 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMOU: A Massive Multi-Task Omni Understanding and Reasoning Benchmark for Long and Complex Real-World Videos
Mar 14, 2026Multimodal Large Language Models (MLLMs) have shown strong performance in visual and audio understanding when evaluated in isolation. However, their ability to jointly reason over omni-modal (visual, audio, and textual) signals in long and complex videos remains largely unexplored. We introduce MMOU, a new benchmark designed to systematically evaluate multimodal understanding and reasoning under these challenging, real-world conditions. MMOU consists of 15,000 carefully curated questions paired with 9038 web-collected videos of varying length, spanning diverse domains and exhibiting rich, tightly coupled audio-visual content. The benchmark covers 13 fundamental skill categories, all of which require integrating evidence across modalities and time. All questions are manually annotated across multiple turns by professional annotators, ensuring high quality and reasoning fidelity. We evaluate 20+ state-of-the-art open-source and proprietary multimodal models on MMOU. The results expose substantial performance gaps: the best closed-source model achieves only 64.2% accuracy, while the strongest open-source model reaches just 46.8%. Our results highlight the challenges of long-form omni-modal understanding, revealing that current models frequently fail to apply even fundamental skills in long videos. Through detailed analysis, we further identify systematic failure modes and provide insights into where and why current models break.
Towards Multimodal Understanding via Stable Diffusion as a Task-Aware Feature Extractor
Jul 09, 2025Recent advances in multimodal large language models (MLLMs) have enabled image-based question-answering capabilities. However, a key limitation is the use of CLIP as the visual encoder; while it can capture coarse global information, it often can miss fine-grained details that are relevant to the input query. To address these shortcomings, this work studies whether pre-trained text-to-image diffusion models can serve as instruction-aware visual encoders. Through an analysis of their internal representations, we find diffusion features are both rich in semantics and can encode strong image-text alignment. Moreover, we find that we can leverage text conditioning to focus the model on regions relevant to the input question. We then investigate how to align these features with large language models and uncover a leakage phenomenon, where the LLM can inadvertently recover information from the original diffusion prompt. We analyze the causes of this leakage and propose a mitigation strategy. Based on these insights, we explore a simple fusion strategy that utilizes both CLIP and conditional diffusion features. We evaluate our approach on both general VQA and specialized MLLM benchmarks, demonstrating the promise of diffusion models for visual understanding, particularly in vision-centric tasks that require spatial and compositional reasoning. Our project page can be found https://vatsalag99.github.io/mustafar/.
LEIA: Latent View-invariant Embeddings for Implicit 3D Articulation
Sep 10, 2024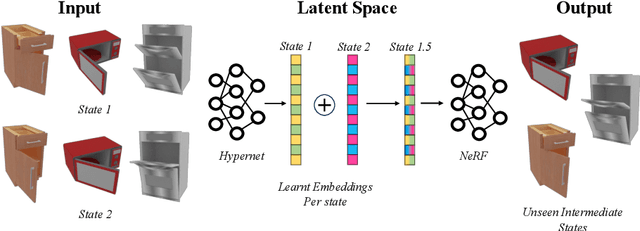
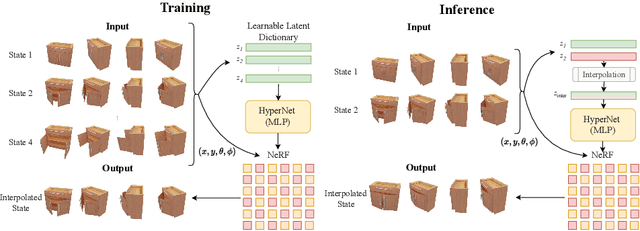

Neural Radiance Fields (NeRFs) have revolutionized the reconstruction of static scenes and objects in 3D, offering unprecedented quality. However, extending NeRFs to model dynamic objects or object articulations remains a challenging problem. Previous works have tackled this issue by focusing on part-level reconstruction and motion estimation for objects, but they often rely on heuristics regarding the number of moving parts or object categories, which can limit their practical use. In this work, we introduce LEIA, a novel approach for representing dynamic 3D objects. Our method involves observing the object at distinct time steps or "states" and conditioning a hypernetwork on the current state, using this to parameterize our NeRF. This approach allows us to learn a view-invariant latent representation for each state. We further demonstrate that by interpolating between these states, we can generate novel articulation configurations in 3D space that were previously unseen. Our experimental results highlight the effectiveness of our method in articulating objects in a manner that is independent of the viewing angle and joint configuration. Notably, our approach outperforms previous methods that rely on motion information for articulation registration.
Do text-free diffusion models learn discriminative visual representations?
Nov 30, 2023



