 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAN Based Top-Down View Synthesis in Reinforcement Learning Environments
Oct 16, 2024Human actions are based on the mental perception of the environment. Even when all the aspects of an environment are not visible, humans have an internal mental model that can generalize the partially visible scenes to fully constructed and connected views. This internal mental model uses learned abstract representations of spatial and temporal aspects of the environments encountered in the past. Artificial agents in reinforcement learning environments also benefit by learning a representation of the environment from experience. It provides the agent with viewpoints that are not directly visible to it, helping it make better policy decisions. It can also be used to predict the future state of the environment. This project explores learning the top-down view of an RL environment based on the artificial agent's first-person view observations with a generative adversarial network(GAN). The top-down view is useful as it provides a complete overview of the environment by building a map of the entire environment. It provides information about the objects' dimensions and shapes along with their relative positions with one another. Initially, when only a partial observation of the environment is visible to the agent, only a partial top-down view is generated. As the agent explores the environment through a set of actions, the generated top-down view becomes complete. This generated top-down view can assist the agent in deducing better policy decisions. The focus of the project is to learn the top-down view of an RL environment. It doesn't deal with any Reinforcement Learning task.
Chop & Learn: Recognizing and Generating Object-State Compositions
Sep 25, 2023



Recognizing and generating object-state compositions has been a challenging task, especially when generalizing to unseen compositions. In this paper, we study the task of cutting objects in different styles and the resulting object state changes. We propose a new benchmark suite Chop & Learn, to accommodate the needs of learning objects and different cut styles using multiple viewpoints. We also propose a new task of Compositional Image Generation, which can transfer learned cut styles to different objects, by generating novel object-state images. Moreover, we also use the videos for Compositional Action Recognition, and show valuable uses of this dataset for multiple video tasks. Project website: https://chopnlearn.github.io.
FlexNeRF: Photorealistic Free-viewpoint Rendering of Moving Humans from Sparse Views
Mar 25, 2023



We present FlexNeRF, a method for photorealistic freeviewpoint rendering of humans in motion from monocular videos. Our approach works well with sparse views, which is a challenging scenario when the subject is exhibiting fast/complex motions. We propose a novel approach which jointly optimizes a canonical time and pose configuration, with a pose-dependent motion field and pose-independent temporal deformations complementing each other. Thanks to our novel temporal and cyclic consistency constraints along with additional losses on intermediate representation such as segmentation, our approach provides high quality outputs as the observed views become sparser. We empirically demonstrate that our method significantly outperforms the state-of-the-art on public benchmark datasets as well as a self-captured fashion dataset. The project page is available at: https://flex-nerf.github.io/
PointCaps: Raw Point Cloud Processing using Capsule Networks with Euclidean Distance Routing
Dec 21, 2021



Raw point cloud processing using capsule networks is widely adopted in classification, reconstruction, and segmentation due to its ability to preserve spatial agreement of the input data. However, most of the existing capsule based network approaches are computationally heavy and fail at representing the entire point cloud as a single capsule. We address these limitations in existing capsule network based approaches by proposing PointCaps, a novel convolutional capsule architecture with parameter sharing. Along with PointCaps, we propose a novel Euclidean distance routing algorithm and a class-independent latent representation. The latent representation captures physically interpretable geometric parameters of the point cloud, with dynamic Euclidean routing, PointCaps well-represents the spatial (point-to-part) relationships of points. PointCaps has a significantly lower number of parameters and requires a significantly lower number of FLOPs while achieving better reconstruction with comparable classification and segmentation accuracy for raw point clouds compared to state-of-the-art capsule networks.
PatchGame: Learning to Signal Mid-level Patches in Referential Games
Nov 02, 2021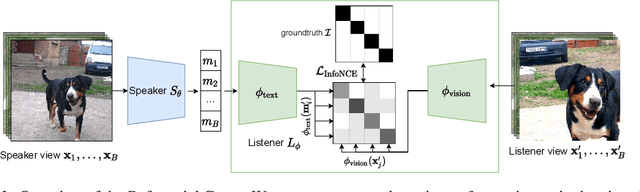
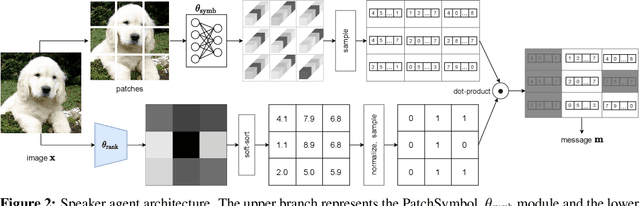


We study a referential game (a type of signaling game) where two agents communicate with each other via a discrete bottleneck to achieve a common goal. In our referential game, the goal of the speaker is to compose a message or a symbolic representation of "important" image patches, while the task for the listener is to match the speaker's message to a different view of the same image. We show that it is indeed possible for the two agents to develop a communication protocol without explicit or implicit supervision. We further investigate the developed protocol and show the applications in speeding up recent Vision Transformers by using only important patches, and as pre-training for downstream recognition tasks (e.g., classification). Code available at https://github.com/kampta/PatchGame.
