 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEIA: Latent View-invariant Embeddings for Implicit 3D Articulation
Sep 10, 2024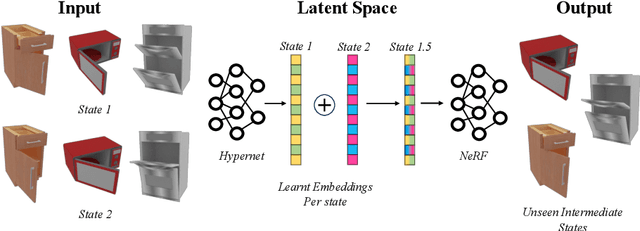
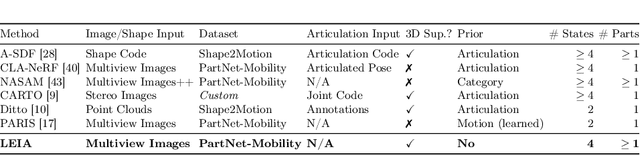
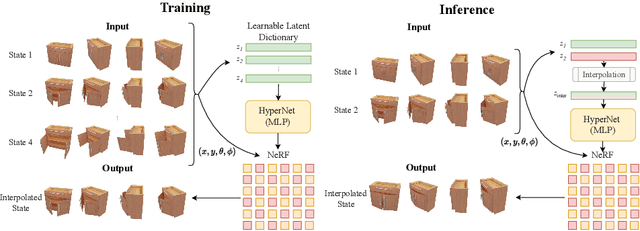

Neural Radiance Fields (NeRFs) have revolutionized the reconstruction of static scenes and objects in 3D, offering unprecedented quality. However, extending NeRFs to model dynamic objects or object articulations remains a challenging problem. Previous works have tackled this issue by focusing on part-level reconstruction and motion estimation for objects, but they often rely on heuristics regarding the number of moving parts or object categories, which can limit their practical use. In this work, we introduce LEIA, a novel approach for representing dynamic 3D objects. Our method involves observing the object at distinct time steps or "states" and conditioning a hypernetwork on the current state, using this to parameterize our NeRF. This approach allows us to learn a view-invariant latent representation for each state. We further demonstrate that by interpolating between these states, we can generate novel articulation configurations in 3D space that were previously unseen. Our experimental results highlight the effectiveness of our method in articulating objects in a manner that is independent of the viewing angle and joint configuration. Notably, our approach outperforms previous methods that rely on motion information for articulation registration.
Do text-free diffusion models learn discriminative visual representations?
Nov 30, 2023



While many unsupervised learning models focus on one family of tasks, either generative or discriminative, we explore the possibility of a unified representation learner: a model which addresses both families of tasks simultaneously. We identify diffusion models, a state-of-the-art method for generative tasks, as a prime candidate. Such models involve training a U-Net to iteratively predict and remove noise, and the resulting model can synthesize high-fidelity, diverse, novel images. We find that the intermediate feature maps of the U-Net are diverse, discriminative feature representations. We propose a novel attention mechanism for pooling feature maps and further leverage this mechanism as DifFormer, a transformer feature fusion of features from different diffusion U-Net blocks and noise steps. We also develop DifFeed, a novel feedback mechanism tailored to diffusion. We find that diffusion models are better than GANs, and, with our fusion and feedback mechanisms, can compete with state-of-the-art unsupervised image representation learning methods for discriminative tasks - image classification with full and semi-supervision, transfer for fine-grained classification, object detection and segmentation, and semantic segmentation. Our project website (https://mgwillia.github.io/diffssl/) and code (https://github.com/soumik-kanad/diffssl) are available publicly.
Chop & Learn: Recognizing and Generating Object-State Compositions
Sep 25, 2023



Recognizing and generating object-state compositions has been a challenging task, especially when generalizing to unseen compositions. In this paper, we study the task of cutting objects in different styles and the resulting object state changes. We propose a new benchmark suite Chop & Learn, to accommodate the needs of learning objects and different cut styles using multiple viewpoints. We also propose a new task of Compositional Image Generation, which can transfer learned cut styles to different objects, by generating novel object-state images. Moreover, we also use the videos for Compositional Action Recognition, and show valuable uses of this dataset for multiple video tasks. Project website: https://chopnlearn.github.io.
Diffusion Models Beat GANs on Image Classification
Jul 17, 2023



While many unsupervised learning models focus on one family of tasks, either generative or discriminative, we explore the possibility of a unified representation learner: a model which uses a single pre-training stage to address both families of tasks simultaneously. We identify diffusion models as a prime candidate. Diffusion models have risen to prominence as a state-of-the-art method for image generation, denoising, inpainting, super-resolution, manipulation, etc. Such models involve training a U-Net to iteratively predict and remove noise, and the resulting model can synthesize high fidelity, diverse, novel images. The U-Net architecture, as a convolution-based architecture, generates a diverse set of feature representations in the form of intermediate feature maps. We present our findings that these embeddings are useful beyond the noise prediction task, as they contain discriminative information and can also be leveraged for classification. We explore optimal methods for extracting and using these embeddings for classification tasks, demonstrating promising results on the ImageNet classification task. We find that with careful feature selection and pooling, diffusion models outperform comparable generative-discriminative methods such as BigBiGAN for classification tasks. We investigate diffusion models in the transfer learning regime, examining their performance on several fine-grained visual classification datasets. We compare these embeddings to those generated by competing architectures and pre-trainings for classification tasks.