While many unsupervised learning models focus on one family of tasks, either generative or discriminative, we explore the possibility of a unified representation learner: a model which addresses both families of tasks simultaneously. We identify diffusion models, a state-of-the-art method for generative tasks, as a prime candidate. Such models involve training a U-Net to iteratively predict and remove noise, and the resulting model can synthesize high-fidelity, diverse, novel images. We find that the intermediate feature maps of the U-Net are diverse, discriminative feature representations. We propose a novel attention mechanism for pooling feature maps and further leverage this mechanism as DifFormer, a transformer feature fusion of features from different diffusion U-Net blocks and noise steps. We also develop DifFeed, a novel feedback mechanism tailored to diffusion. We find that diffusion models are better than GANs, and, with our fusion and feedback mechanisms, can compete with state-of-the-art unsupervised image representation learning methods for discriminative tasks - image classification with full and semi-supervision, transfer for fine-grained classification, object detection and segmentation, and semantic segmentation. Our project website (https://mgwillia.github.io/diffssl/) and code (https://github.com/soumik-kanad/diffssl) are available publicly.
Diffusion Models Beat GANs on Image Classification
Jul 17, 2023



While many unsupervised learning models focus on one family of tasks, either generative or discriminative, we explore the possibility of a unified representation learner: a model which uses a single pre-training stage to address both families of tasks simultaneously. We identify diffusion models as a prime candidate. Diffusion models have risen to prominence as a state-of-the-art method for image generation, denoising, inpainting, super-resolution, manipulation, etc. Such models involve training a U-Net to iteratively predict and remove noise, and the resulting model can synthesize high fidelity, diverse, novel images. The U-Net architecture, as a convolution-based architecture, generates a diverse set of feature representations in the form of intermediate feature maps. We present our findings that these embeddings are useful beyond the noise prediction task, as they contain discriminative information and can also be leveraged for classification. We explore optimal methods for extracting and using these embeddings for classification tasks, demonstrating promising results on the ImageNet classification task. We find that with careful feature selection and pooling, diffusion models outperform comparable generative-discriminative methods such as BigBiGAN for classification tasks. We investigate diffusion models in the transfer learning regime, examining their performance on several fine-grained visual classification datasets. We compare these embeddings to those generated by competing architectures and pre-trainings for classification tasks.
A Frequency Perspective of Adversarial Robustness
Oct 26, 2021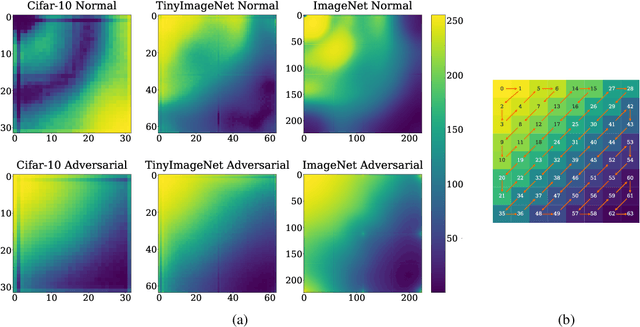
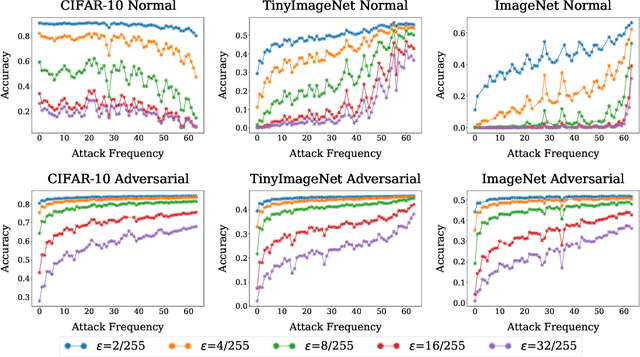

