 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEIA: Latent View-invariant Embeddings for Implicit 3D Articulation
Sep 10, 2024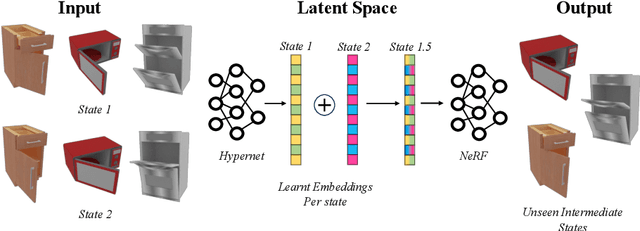
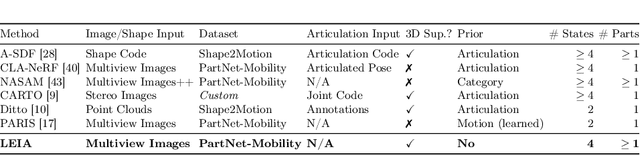
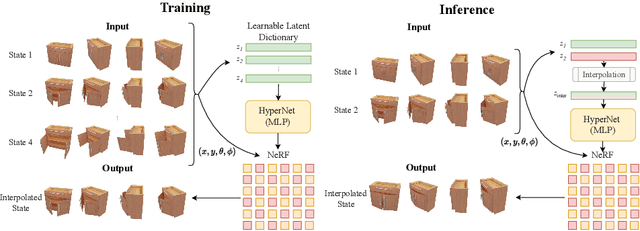

Neural Radiance Fields (NeRFs) have revolutionized the reconstruction of static scenes and objects in 3D, offering unprecedented quality. However, extending NeRFs to model dynamic objects or object articulations remains a challenging problem. Previous works have tackled this issue by focusing on part-level reconstruction and motion estimation for objects, but they often rely on heuristics regarding the number of moving parts or object categories, which can limit their practical use. In this work, we introduce LEIA, a novel approach for representing dynamic 3D objects. Our method involves observing the object at distinct time steps or "states" and conditioning a hypernetwork on the current state, using this to parameterize our NeRF. This approach allows us to learn a view-invariant latent representation for each state. We further demonstrate that by interpolating between these states, we can generate novel articulation configurations in 3D space that were previously unseen. Our experimental results highlight the effectiveness of our method in articulating objects in a manner that is independent of the viewing angle and joint configuration. Notably, our approach outperforms previous methods that rely on motion information for articulation registration.
The Lottery Ticket Hypothesis for Object Recognition
Dec 08, 2020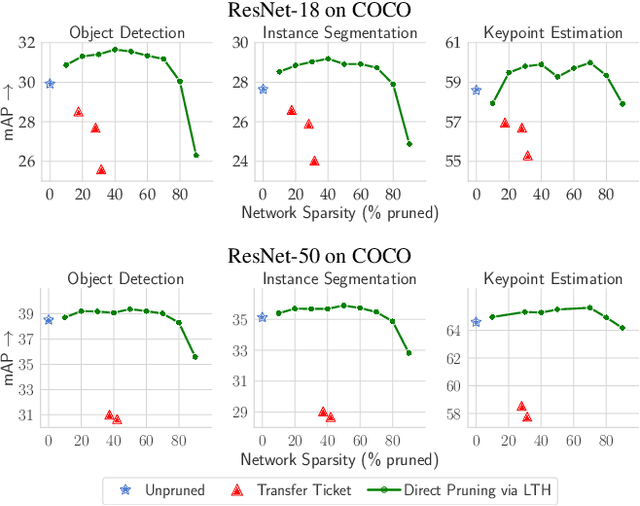
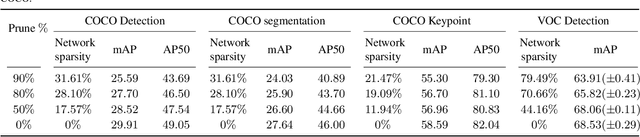

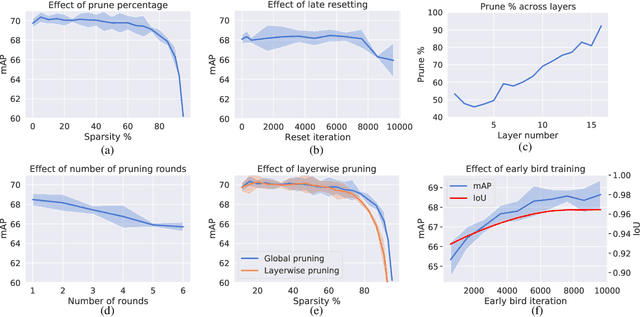
Recognition tasks, such as object recognition and keypoint estimation, have seen widespread adoption in recent years. Most state-of-the-art methods for these tasks use deep networks that are computationally expensive and have huge memory footprints. This makes it exceedingly difficult to deploy these systems on low power embedded devices. Hence, the importance of decreasing the storage requirements and the amount of computation in such models is paramount. The recently proposed Lottery Ticket Hypothesis (LTH) states that deep neural networks trained on large datasets contain smaller subnetworks that achieve on par performance as the dense networks. In this work, we perform the first empirical study investigating LTH for model pruning in the context of object detection, instance segmentation, and keypoint estimation. Our studies reveal that lottery tickets obtained from ImageNet pretraining do not transfer well to the downstream tasks. We provide guidance on how to find lottery tickets with up to 80% overall sparsity on different sub-tasks without incurring any drop in the performance. Finally, we analyse the behavior of trained tickets with respect to various task attributes such as object size, frequency, and difficulty of detection.