 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll-in-One Conditioning for Text-to-Image Synthesis
Feb 09, 2026Accurate interpretation and visual representation of complex prompts involving multiple objects, attributes, and spatial relationships is a critical challenge in text-to-image synthesis. Despite recent advancements in generating photorealistic outputs, current models often struggle with maintaining semantic fidelity and structural coherence when processing intricate textual inputs. We propose a novel approach that grounds text-to-image synthesis within the framework of scene graph structures, aiming to enhance the compositional abilities of existing models. Eventhough, prior approaches have attempted to address this by using pre-defined layout maps derived from prompts, such rigid constraints often limit compositional flexibility and diversity. In contrast, we introduce a zero-shot, scene graph-based conditioning mechanism that generates soft visual guidance during inference. At the core of our method is the Attribute-Size-Quantity-Location (ASQL) Conditioner, which produces visual conditions via a lightweight language model and guides diffusion-based generation through inference-time optimization. This enables the model to maintain text-image alignment while supporting lightweight, coherent, and diverse image synthesis.
Unified Framework for Open-World Compositional Zero-shot Learning
Dec 05, 2024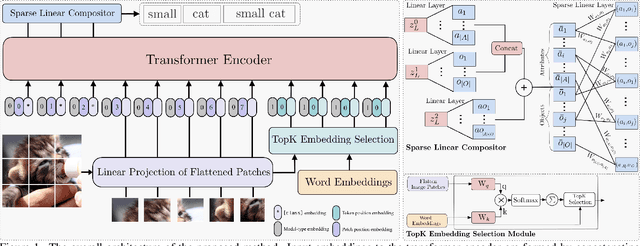



Open-World Compositional Zero-Shot Learning (OW-CZSL) addresses the challenge of recognizing novel compositions of known primitives and entities. Even though prior works utilize language knowledge for recognition, such approaches exhibit limited interactions between language-image modalities. Our approach primarily focuses on enhancing the inter-modality interactions through fostering richer interactions between image and textual data. Additionally, we introduce a novel module aimed at alleviating the computational burden associated with exhaustive exploration of all possible compositions during the inference stage. While previous methods exclusively learn compositions jointly or independently, we introduce an advanced hybrid procedure that leverages both learning mechanisms to generate final predictions. Our proposed model, achieves state-of-the-art in OW-CZSL in three datasets, while surpassing Large Vision Language Models (LLVM) in two datasets.
