 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTREND: Tri-teaching for Robust Preference-based Reinforcement Learning with Demonstrations
May 09, 2025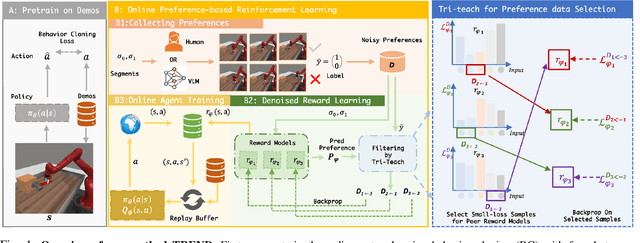
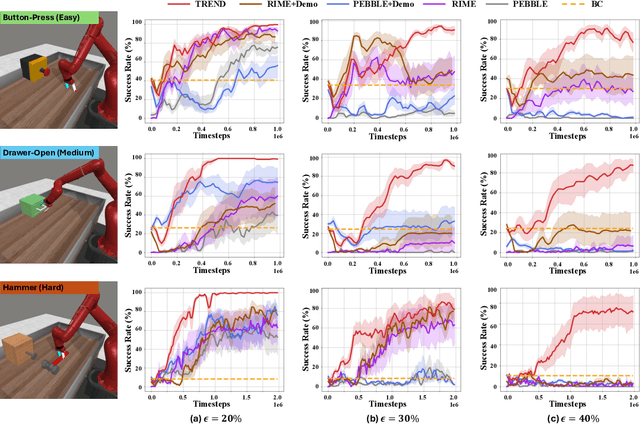
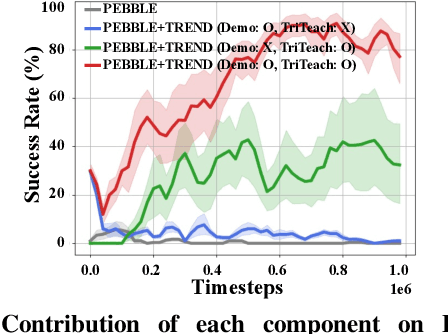
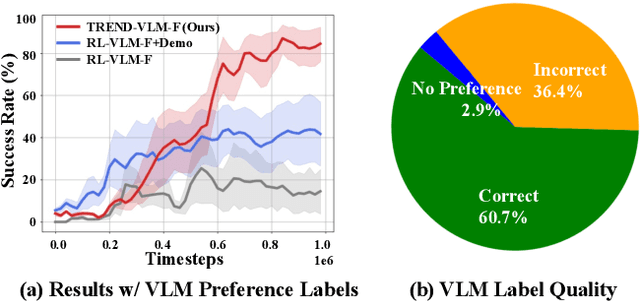
Preference feedback collected by human or VLM annotators is often noisy, presenting a significant challenge for preference-based reinforcement learning that relies on accurate preference labels. To address this challenge, we propose TREND, a novel framework that integrates few-shot expert demonstrations with a tri-teaching strategy for effective noise mitigation. Our method trains three reward models simultaneously, where each model views its small-loss preference pairs as useful knowledge and teaches such useful pairs to its peer network for updating the parameters. Remarkably, our approach requires as few as one to three expert demonstrations to achieve high performance. We evaluate TREND on various robotic manipulation tasks, achieving up to 90% success rates even with noise levels as high as 40%, highlighting its effective robustness in handling noisy preference feedback. Project page: https://shuaiyihuang.github.io/publications/TREND.
