 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEIA: Latent View-invariant Embeddings for Implicit 3D Articulation
Paper and Code
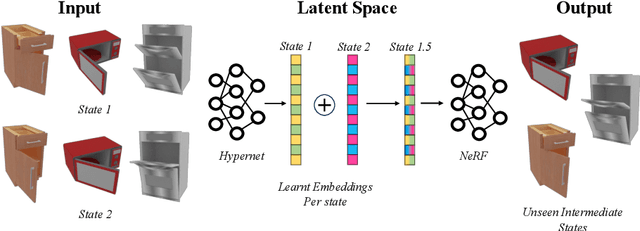
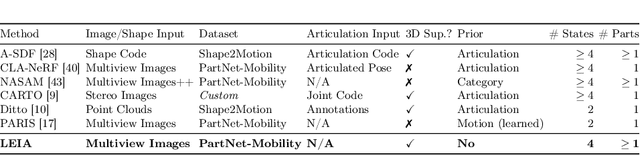
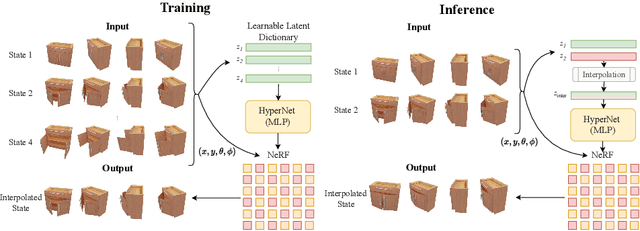

Neural Radiance Fields (NeRFs) have revolutionized the reconstruction of static scenes and objects in 3D, offering unprecedented quality. However, extending NeRFs to model dynamic objects or object articulations remains a challenging problem. Previous works have tackled this issue by focusing on part-level reconstruction and motion estimation for objects, but they often rely on heuristics regarding the number of moving parts or object categories, which can limit their practical use. In this work, we introduce LEIA, a novel approach for representing dynamic 3D objects. Our method involves observing the object at distinct time steps or "states" and conditioning a hypernetwork on the current state, using this to parameterize our NeRF. This approach allows us to learn a view-invariant latent representation for each state. We further demonstrate that by interpolating between these states, we can generate novel articulation configurations in 3D space that were previously unseen. Our experimental results highlight the effectiveness of our method in articulating objects in a manner that is independent of the viewing angle and joint configuration. Notably, our approach outperforms previous methods that rely on motion information for articulation registration.