TimeCaps: Learning From Time Series Data with Capsule Networks
Jan 11, 2020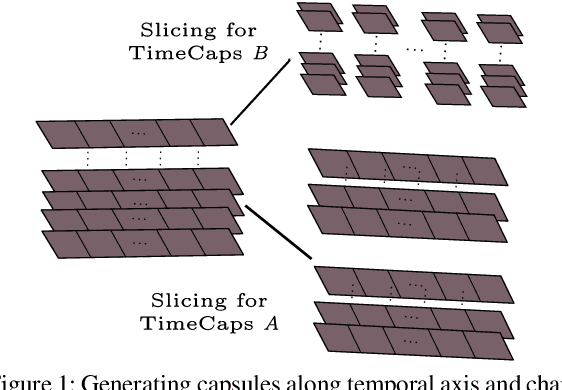
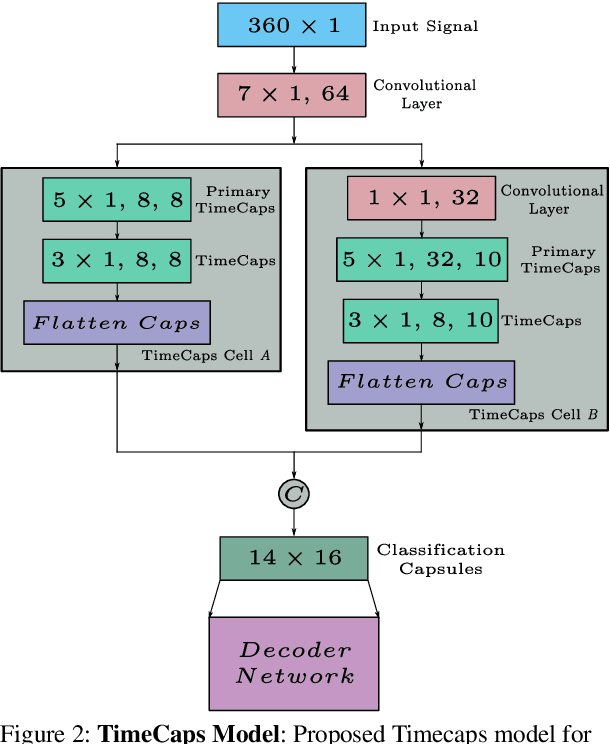
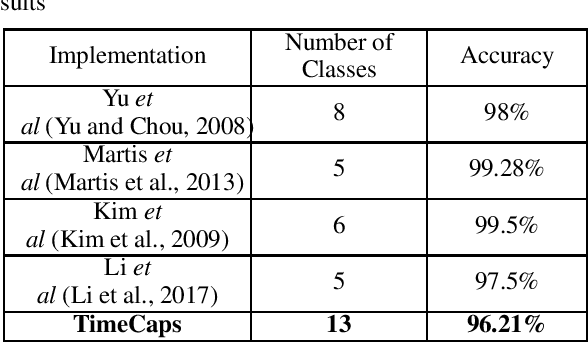
Capsule networks excel in understanding spatial relationships in 2D data for vision related tasks. Even though they are not designed to capture 1D temporal relationships, with TimeCaps we demonstrate that given the ability, capsule networks excel in understanding temporal relationships. To this end, we generate capsules along the temporal and channel dimensions creating two temporal feature detectors which learn contrasting relationships. TimeCaps surpasses the state-of-the-art results by achieving 96.21% accuracy on identifying 13 Electrocardiogram (ECG) signal beat categories, while achieving on-par results on identifying 30 classes of short audio commands. Further, the instantiation parameters inherently learnt by the capsule networks allow us to completely parameterize 1D signals which opens various possibilities in signal processing.
Device-Free User Authentication, Activity Classification and Tracking using Passive Wi-Fi Sensing: A Deep Learning Based Approach
Nov 26, 2019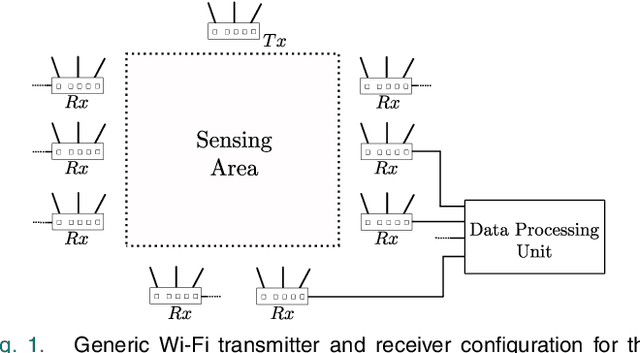
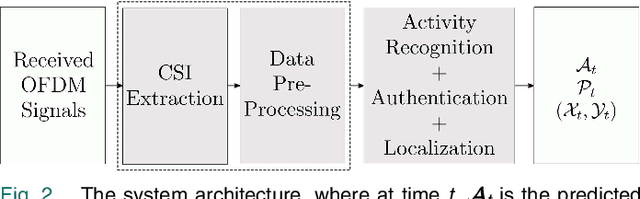
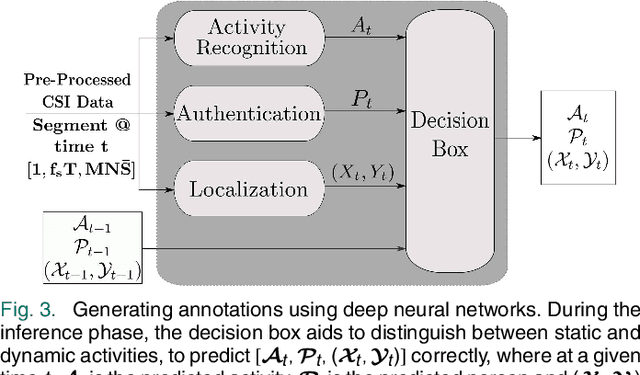
Privacy issues related to video camera feeds have led to a growing need for suitable alternatives that provide functionalities such as user authentication, activity classification and tracking in a noninvasive manner. Existing infrastructure makes Wi-Fi a possible candidate, yet, utilizing traditional signal processing methods to extract information necessary to fully characterize an event by sensing weak ambient Wi-Fi signals is deemed to be challenging. This paper introduces a novel end to-end deep learning framework that simultaneously predicts the identity, activity and the location of a user to create user profiles similar to the information provided through a video camera. The system is fully autonomous and requires zero user intervention unlike systems that require user-initiated initialization, or a user held transmitting device to facilitate the prediction. The system can also predict the trajectory of the user by predicting the location of a user over consecutive time steps. The performance of the system is evaluated through experiments.
