of network design, compression ratio, and training strategy. In this work, we systematically examine the architecture design choices and optimize the computation distribution to obtain a series of efficient and high-compression video AEs that can decode in real time on mobile devices. We also unify the design of plain Autoencoder and image-conditioned I2V VAE, achieving multifunctionality in a single network. In addition, we find that the widely adopted discriminative losses, i.e., GAN, LPIPS, and DWT losses, provide no significant improvements when training AEs at scale. We propose a novel latent consistency loss that does not require complicated discriminator design or hyperparameter tuning, but provides stable improvements in reconstruction quality. Our AE achieves an ultra-high compression ratio and real-time decoding speed on mobile while outperforming prior art in terms of reconstruction metrics by a large margin. We finally validate our AE by training a DiT on its latent space and demonstrate fast, high-quality text-to-video generation capability.
Improving the Diffusability of Autoencoders
Feb 20, 2025Latent diffusion models have emerged as the leading approach for generating high-quality images and videos, utilizing compressed latent representations to reduce the computational burden of the diffusion process. While recent advancements have primarily focused on scaling diffusion backbones and improving autoencoder reconstruction quality, the interaction between these components has received comparatively less attention. In this work, we perform a spectral analysis of modern autoencoders and identify inordinate high-frequency components in their latent spaces, which are especially pronounced in the autoencoders with a large bottleneck channel size. We hypothesize that this high-frequency component interferes with the coarse-to-fine nature of the diffusion synthesis process and hinders the generation quality. To mitigate the issue, we propose scale equivariance: a simple regularization strategy that aligns latent and RGB spaces across frequencies by enforcing scale equivariance in the decoder. It requires minimal code changes and only up to 20K autoencoder fine-tuning steps, yet significantly improves generation quality, reducing FID by 19% for image generation on ImageNet-1K 256x256 and FVD by at least 44% for video generation on Kinetics-700 17x256x256.
QUEEN: QUantized Efficient ENcoding of Dynamic Gaussians for Streaming Free-viewpoint Videos
Dec 05, 2024
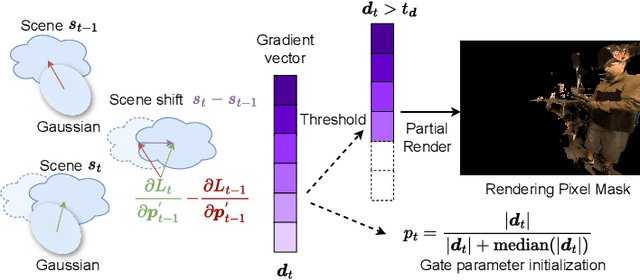


Online free-viewpoint video (FVV) streaming is a challenging problem, which is relatively under-explored. It requires incremental on-the-fly updates to a volumetric representation, fast training and rendering to satisfy real-time constraints and a small memory footprint for efficient transmission. If achieved, it can enhance user experience by enabling novel applications, e.g., 3D video conferencing and live volumetric video broadcast, among others. In this work, we propose a novel framework for QUantized and Efficient ENcoding (QUEEN) for streaming FVV using 3D Gaussian Splatting (3D-GS). QUEEN directly learns Gaussian attribute residuals between consecutive frames at each time-step without imposing any structural constraints on them, allowing for high quality reconstruction and generalizability. To efficiently store the residuals, we further propose a quantization-sparsity framework, which contains a learned latent-decoder for effectively quantizing