LEIA: Latent View-invariant Embeddings for Implicit 3D Articulation
Sep 10, 2024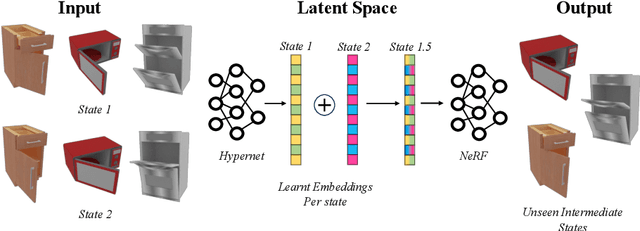
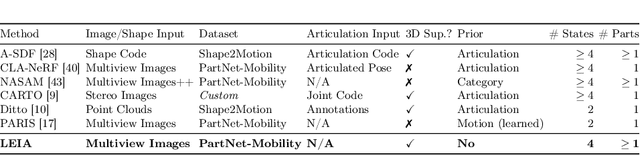
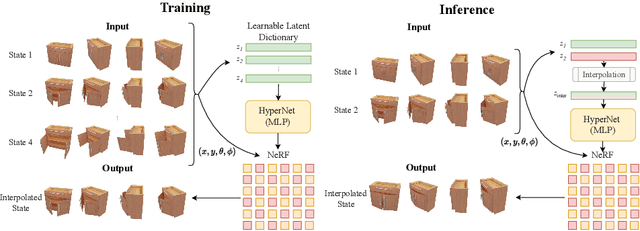

Neural Radiance Fields (NeRFs) have revolutionized the reconstruction of static scenes and objects in 3D, offering unprecedented quality. However, extending NeRFs to model dynamic objects or object articulations remains a challenging problem. Previous works have tackled this issue by focusing on part-level reconstruction and motion estimation for objects, but they often rely on heuristics regarding the number of moving parts or object categories, which can limit their practical use. In this work, we introduce LEIA, a novel approach for representing dynamic 3D objects. Our method involves observing the object at distinct time steps or "states" and conditioning a hypernetwork on the current state, using this to parameterize our NeRF. This approach allows us to learn a view-invariant latent representation for each state. We further demonstrate that by interpolating between these states, we can generate novel articulation configurations in 3D space that were previously unseen. Our experimental results highlight the effectiveness of our method in articulating objects in a manner that is independent of the viewing angle and joint configuration. Notably, our approach outperforms previous methods that rely on motion information for articulation registration.
Latent-INR: A Flexible Framework for Implicit Representations of Videos with Discriminative Semantics
Aug 05, 2024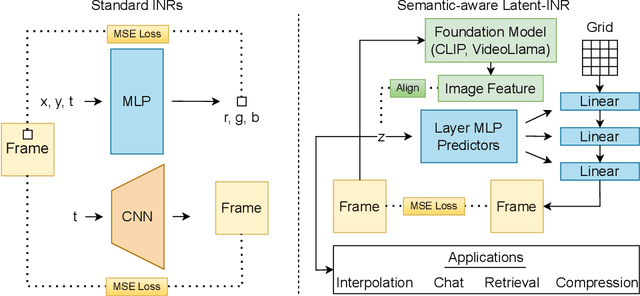
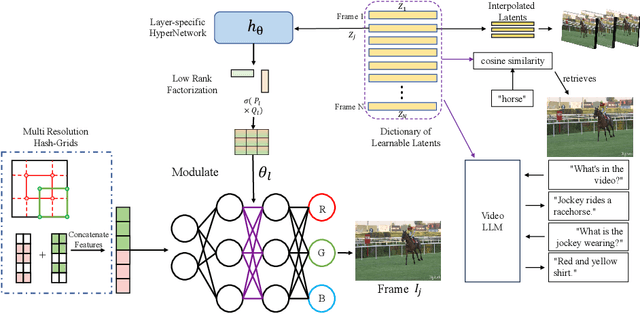
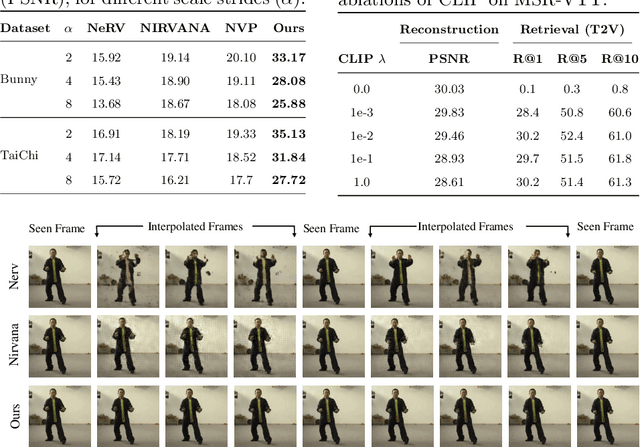
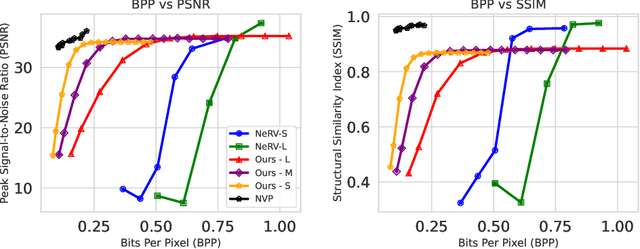
Implicit Neural Networks (INRs) have emerged as powerful representations to encode all forms of data, including images, videos, audios, and scenes. With video, many INRs for video have been proposed for the compression task, and recent methods feature significant improvements with respect to encoding time, storage, and reconstruction quality. However, these encoded representations lack semantic meaning, so they cannot be used for any downstream tasks that require such properties, such as retrieval. This can act as a barrier for adoption of video INRs over traditional codecs as they do not offer any significant edge apart from compression. To alleviate this, we propose a flexible framework that decouples the spatial and temporal aspects of the video INR. We accomplish this with a dictionary of per-frame latents that are learned jointly with a set of video specific hypernetworks, such that given a latent, these hypernetworks can predict the INR weights to reconstruct the given frame. This framework not only retains the compression efficiency, but the learned latents can be aligned with features from large vision models, which grants them discriminative properties. We align these latents with CLIP and show good performance for both compression and video retrieval tasks. By aligning with VideoLlama, we are able to perform open-ended chat with our learned latents as the visual inputs. Additionally, the learned latents serve as a proxy for the underlying weights, allowing us perform tasks like video interpolation. These semantic properties and applications, existing simultaneously with ability to perform compression, interpolation, and superresolution properties, are a first in this field of work.