DeepCaps: Going Deeper with Capsule Networks
Apr 21, 2019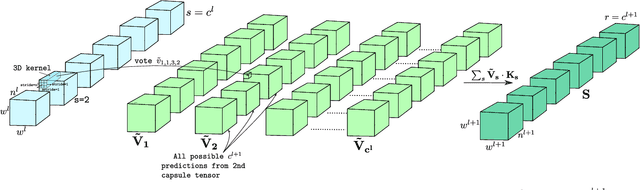
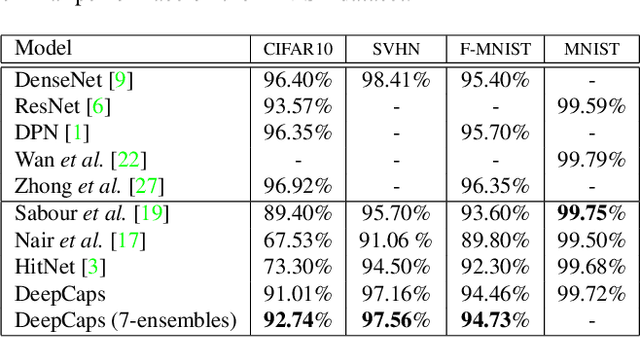
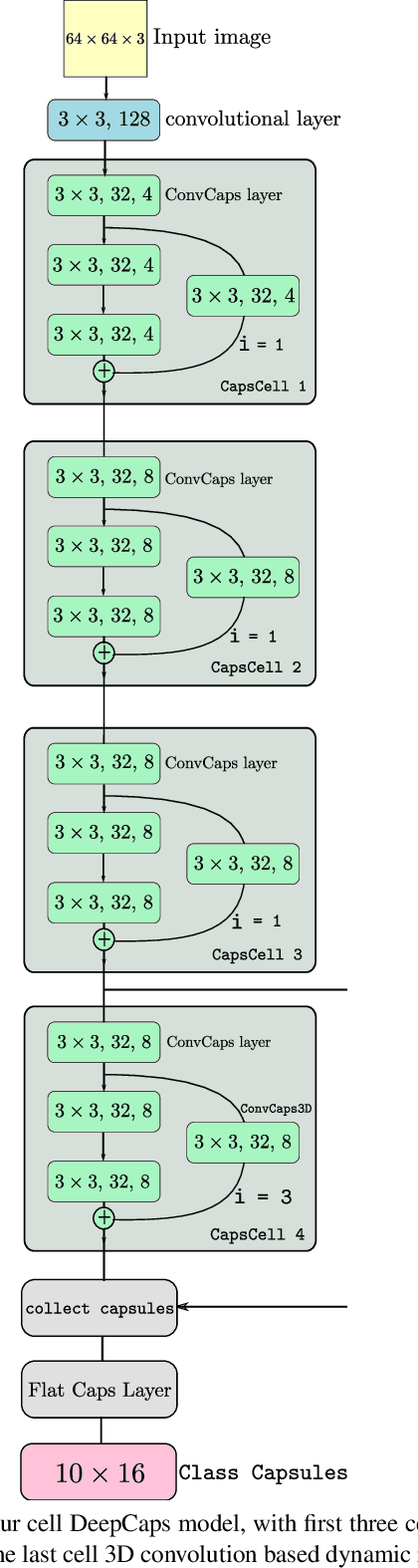
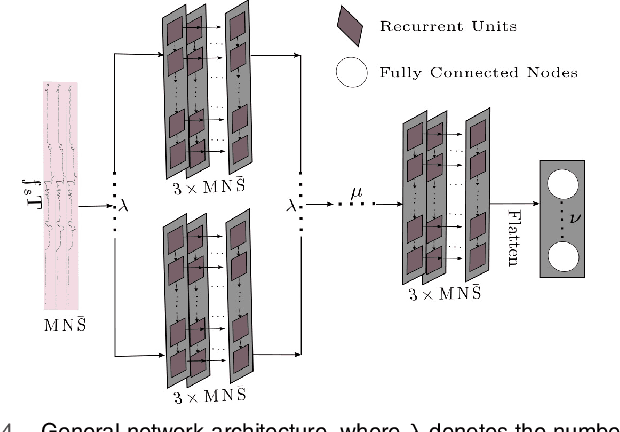
Capsule Network is a promising concept in deep learning, yet its true potential is not fully realized thus far, providing sub-par performance on several key benchmark datasets with complex data. Drawing intuition from the success achieved by Convolutional Neural Networks (CNNs) by going deeper, we introduce DeepCaps1, a deep capsule network architecture which uses a novel 3D convolution based dynamic routing algorithm. With DeepCaps, we surpass the state-of-the-art results in the capsule network domain on CIFAR10, SVHN and Fashion MNIST, while achieving a 68% reduction in the number of parameters. Further, we propose a class-independent decoder network, which strengthens the use of reconstruction loss as a regularization term. This leads to an interesting property of the decoder, which allows us to identify and control the physical attributes of the images represented by the instantiation parameters.
