 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARGENT: Adaptive Hierarchical Image-Text Representations
Mar 24, 2026Large-scale Vision-Language Models (VLMs) such as CLIP learn powerful semantic representations but operate in Euclidean space, which fails to capture the inherent hierarchical structure of visual and linguistic concepts. Hyperbolic geometry, with its exponential volume growth, offers a principled alternative for embedding such hierarchies with low distortion. However, existing hyperbolic VLMs use entailment losses that are unstable: as parent embeddings contract toward the origin, their entailment cones widen toward a half-space, causing catastrophic cone collapse that destroys the intended hierarchy. Additionally, hierarchical evaluation of these models remains unreliable, being largely retrieval-based and correlation-based metrics and prone to taxonomy dependence and ambiguous negatives. To address these limitations, we propose an adaptive entailment loss paired with a norm regularizer that prevents cone collapse without heuristic aperture clipping. We further introduce an angle-based probabilistic entailment protocol (PEP) for evaluating hierarchical understanding, scored with AUC-ROC and Average Precision. This paper introduces a stronger hyperbolic VLM baseline ARGENT, Adaptive hieRarchical imaGe-tExt represeNTation. ARGENT improves the SOTA hyperbolic VLM by 0.7, 1.1, and 0.8 absolute points on image classification, text-to-image retrieval, and proposed hierarchical metrics, respectively.
OmniRet: Efficient and High-Fidelity Omni Modality Retrieval
Mar 02, 2026Multimodal retrieval is the task of aggregating information from queries across heterogeneous modalities to retrieve desired targets. State-of-the-art multimodal retrieval models can understand complex queries, yet they are typically limited to two modalities: text and vision. This limitation impedes the development of universal retrieval systems capable of comprehending queries that combine more than two modalities. To advance toward this goal, we present OmniRet, the first retrieval model capable of handling complex, composed queries spanning three key modalities: text, vision, and audio. Our OmniRet model addresses two critical challenges for universal retrieval: computational efficiency and representation fidelity. First, feeding massive token sequences from modality-specific encoders to Large Language Models (LLMs) is computationally inefficient. We therefore introduce an attention-based resampling mechanism to generate compact, fixed-size representations from these sequences. Second, compressing rich omni-modal data into a single embedding vector inevitably causes information loss and discards fine-grained details. We propose Attention Sliced Wasserstein Pooling to preserve these fine-grained details, leading to improved omni-modal representations. OmniRet is trained on an aggregation of approximately 6 million query-target pairs spanning 30 datasets. We benchmark our model on 13 retrieval tasks and a MMEBv2 subset. Our model demonstrates significant improvements on composed query, audio and video retrieval tasks, while achieving on-par performance with state-of-the-art models on others. Furthermore, we curate a new Audio-Centric Multimodal Benchmark (ACM). This new benchmark introduces two critical, previously missing tasks-composed audio retrieval and audio-visual retrieval to more comprehensively evaluate a model's omni-modal embedding capacity.
All-in-One Conditioning for Text-to-Image Synthesis
Feb 09, 2026Accurate interpretation and visual representation of complex prompts involving multiple objects, attributes, and spatial relationships is a critical challenge in text-to-image synthesis. Despite recent advancements in generating photorealistic outputs, current models often struggle with maintaining semantic fidelity and structural coherence when processing intricate textual inputs. We propose a novel approach that grounds text-to-image synthesis within the framework of scene graph structures, aiming to enhance the compositional abilities of existing models. Eventhough, prior approaches have attempted to address this by using pre-defined layout maps derived from prompts, such rigid constraints often limit compositional flexibility and diversity. In contrast, we introduce a zero-shot, scene graph-based conditioning mechanism that generates soft visual guidance during inference. At the core of our method is the Attribute-Size-Quantity-Location (ASQL) Conditioner, which produces visual conditions via a lightweight language model and guides diffusion-based generation through inference-time optimization. This enables the model to maintain text-image alignment while supporting lightweight, coherent, and diverse image synthesis.