attribute residuals other than Gaussian positions and a learned gating module to sparsify position residuals. We propose to use the Gaussian viewspace gradient difference vector as a signal to separate the static and dynamic content of the scene. It acts as a guide for effective sparsity learning and speeds up training. On diverse FVV benchmarks, QUEEN outperforms the state-of-the-art online FVV methods on all metrics. Notably, for several highly dynamic scenes, it reduces the model size to just 0.7 MB per frame while training in under 5 sec and rendering at 350 FPS. Project website is at https://research.nvidia.com/labs/amri/projects/queen
EAGLES: Efficient Accelerated 3D Gaussians with Lightweight EncodingS
Dec 07, 2023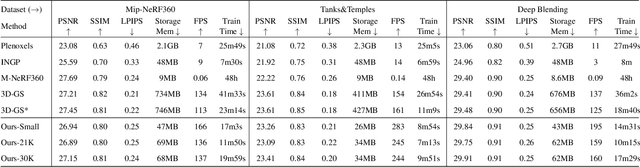
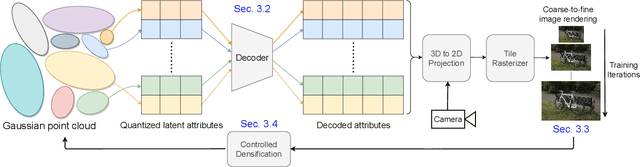
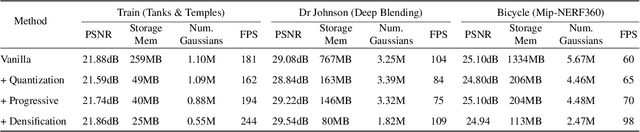
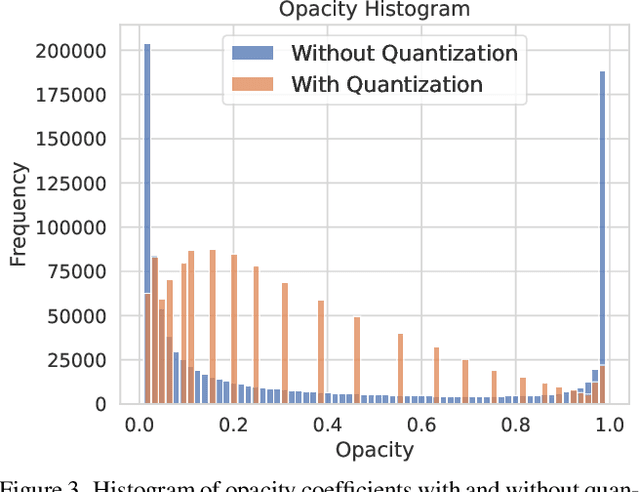
Recently, 3D Gaussian splatting (3D-GS) has gained popularity in novel-view scene synthesis. It addresses the challenges of lengthy training times and slow rendering speeds associated with Neural Radiance Fields (NeRFs). Through rapid, differentiable rasterization of 3D Gaussians, 3D-GS achieves real-time rendering and accelerated training. They, however, demand substantial memory resources for both training and storage, as they require millions of Gaussians in their point cloud representation for each scene. We present a technique utilizing quantized embeddings to significantly reduce memory storage requirements and a coarse-to-fine training strategy for a faster and more stable optimization of the Gaussian point clouds. Our approach results in scene representations with fewer Gaussians and quantized representations, leading to faster training times and rendering speeds for real-time rendering of high resolution scenes. We reduce memory by more than an order of magnitude all while maintaining the reconstruction quality. We validate the effectiveness of our approach on a variety of datasets and scenes preserving the visual quality while consuming 10-20x less memory and faster training/inference speed. Project page and code is available https://efficientgaussian.github.io
SHACIRA: Scalable HAsh-grid Compression for Implicit Neural Representations
Sep 27, 2023



Implicit Neural Representations (INR) or neural fields have emerged as a popular framework to encode multimedia signals such as images and radiance fields while retaining high-quality. Recently, learnable feature grids proposed by Instant-NGP have allowed significant speed-up in the training as well as the sampling of INRs by replacing a large neural network with a multi-resolution look-up table of feature vectors and a much smaller neural network. However, these feature grids come at the expense of large memory consumption which can be a bottleneck for storage and streaming applications. In this work, we propose SHACIRA, a simple yet effective task-agnostic framework for compressing such feature grids with no additional post-hoc pruning/quantization stages. We reparameterize feature grids with quantized latent weights and apply entropy regularization in the latent space to achieve high levels of compression across various domains. Quantitative and qualitative results on diverse datasets consisting of images, videos, and radiance fields, show that our approach outperforms existing INR approaches without the need for any large datasets or domain-specific heuristics. Our project page is available at http://shacira.github.io .