FlowCaps: Optical Flow Estimation with Capsule Networks For Action Recognition
Nov 08, 2020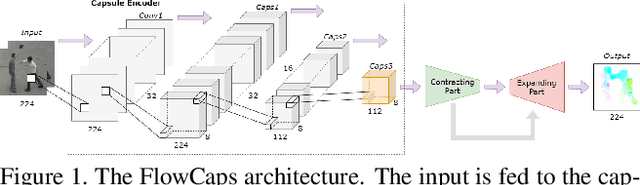
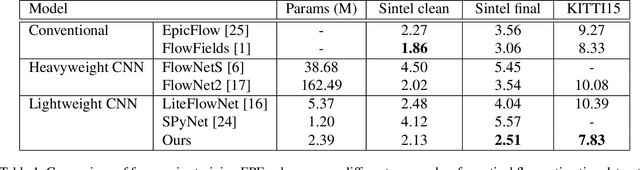
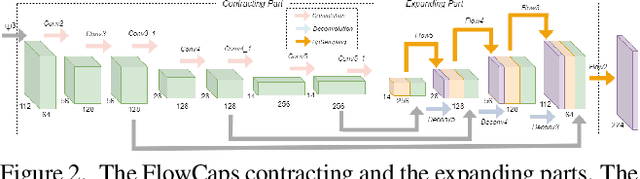
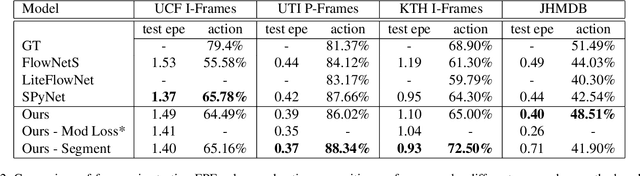
Capsule networks (CapsNets) have recently shown promise to excel in most computer vision tasks, especially pertaining to scene understanding. In this paper, we explore CapsNet's capabilities in optical flow estimation, a task at which convolutional neural networks (CNNs) have already outperformed other approaches. We propose a CapsNet-based architecture, termed FlowCaps, which attempts to a) achieve better correspondence matching via finer-grained, motion-specific, and more-interpretable encoding crucial for optical flow estimation, b) perform better-generalizable optical flow estimation, c) utilize lesser ground truth data, and d) significantly reduce the computational complexity in achieving good performance, in comparison to its CNN-counterparts.
TimeCaps: Learning From Time Series Data with Capsule Networks
Jan 11, 2020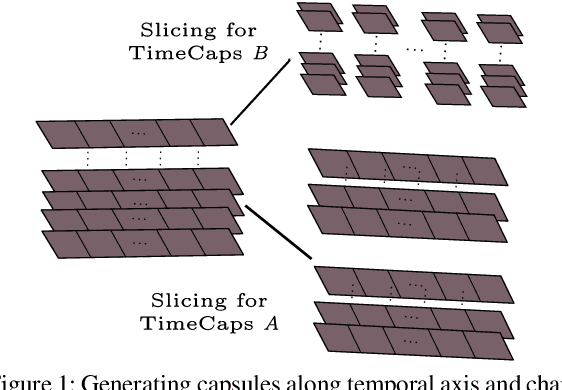
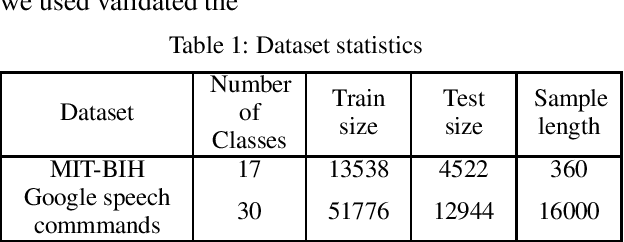
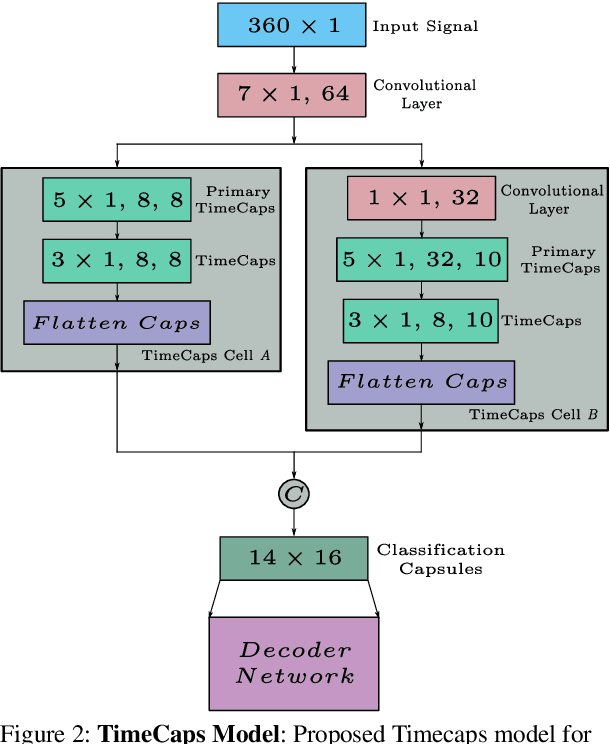
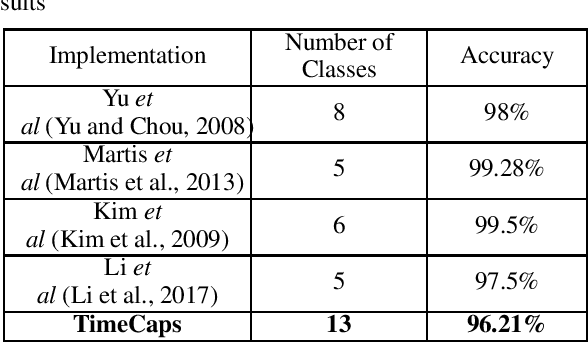
Capsule networks excel in understanding spatial relationships in 2D data for vision related tasks. Even though they are not designed to capture 1D temporal relationships, with TimeCaps we demonstrate that given the ability, capsule networks excel in understanding temporal relationships. To this end, we generate capsules along the temporal and channel dimensions creating two temporal feature detectors which learn