CoLLM: A Large Language Model for Composed Image Retrieval
Mar 25, 2025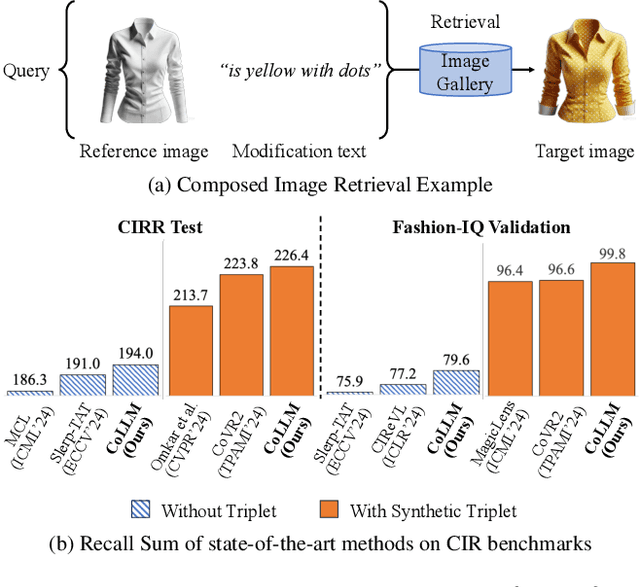
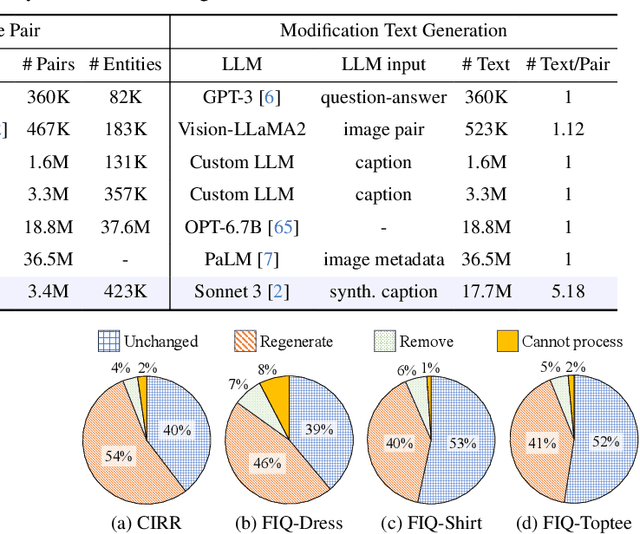
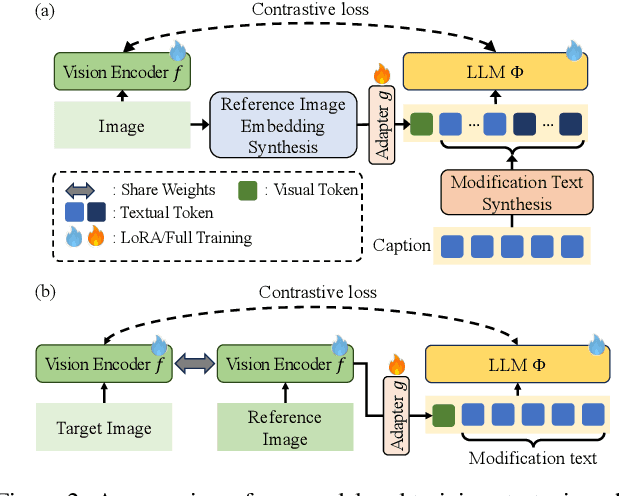
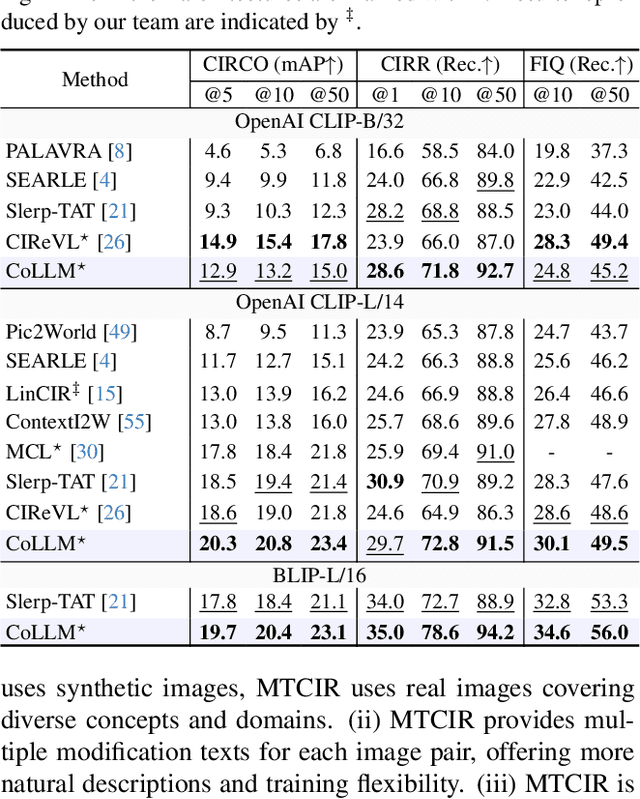
Composed Image Retrieval (CIR) is a complex task that aims to retrieve images based on a multimodal query. Typical training data consists of triplets containing a reference image, a textual description of desired modifications, and the target image, which are expensive and time-consuming to acquire. The scarcity of CIR datasets has led to zero-shot approaches utilizing synthetic triplets or leveraging vision-language models (VLMs) with ubiquitous web-crawled image-caption pairs. However, these methods have significant limitations: synthetic triplets suffer from limited scale, lack of diversity, and unnatural modification text, while image-caption pairs hinder joint embedding learning of the multimodal query due to the absence of triplet data. Moreover, existing approaches struggle with complex and nuanced modification texts that demand sophisticated fusion and understanding of vision and language modalities. We present CoLLM, a one-stop framework that effectively addresses these limitations. Our approach generates triplets on-the-fly from image-caption pairs, enabling supervised training without manual annotation. We leverage Large Language Models (LLMs) to generate joint embeddings of reference images and modification texts, facilitating deeper multimodal fusion. Additionally, we introduce Multi-Text CIR (MTCIR), a large-scale dataset comprising 3.4M samples, and refine existing CIR benchmarks (CIRR and Fashion-IQ) to enhance evaluation reliability. Experimental results demonstrate that CoLLM achieves state-of-the-art performance across multiple CIR benchmarks and settings. MTCIR yields competitive results, with up to 15% performance improvement. Our refined benchmarks provide more reliable evaluation metrics for CIR models, contributing to the advancement of this important field.