NIRVANA: Neural Implicit Representations of Videos with Adaptive Networks and Autoregressive Patch-wise Modeling
Dec 30, 2022Implicit Neural Representations (INR) have recently shown to be powerful tool for high-quality video compression. However, existing works are limiting as they do not explicitly exploit the temporal redundancy in videos, leading to a long encoding time. Additionally, these methods have fixed architectures which do not scale to longer videos or higher resolutions. To address these issues, we propose NIRVANA, which treats videos as groups of frames and fits separate networks to each group performing patch-wise prediction. This design shares computation within each group, in the spatial and temporal dimensions, resulting in reduced encoding time of the video. The video representation is modeled autoregressively, with networks fit on a current group initialized using weights from the previous group's model. To further enhance efficiency, we perform quantization of the network parameters during training, requiring no post-hoc pruning or quantization. When compared with previous works on the benchmark UVG dataset, NIRVANA improves encoding quality from 37.36 to 37.70 (in terms of PSNR) and the encoding speed by 12X, while maintaining the same compression rate. In contrast to prior video INR works which struggle with larger resolution and longer videos, we show that our algorithm is highly flexible and scales naturally due to its patch-wise and autoregressive designs. Moreover, our method achieves variable bitrate compression by adapting to videos with varying inter-frame motion. NIRVANA achieves 6X decoding speed and scales well with more GPUs, making it practical for various deployment scenarios.
LilNetX: Lightweight Networks with EXtreme Model Compression and Structured Sparsification
Apr 06, 2022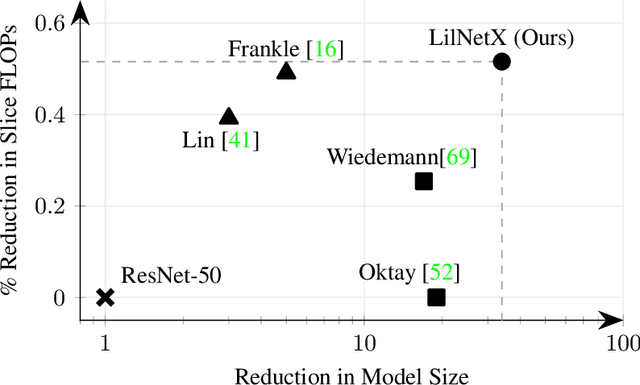
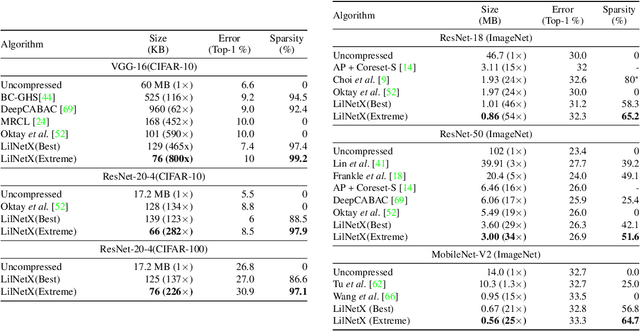
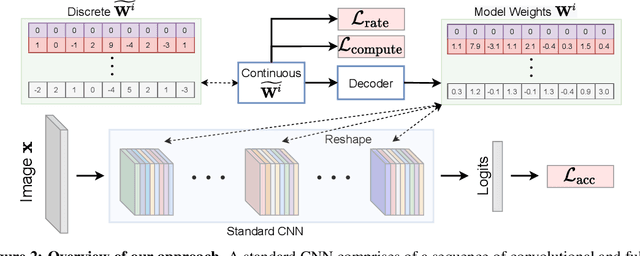

We introduce LilNetX, an end-to-end trainable technique for neural networks that enables learning models with specified accuracy-rate-computation trade-off. Prior works approach these problems one at a time and often require post-processing or multistage training which become less practical and do not scale very well for large datasets or architectures. Our method constructs a joint training objective that penalizes the self-information of network parameters in a reparameterized latent space to encourage small model size while also introducing priors to increase structured sparsity in the parameter space to reduce computation. We achieve up to 50% smaller model size and 98% model sparsity on ResNet-20 while retaining the same accuracy on the CIFAR-10 dataset as well as 35% smaller model size and 42% structured sparsity on ResNet-50 trained on ImageNet, when compared to existing state-of-the-art model compression methods. Code is available at https://github.com/Sharath-girish/LilNetX.