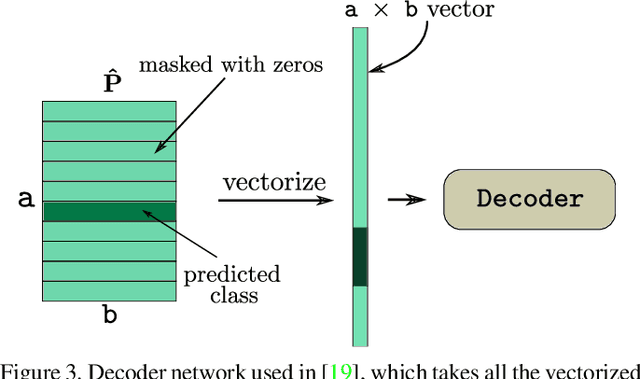
TextCaps : Handwritten Character Recognition with Very Small Datasets
Apr 17, 2019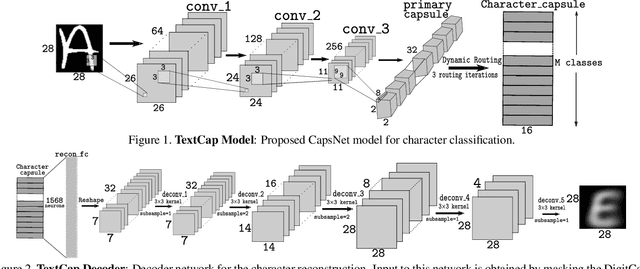
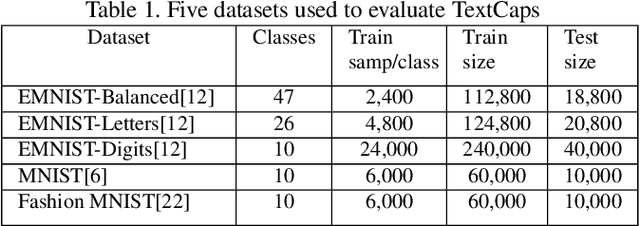
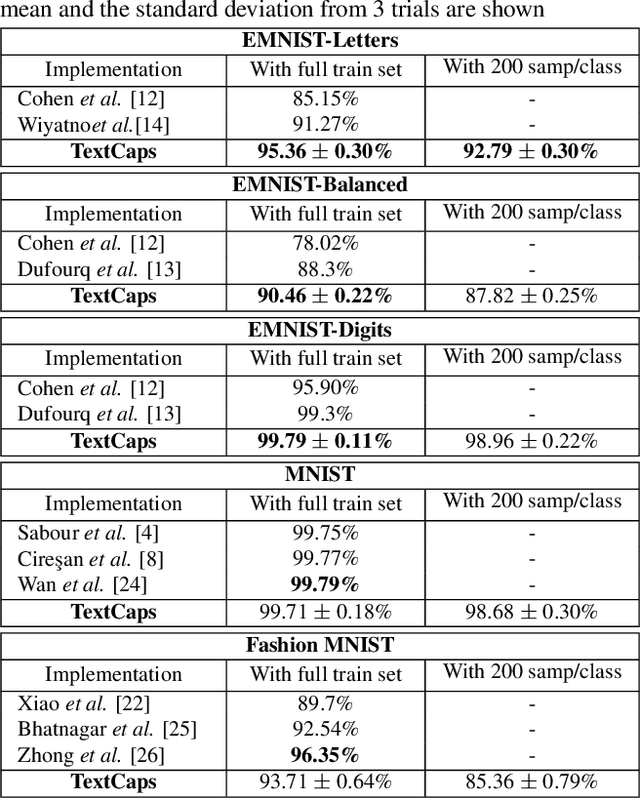

Many localized languages struggle to reap the benefits of recent advancements in character recognition systems due to the lack of substantial amount of labeled training data. This is due to the difficulty in generating large amounts of labeled data for such languages and inability of deep learning techniques to properly learn from small number of training samples. We solve this problem by introducing a technique of generating new training samples from the existing samples, with realistic augmentations which reflect actual variations that are present in human hand writing, by adding random controlled noise to their corresponding instantiation parameters. Our results with a mere 200 training samples per class surpass existing character recognition results in the EMNIST-letter dataset while achieving the existing results in the three datasets: EMNIST-balanced, EMNIST-digits, and MNIST. We also develop a strategy to effectively use a combination of loss functions to improve reconstructions. Our system is useful in character recognition for localized languages that lack much labeled training data and even in other related more general contexts such as object recognition.