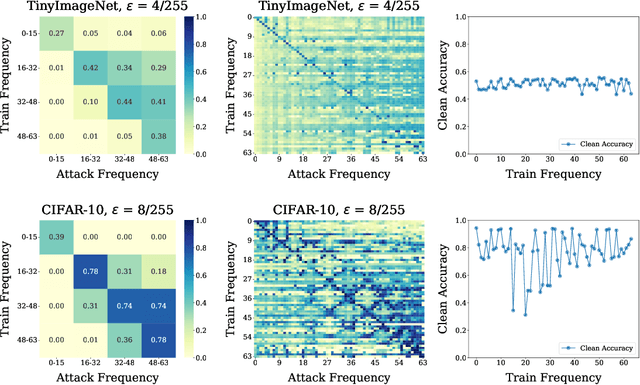
Adversarial examples pose a unique challenge for deep learning systems. Despite recent advances in both attacks and defenses, there is still a lack of clarity and consensus in the community about the true nature and underlying properties of adversarial examples. A deep understanding of these examples can provide new insights towards the development of more effective attacks and defenses. Driven by the common misconception that adversarial examples are high-frequency noise, we present a frequency-based understanding of adversarial examples, supported by theoretical and empirical findings. Our analysis shows that adversarial examples are neither in high-frequency nor in low-frequency components, but are simply dataset dependent. Particularly, we highlight the glaring disparities between models trained on CIFAR-10 and ImageNet-derived datasets. Utilizing this framework, we analyze many intriguing properties of training robust models with frequency constraints, and propose a frequency-based explanation for the commonly observed accuracy vs. robustness trade-off.
Weakly Supervised Lesion Co-segmentation on CT Scans
Jan 24, 2020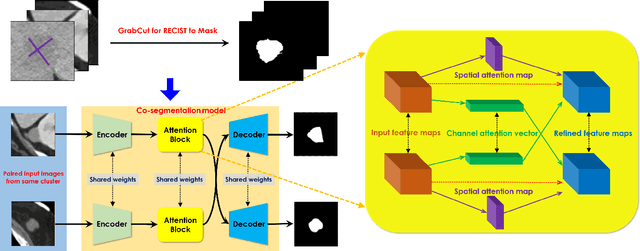



Lesion segmentation in medical imaging serves as an effective tool for assessing tumor sizes and monitoring changes in growth. However, not only is manual lesion segmentation time-consuming, but it is also expensive and requires expert radiologist knowledge. Therefore many hospitals rely on a loose substitute called response evaluation criteria in solid tumors (RECIST). Although these annotations are far from precise, they are widely used throughout hospitals and are found in their picture archiving and communication systems (PACS). Therefore, these annotations have the potential to serve as a robust yet challenging means of weak supervision for training full lesion segmentation models. In this work, we propose a weakly-supervised co-segmentation model that first generates pseudo-masks from the RECIST slices and uses these as training labels for an attention-based convolutional neural network capable of segmenting common lesions from a pair of CT scans. To validate and test the model, we utilize the DeepLesion dataset, an extensive CT-scan lesion dataset that contains 32,735 PACS bookmarked images. Extensive experimental results demonstrate the efficacy of our co-segmentation approach for lesion segmentation with a mean Dice coefficient of 90.3%.
Weakly-Supervised Lesion Segmentation on CT Scans using Co-Segmentation
Jan 23, 2020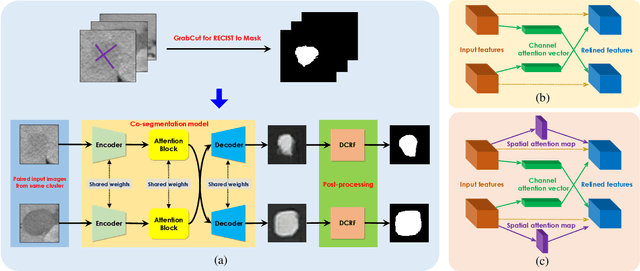
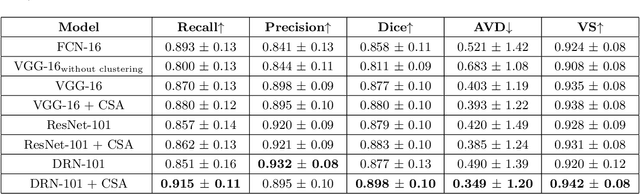

Lesion segmentation on computed tomography (CT) scans is an important step for precisely monitoring changes in lesion/tumor growth. This task, however, is very challenging since manual segmentation is prohibitively time-consuming, expensive, and requires professional knowledge. Current practices rely on an imprecise substitute called response evaluation criteria in solid tumors (RECIST). Although these markers lack detailed information about the lesion regions, they are commonly found in hospitals' picture archiving and communication systems (PACS). Thus, these markers have the potential to serve as a powerful source of weak-supervision for 2D lesion segmentation. To approach this problem, this paper proposes a convolutional neural network (CNN) based weakly-supervised lesion segmentation method, which first generates the initial lesion masks from the RECIST measurements and then utilizes co-segmentation to leverage lesion similarities and refine the initial masks. In this work, an attention-based co-segmentation model is adopted due to its ability to learn more discriminative features from a pair of images. Experimental results on the NIH DeepLesion dataset demonstrate that the proposed co-segmentation approach significantly improves lesion segmentation performance, e.g the Dice score increases about 4.0% (from 85.8% to 89.8%).