VeriGraph: Scene Graphs for Execution Verifiable Robot Planning
Nov 15, 2024



Recent advancements in vision-language models (VLMs) offer potential for robot task planning, but challenges remain due to VLMs' tendency to generate incorrect action sequences. To address these limitations, we propose VeriGraph, a novel framework that integrates VLMs for robotic planning while verifying action feasibility. VeriGraph employs scene graphs as an intermediate representation, capturing key objects and spatial relationships to improve plan verification and refinement. The system generates a scene graph from input images and uses it to iteratively check and correct action sequences generated by an LLM-based task planner, ensuring constraints are respected and actions are executable. Our approach significantly enhances task completion rates across diverse manipulation scenarios, outperforming baseline methods by 58% for language-based tasks and 30% for image-based tasks.
Composing Object Relations and Attributes for Image-Text Matching
Jun 17, 2024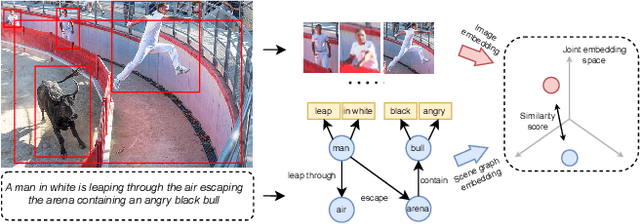
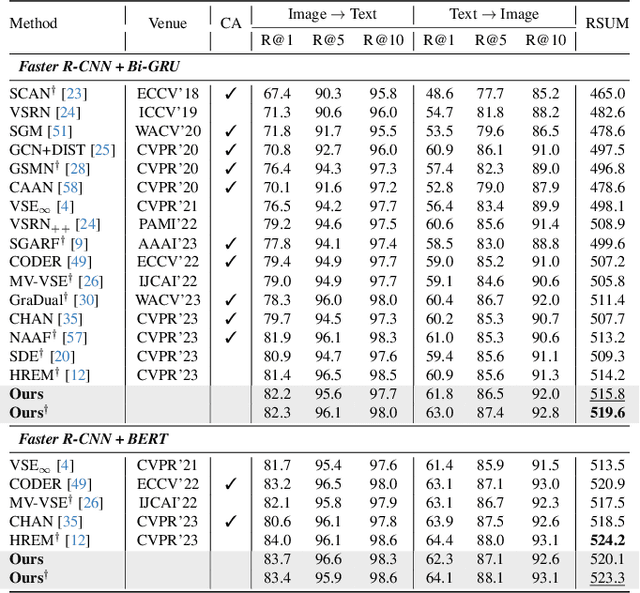

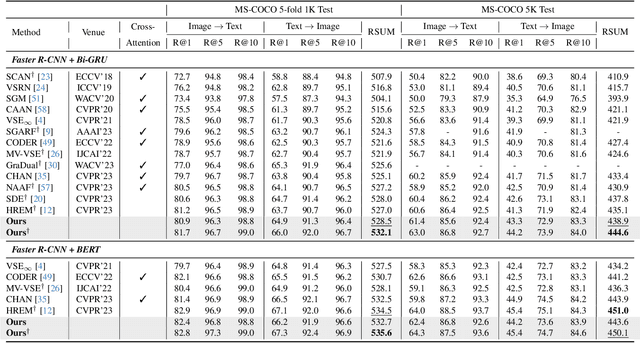
We study the visual semantic embedding problem for image-text matching. Most existing work utilizes a tailored cross-attention mechanism to perform local alignment across the two image and text modalities. This is computationally expensive, even though it is more powerful than the unimodal dual-encoder approach. This work introduces a dual-encoder image-text matching model, leveraging a scene graph to represent captions with nodes for objects and attributes interconnected by relational edges. Utilizing a graph attention network, our model efficiently encodes object-attribute and object-object semantic relations, resulting in a robust and fast-performing