MedMAE: A Self-Supervised Backbone for Medical Imaging Tasks
Jul 20, 2024



Medical imaging tasks are very challenging due to the lack of publicly available labeled datasets. Hence, it is difficult to achieve high performance with existing deep-learning models as they require a massive labeled dataset to be trained effectively. An alternative solution is to use pre-trained models and fine-tune them using the medical imaging dataset. However, all existing models are pre-trained using natural images, which is a completely different domain from that of medical imaging, which leads to poor performance due to domain shift. To overcome these problems, we propose a large-scale unlabeled dataset of medical images and a backbone pre-trained using the proposed dataset with a self-supervised learning technique called Masked autoencoder. This backbone can be used as a pre-trained model for any medical imaging task, as it is trained to learn a visual representation of different types of medical images. To evaluate the performance of the proposed backbone, we used four different medical imaging tasks. The results are compared with existing pre-trained models. These experiments show the superiority of our proposed backbone in medical imaging tasks.
Measuring Style Similarity in Diffusion Models
Apr 01, 2024



Generative models are now widely used by graphic designers and artists. Prior works have shown that these models remember and often replicate content from their training data during generation. Hence as their proliferation increases, it has become important to perform a database search to determine whether the properties of the image are attributable to specific training data, every time before a generated image is used for professional purposes. Existing tools for this purpose focus on retrieving images of similar semantic content. Meanwhile, many artists are concerned with style replication in text-to-image models. We present a framework for understanding and extracting style descriptors from images. Our framework comprises a new dataset curated using the insight that style is a subjective property of an image that captures complex yet meaningful interactions of factors including but not limited to colors, textures, shapes, etc. We also propose a method to extract style descriptors that can be used to attribute style of a generated image to the images used in the training dataset of a text-to-image model. We showcase promising results in various style retrieval tasks. We also quantitatively and qualitatively analyze style attribution and matching in the Stable Diffusion model. Code and artifacts are available at https://github.com/learn2phoenix/CSD.
