 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Framework for Open-World Compositional Zero-shot Learning
Dec 05, 2024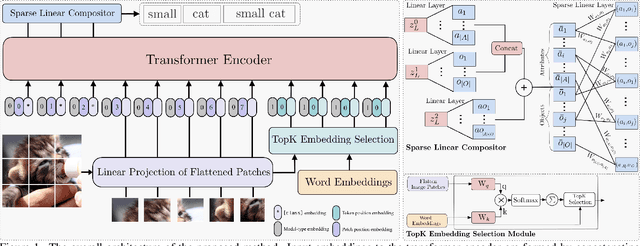



Open-World Compositional Zero-Shot Learning (OW-CZSL) addresses the challenge of recognizing novel compositions of known primitives and entities. Even though prior works utilize language knowledge for recognition, such approaches exhibit limited interactions between language-image modalities. Our approach primarily focuses on enhancing the inter-modality interactions through fostering richer interactions between image and textual data. Additionally, we introduce a novel module aimed at alleviating the computational burden associated with exhaustive exploration of all possible compositions during the inference stage. While previous methods exclusively learn compositions jointly or independently, we introduce an advanced hybrid procedure that leverages both learning mechanisms to generate final predictions. Our proposed model, achieves state-of-the-art in OW-CZSL in three datasets, while surpassing Large Vision Language Models (LLVM) in two datasets.
Composing Object Relations and Attributes for Image-Text Matching
Jun 17, 2024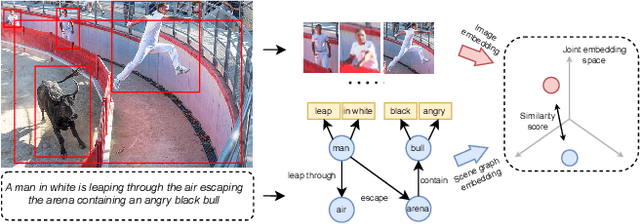
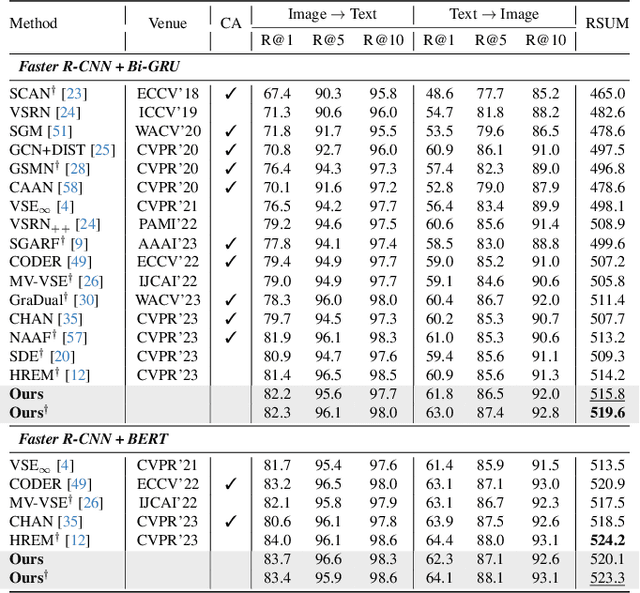