contrasting relationships. TimeCaps surpasses the state-of-the-art results by achieving 96.21% accuracy on identifying 13 Electrocardiogram (ECG) signal beat categories, while achieving on-par results on identifying 30 classes of short audio commands. Further, the instantiation parameters inherently learnt by the capsule networks allow us to completely parameterize 1D signals which opens various possibilities in signal processing.
Device-Free User Authentication, Activity Classification and Tracking using Passive Wi-Fi Sensing: A Deep Learning Based Approach
Nov 26, 2019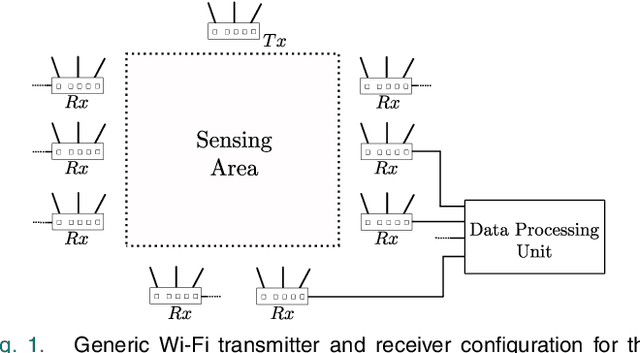
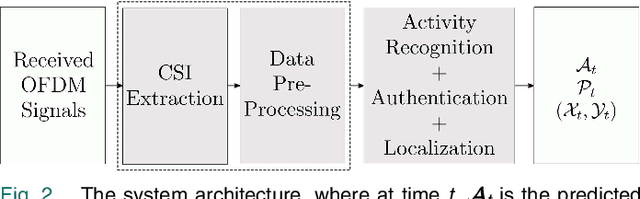
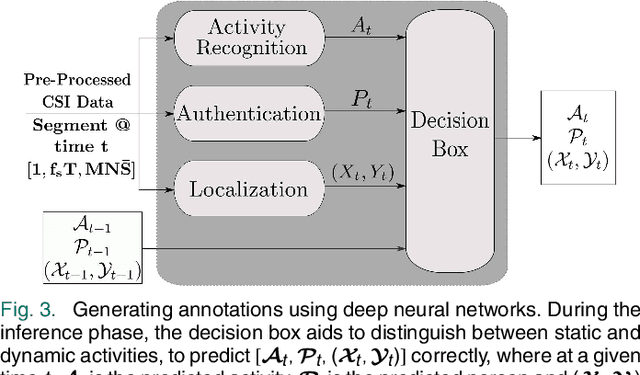
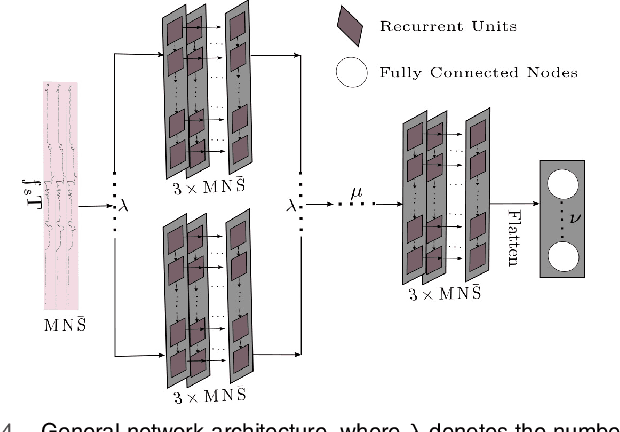
Privacy issues related to video camera feeds have led to a growing need for suitable alternatives that provide functionalities such as user authentication, activity classification and tracking in a noninvasive manner. Existing infrastructure makes Wi-Fi a possible candidate, yet, utilizing traditional signal processing methods to extract information necessary to fully characterize an event by sensing weak ambient Wi-Fi signals is deemed to be challenging. This paper introduces a novel end to-end deep learning framework that simultaneously predicts the identity, activity and the location of a user to create user profiles similar to the information provided through a video camera. The system is fully autonomous and requires zero user intervention unlike systems that require user-initiated initialization, or a user held transmitting device to facilitate the prediction. The system can also predict the trajectory of the user by predicting the location of a user over consecutive time steps. The performance of the system is evaluated through experiments.