PatchGame: Learning to Signal Mid-level Patches in Referential Games
Nov 02, 2021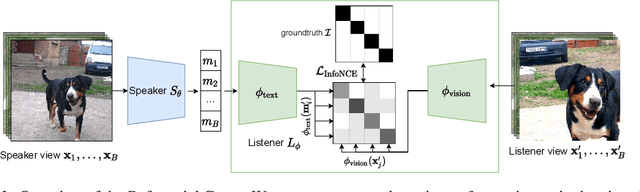
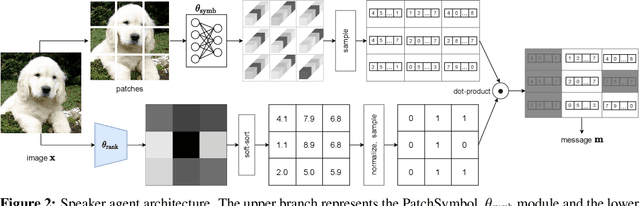


We study a referential game (a type of signaling game) where two agents communicate with each other via a discrete bottleneck to achieve a common goal. In our referential game, the goal of the speaker is to compose a message or a symbolic representation of "important" image patches, while the task for the listener is to match the speaker's message to a different view of the same image. We show that it is indeed possible for the two agents to develop a communication protocol without explicit or implicit supervision. We further investigate the developed protocol and show the applications in speeding up recent Vision Transformers by using only important patches, and as pre-training for downstream recognition tasks (e.g., classification). Code available at https://github.com/kampta/PatchGame.
Mining Points of Interest via Address Embeddings: An Unsupervised Approach
Sep 09, 2021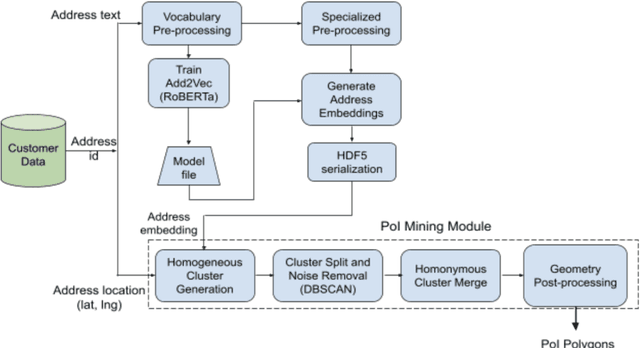

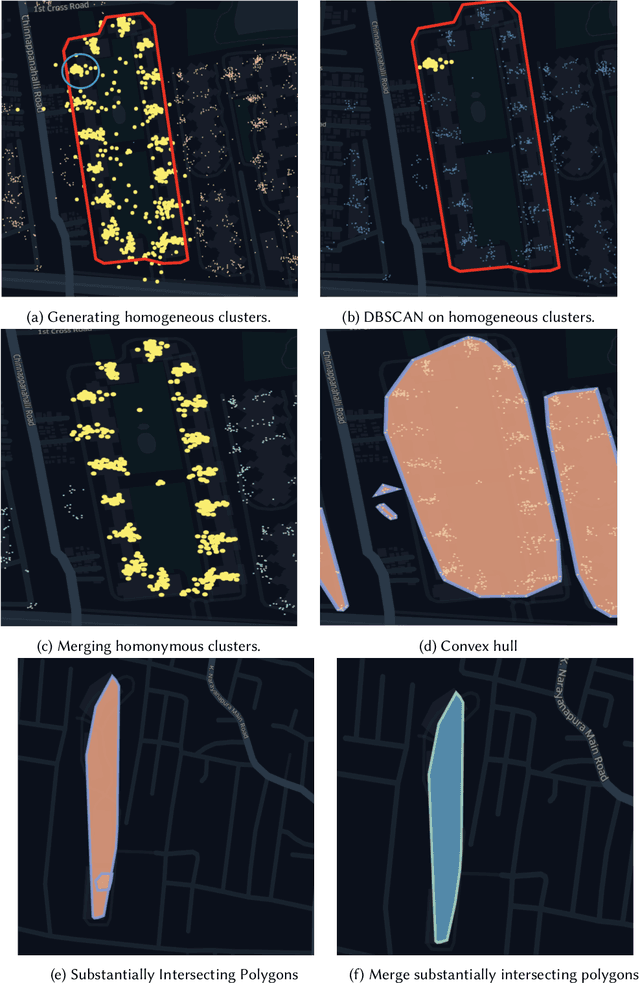
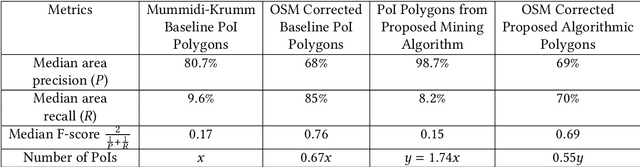
Digital maps are commonly used across the globe for exploring places that users are interested in, commonly referred to as points of interest (PoI). In online food delivery platforms, PoIs could represent any major private compounds where customers could order from such as hospitals, residential complexes, office complexes, educational institutes and hostels. In this work, we propose an end-to-end unsupervised system design for obtaining polygon representations of PoIs (PoI polygons) from address locations and address texts. We preprocess the address texts using locality names and generate embeddings for the address texts using a deep learning-based architecture, viz. RoBERTa, trained on our internal address dataset. The PoI candidates are identified by jointly clustering the anonymised customer phone GPS locations (obtained during address onboarding) and the embeddings of the address texts. The final list of PoI polygons is obtained from these PoI candidates using novel post-processing steps. This algorithm identified 74.8 % more PoIs than those obtained using the Mummidi-Krumm baseline algorithm run on our internal dataset. The proposed algorithm achieves a median area precision of 98 %, a median area recall of 8 %, and a median F-score of 0.15. In order to improve the recall