 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagine, Verify, Execute: Memory-Guided Agentic Exploration with Vision-Language Models
May 12, 2025



Exploration is essential for general-purpose robotic learning, especially in open-ended environments where dense rewards, explicit goals, or task-specific supervision are scarce. Vision-language models (VLMs), with their semantic reasoning over objects, spatial relations, and potential outcomes, present a compelling foundation for generating high-level exploratory behaviors. However, their outputs are often ungrounded, making it difficult to determine whether imagined transitions are physically feasible or informative. To bridge the gap between imagination and execution, we present IVE (Imagine, Verify, Execute), an agentic exploration framework inspired by human curiosity. Human exploration is often driven by the desire to discover novel scene configurations and to deepen understanding of the environment. Similarly, IVE leverages VLMs to abstract RGB-D observations into semantic scene graphs, imagine novel scenes, predict their physical plausibility, and generate executable skill sequences through action tools. We evaluate IVE in both simulated and real-world tabletop environments. The results show that IVE enables more diverse and meaningful exploration than RL baselines, as evidenced by a 4.1 to 7.8x increase in the entropy of visited states. Moreover, the collected experience supports downstream learning, producing policies that closely match or exceed the performance of those trained on human-collected demonstrations.
TREND: Tri-teaching for Robust Preference-based Reinforcement Learning with Demonstrations
May 09, 2025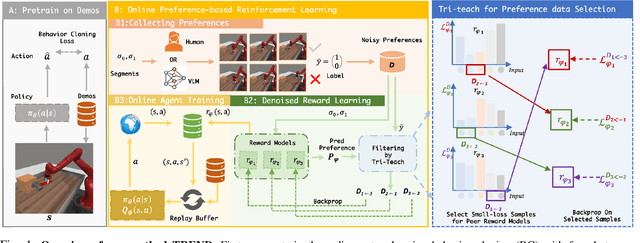
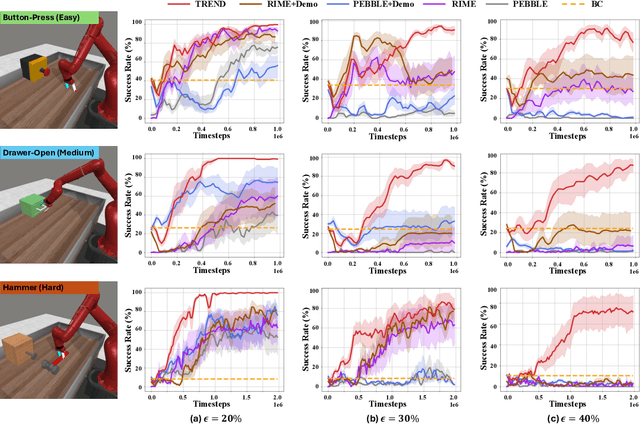
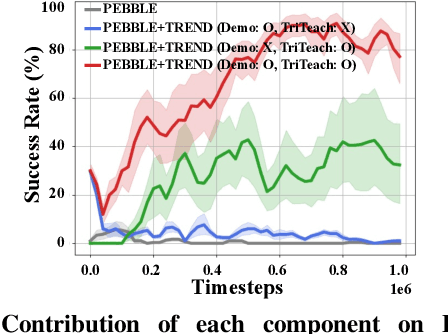
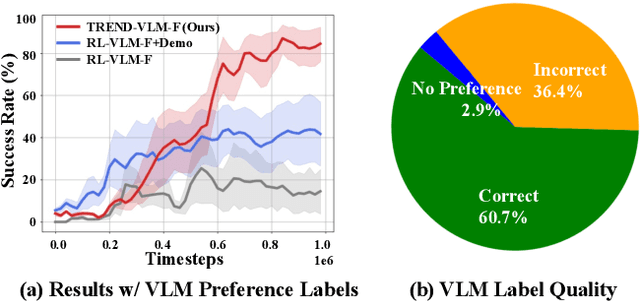
Preference feedback collected by human or VLM annotators is often noisy, presenting a significant challenge for preference-based reinforcement learning that relies on accurate preference labels. To address this challenge, we propose TREND, a novel framework that integrates few-shot expert demonstrations with a tri-teaching strategy for effective noise mitigation. Our method trains three reward models simultaneously, where each model views its small-loss preference pairs as useful knowledge and teaches such useful pairs to its peer network for updating the parameters. Remarkably, our approach requires as few as one to three expert demonstrations to achieve high performance. We evaluate TREND on various robotic manipulation tasks, achieving up to 90% success rates even with noise levels as high as 40%, highlighting its effective robustness in handling noisy preference feedback. Project page: https://shuaiyihuang.github.io/publications/TREND.
VeriGraph: Scene Graphs for Execution Verifiable Robot Planning
Nov 15, 2024



Recent advancements in vision-language models (VLMs) offer potential for robot task planning, but challenges remain due to VLMs' tendency to generate incorrect action sequences. To address these limitations, we propose VeriGraph, a novel framework that integrates VLMs for robotic planning while verifying action feasibility. VeriGraph employs scene graphs as an intermediate representation, capturing key objects and spatial relationships to improve plan verification and refinement. The system generates a scene graph from input images and uses it to iteratively check and correct action sequences generated by an LLM-based task planner, ensuring constraints are respected and actions are executable. Our approach significantly enhances task completion rates across diverse manipulation scenarios, outperforming baseline methods by 58% for language-based tasks and 30% for image-based tasks.