TreeCaps: Tree-Structured Capsule Networks for Program Source Code Processing
Oct 27, 2019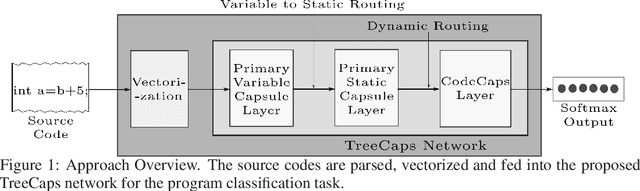

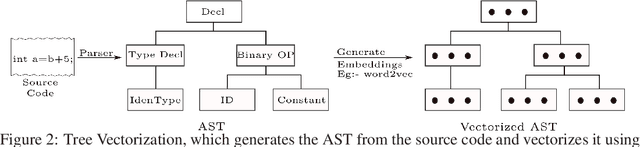

Program comprehension is a fundamental task in software development and maintenance processes. Software developers often need to understand a large amount of existing code before they can develop new features or fix bugs in existing programs. Being able to process programming language code automatically and provide summaries of code functionality accurately can significantly help developers to reduce time spent in code navigation and understanding, and thus increase productivity. Different from natural language articles, source code in programming languages often follows rigid syntactical structures and there can exist dependencies among code elements that are located far away from each other through complex control flows and data flows. Existing studies on tree-based convolutional neural networks (TBCNN) and gated graph neural networks (GGNN) are not able to capture essential semantic dependencies among code elements accurately. In this paper, we propose novel tree-based capsule networks (TreeCaps) and relevant techniques for processing program code in an automated way that encodes code syntactical structures and captures code dependencies more accurately. Based on evaluation on programs written in different programming languages, we show that our TreeCaps-based approach can outperform other approaches in classifying the functionalities of many programs.