of the algorithmic polygons, we post-process them using building footprint polygons from the OpenStreetMap (OSM) database. The post-processing algorithm involves reshaping the algorithmic polygon using intersecting polygons and closed private roads from the OSM database, and accounting for intersection with public roads on the OSM database. We achieve a median area recall of 70 %, a median area precision of 69 %, and a median F-score of 0.69 on these post-processed polygons.
Data Mining for Prediction of Human Performance Capability in the Software-Industry
Apr 08, 2015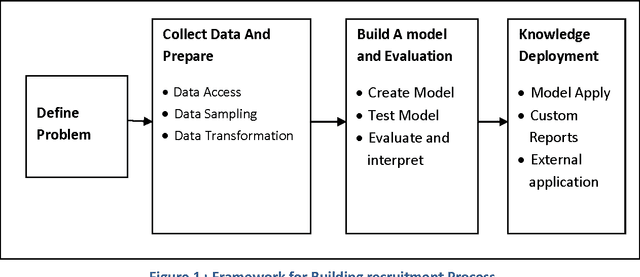


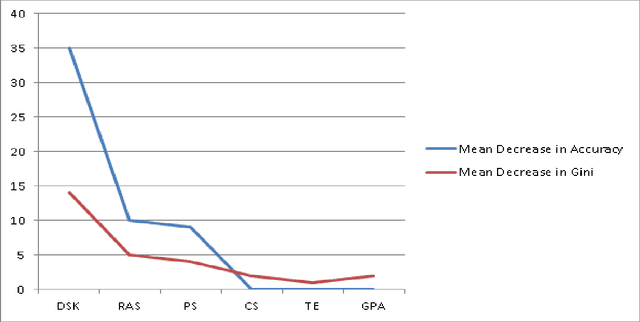
The recruitment of new personnel is one of the most essential business processes which affect the quality of human capital within any company. It is highly essential for the companies to ensure the recruitment of right talent to maintain a competitive edge over the others in the market. However IT companies often face a problem while recruiting new people for their ongoing projects due to lack of a proper framework that defines a criteria for the selection process. In this paper we aim to develop a framework that would allow any project manager to take the right decision for selecting new talent by correlating performance parameters with the other domain-specific attributes of the candidates. Also, another important motivation behind this project is to check the validity of the selection procedure often followed by various big companies in both public and private sectors which focus only on academic scores, GPA/grades of students from colleges and other academic backgrounds. We test if such a decision will produce optimal results in the industry or is there a need for change that offers a more holistic approach to recruitment of new talent in the software companies. The scope of this work extends beyond the IT domain and a similar procedure can be adopted to develop a recruitment framework in other fields as well. Data-mining techniques provide useful information from the historical projects depending on which the hiring-manager can make decisions for recruiting high-quality workforce. This study aims to bridge this hiatus by developing a data-mining framework based on an ensemble-learning technique to refocus on the criteria for personnel selection. The results from this research clearly demonstrated that there is a need to refocus on the selection-criteria for quality objectives.