system. Representing caption as a scene graph offers the ability to utilize the strong relational inductive bias of graph neural networks to learn object-attribute and object-object relations effectively. To train the model, we propose losses that align the image and caption both at the holistic level (image-caption) and the local level (image-object entity), which we show is key to the success of the model. Our model is termed Composition model for Object Relations and Attributes, CORA. Experimental results on two prominent image-text retrieval benchmarks, Flickr30K and MSCOCO, demonstrate that CORA outperforms existing state-of-the-art computationally expensive cross-attention methods regarding recall score while achieving fast computation speed of the dual encoder.
MaGGIe: Masked Guided Gradual Human Instance Matting
Apr 24, 2024

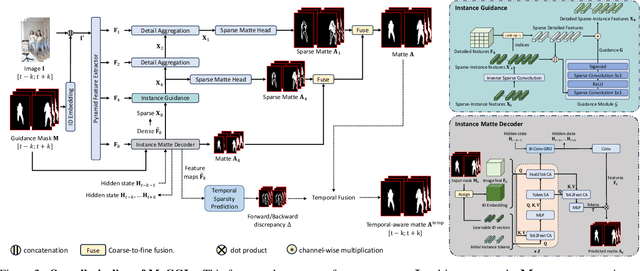

Human matting is a foundation task in image and video processing, where human foreground pixels are extracted from the input. Prior works either improve the accuracy by additional guidance or improve the temporal consistency of a single instance across frames. We propose a new framework MaGGIe, Masked Guided Gradual Human Instance Matting, which predicts alpha mattes progressively for each human instances while maintaining the computational cost, precision, and consistency. Our method leverages modern architectures, including transformer attention and sparse convolution, to output all instance mattes simultaneously without exploding memory and latency. Although keeping constant inference costs in the multiple-instance scenario, our framework achieves robust and versatile performance on our proposed synthesized benchmarks. With the higher quality image and video matting benchmarks, the novel multi-instance synthesis approach from publicly available sources is introduced to increase the generalization of models in real-world scenarios.