DeepCaps: Going Deeper with Capsule Networks
Apr 21, 2019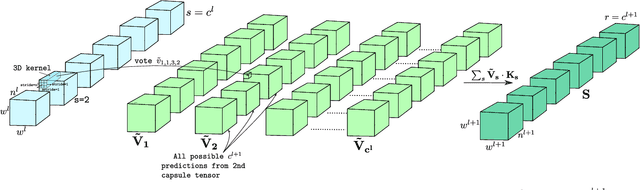
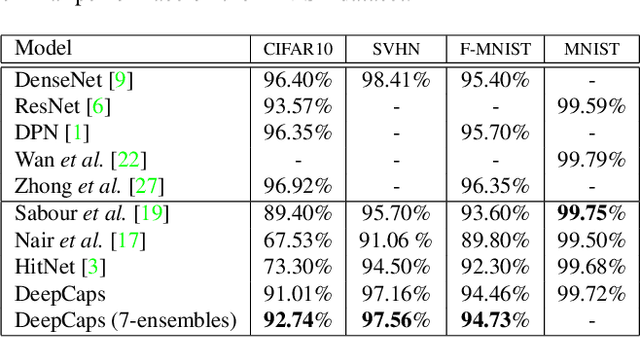
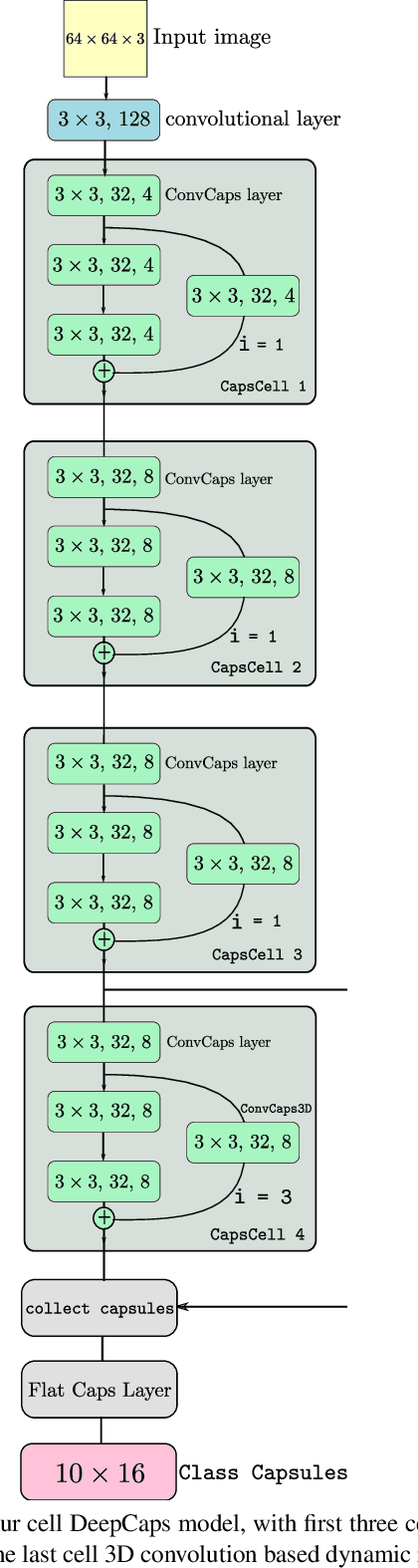
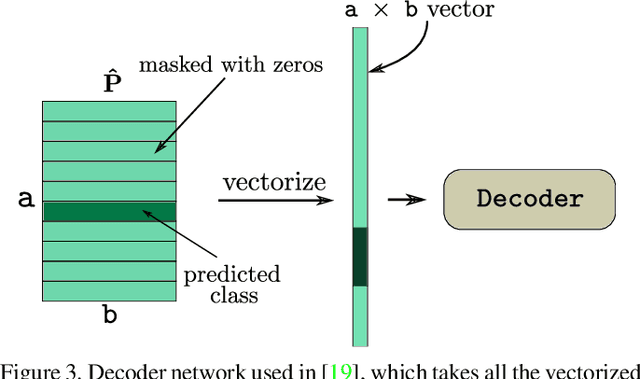
Capsule Network is a promising concept in deep learning, yet its true potential is not fully realized thus far, providing sub-par performance on several key benchmark datasets with complex data. Drawing intuition from the success achieved by Convolutional Neural Networks (CNNs) by going deeper, we introduce DeepCaps1, a deep capsule network architecture which uses a novel 3D convolution based dynamic routing algorithm. With DeepCaps, we surpass the state-of-the-art results in the capsule network domain on CIFAR10, SVHN and Fashion MNIST, while achieving a 68% reduction in the number of parameters. Further, we propose a class-independent decoder network, which strengthens the use of reconstruction loss as a regularization term. This leads to an interesting property of the decoder, which allows us to identify and control the physical attributes of the images represented by the instantiation parameters.