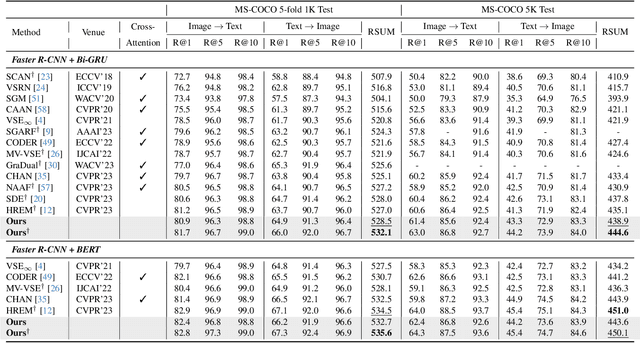
We study the visual semantic embedding problem for image-text matching. Most existing work utilizes a tailored cross-attention mechanism to perform local alignment across the two image and text modalities. This is computationally expensive, even though it is more powerful than the unimodal dual-encoder approach. This work introduces a dual-encoder image-text matching model, leveraging a scene graph to represent captions with nodes for objects and attributes interconnected by relational edges. Utilizing a graph attention network, our model efficiently encodes object-attribute and object-object semantic relations, resulting in a robust and fast-performing system. Representing caption as a scene graph offers the ability to utilize the strong relational inductive bias of graph neural networks to learn object-attribute and object-object relations effectively. To train the model, we propose losses that align the image and caption both at the holistic level (image-caption) and the local level (image-object entity), which we show is key to the success of the model. Our model is termed Composition model for Object Relations and Attributes, CORA. Experimental results on two prominent image-text retrieval benchmarks, Flickr30K and MSCOCO, demonstrate that CORA outperforms existing state-of-the-art computationally expensive cross-attention methods regarding recall score while achieving fast computation speed of the dual encoder.
Disentangling Visual Embeddings for Attributes and Objects
May 17, 2022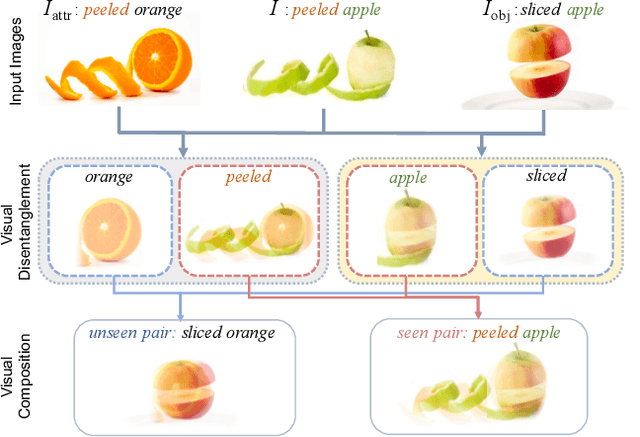
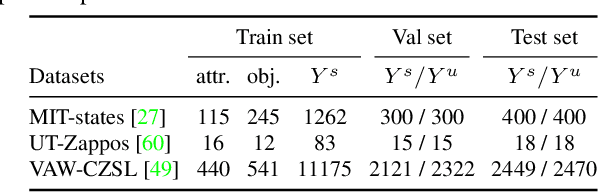
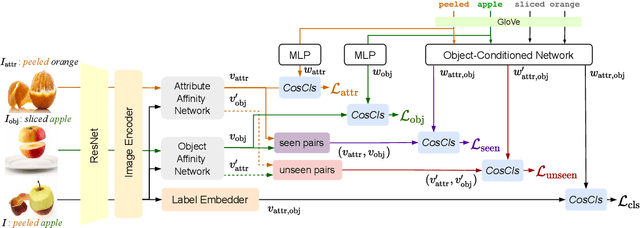
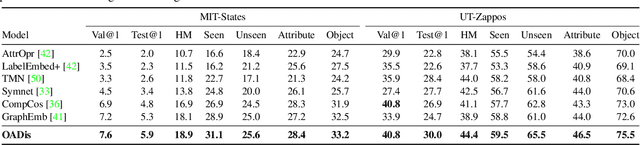
We study the problem of compositional zero-shot learning for object-attribute recognition. Prior works use visual features extracted with a backbone network, pre-trained for object classification and thus do not capture the subtly distinct features associated with attributes. To overcome this challenge, these studies employ supervision from the linguistic space, and use pre-trained word embeddings to better separate and compose attribute-object pairs for recognition. Analogous to linguistic embedding space, which already has unique and agnostic embeddings for object and attribute, we shift the focus back to the visual space and propose a novel architecture that can disentangle attribute and object features in the visual space. We use visual decomposed features to hallucinate embeddings that are representative for the seen and novel compositions to better regularize the learning of our model. Extensive experiments show that our method outperforms existing work with significant margin on three datasets: MIT-States, UT-Zappos, and a new benchmark created based on VAW. The code, models, and dataset splits are publicly available at https://github.com/nirat1606/OADis.
Learning to Predict Visual Attributes in the Wild
Jun 17, 2021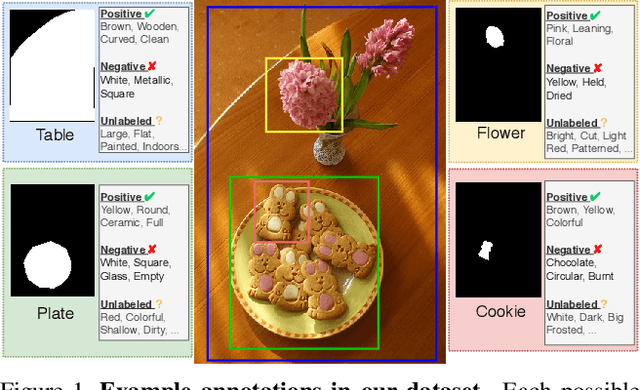

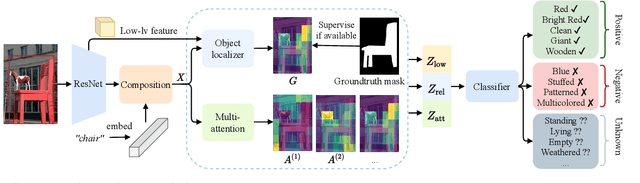
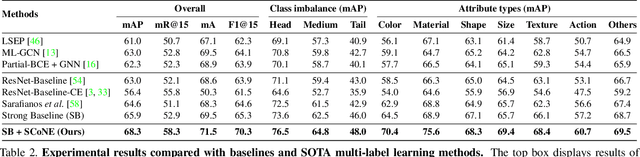
Visual attributes constitute a large portion of information contained in a scene. Objects can be described using a wide variety of attributes which portray their visual appearance (color, texture), geometry (shape, size, posture), and other intrinsic properties (state, action). Existing work is mostly limited to study of attribute prediction in specific domains. In this paper, we introduce a large-scale in-the-wild visual attribute prediction dataset consisting of over 927K attribute annotations for over 260K object instances. Formally, object attribute prediction is a multi-label classification problem where all attributes that apply to an object must be predicted. Our dataset poses significant challenges to existing methods due to large number of attributes, label sparsity, data imbalance, and object occlusion. To this end, we propose several techniques that systematically tackle these challenges, including a base model that utilizes both low- and high-level CNN features with multi-hop attention, reweighting and resampling techniques, a novel negative label expansion scheme, and a novel supervised attribute-aware contrastive learning algorithm. Using these techniques, we achieve near 3.7 mAP and 5.7 overall F1 points improvement over the current state of the art. Further details about the VAW dataset can be found at http://vawdataset.com/.