SimpSON: Simplifying Photo Cleanup with Single-Click Distracting Object Segmentation Network
May 28, 2023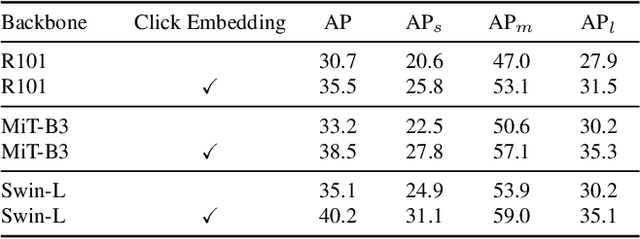
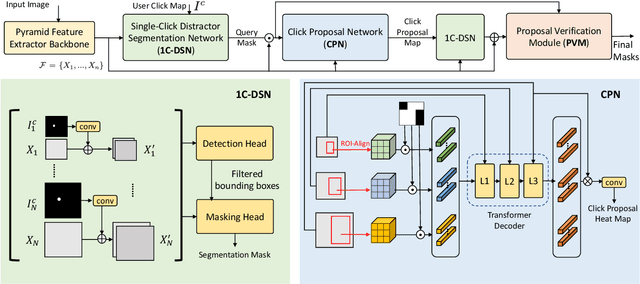
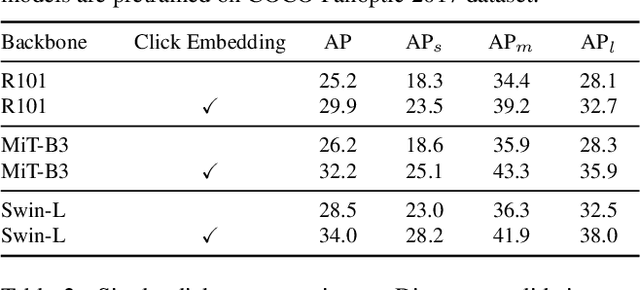
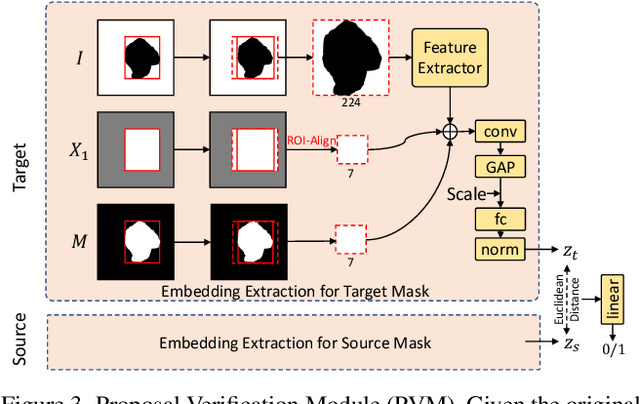
In photo editing, it is common practice to remove visual distractions to improve the overall image quality and highlight the primary subject. However, manually selecting and removing these small and dense distracting regions can be a laborious and time-consuming task. In this paper, we propose an interactive distractor selection method that is optimized to achieve the task with just a single click. Our method surpasses the precision and recall achieved by the traditional method of running panoptic segmentation and then selecting the segments containing the clicks. We also showcase how a transformer-based module can be used to identify more distracting regions similar to the user's click position. Our experiments demonstrate that the model can effectively and accurately segment unknown distracting objects interactively and in groups. By significantly simplifying the photo cleaning and retouching process, our proposed model provides inspiration for exploring rare object segmentation and group selection with a single click.
Progressive Semantic Segmentation
Apr 08, 2021


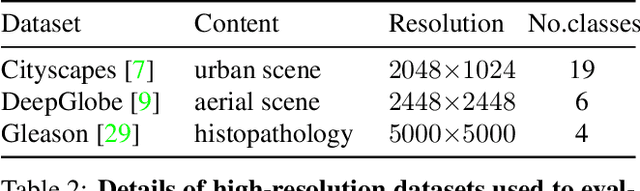
The objective of this work is to segment high-resolution images without overloading GPU memory usage or losing the fine details in the output segmentation map. The memory constraint means that we must either downsample the big image or divide the image into local patches for separate processing. However, the former approach would lose the fine details, while the latter can be ambiguous due to the lack of a global picture. In this work, we present MagNet, a multi-scale framework that resolves local ambiguity by looking at the image at multiple magnification levels. MagNet has multiple processing stages, where each stage corresponds to a magnification level, and the output of one stage is fed into the next stage for coarse-to-fine information propagation. Each stage analyzes the image at a higher resolution than the previous stage, recovering the previously lost details due to the lossy downsampling step, and the segmentation output is progressively refined through the processing stages. Experiments on three high-resolution datasets of urban views, aerial scenes, and medical images show that MagNet consistently outperforms the state-of-the-art methods by a significant margin.